Ultimate Guide on How to Use Screaming Frog SEO Spider For Beginners [2025]


Screaming frog SEO Spider is a website SEO audit tool. We've compiled a comprehensive list of best practices on how SEOs, PPCs, and digital marketers can use Screaming Frog to streamline their workflow.
This is the Ultimate Beginner's Screaming Frog Guide prepared with the latest updates. On Collaborator, you will also find an SEO best practices Checklist which will come in useful if you want to do a website audit yourself.
The new 21.4 version, which includes a small update to the SEO Spider, was released on February 5, 2025.
What is Screaming Frog?
Screaming Frog is a crawler tool that scans the URLs of websites in order to gather the data you need to know to improve your site’s SEO performance. Whether it is an internal link audit or creating an XML Sitemap, you'll do it faster with this tool. It also monitors sites for common SEO errors including bad content type, duplicate pages, missing metadata, and so on. This software has a user-friendly graphic interface and can be accessed via a command line interface when needed.
The lite version of Screaming Frog is available for free and can crawl up to 500 URLs. If you buy a license, this limit will be removed and you will get a number of advanced features such as JavaScript rendering, custom robots, spelling & grammar checks, custom extraction, Google Analytics & Search Console integration, and many others.
When we wrote the instructions, we analyzed what most users are looking for in this program:
- Screaming Frog how to download for free
- What does Screaming Frog do?
- What is Screaming Frog SEO Spider and what is it used for?
- How to run a full site scraping in Screaming Frog SEO?
- How to use Screaming Frog to improve on page SEO?
- How to do a technical audit of the site using Screaming Frog SEO?
- How to use the Screaming Frog SEO Spider tool to check internal and backlinks?
- What about the Screaming Frog pricing and is it free to use?
These and many other questions will be answered in our Screaming Frog tutorial. We provide step-by-step instructions with explanations and visuals to show you how to use Screaming Frog for SEO effectively. 💪
How to run a full website scraping in Screaming Frog SEO
How to crawl the full site
Before launching the full web scraping process in Screaming Frog SEO, determine:
- what information do you want to get,
- how big the site is,
- what part of the site do you need to check for completeness.
In the case of large sites, it is better to limit the analyzed area to a subsection of URLs in order to get a representative sample of the data. This keeps file sizes and export data more manageable. We will return to these details later.
To fully scrape the site with all subdomains, you will need to change the settings a bit before starting. This is because by default Screaming Frog checks only the subdomains you have entered. Other additional ones will be treated as external links by the algorithm. To check additional subdomains, you need to change the settings in the Screaming Frog Configuration menu. By selecting Spider > Crawl all Subdomains, you will ensure that the algorithm crawls any links to subdomains of your site.
Step 1 - Configuring Domain and Subdomain Scraping
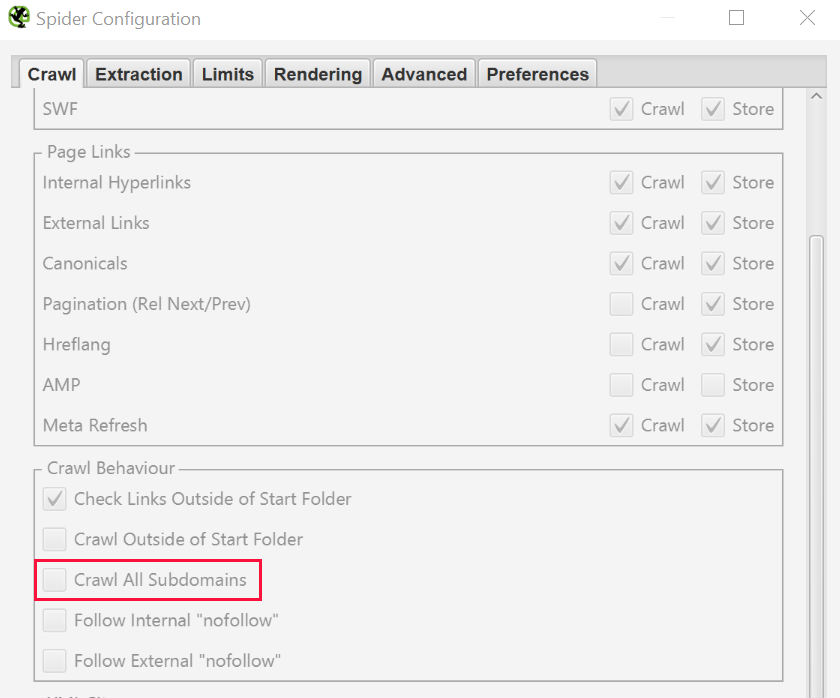
Step 2 - configuring the whole site crawl
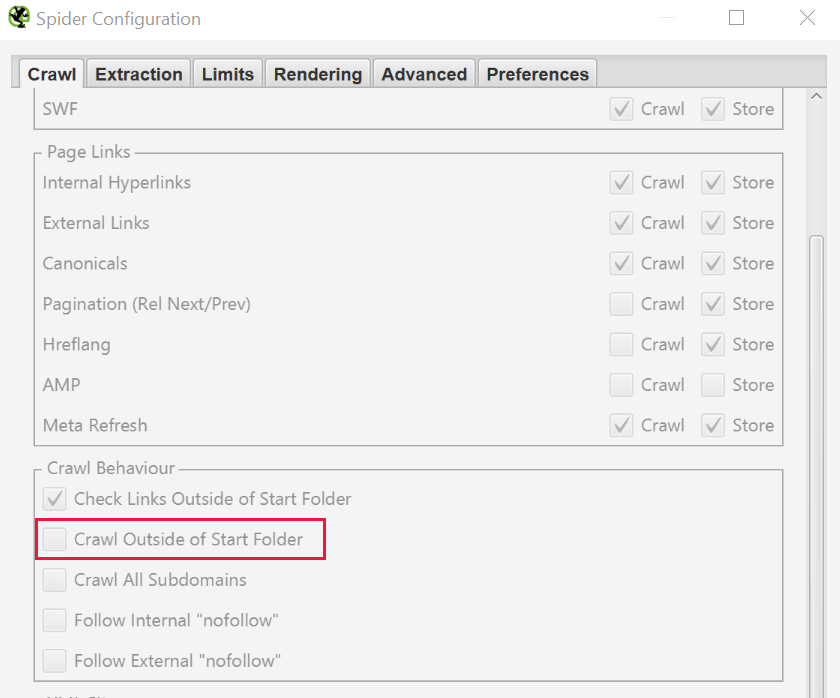
If you started crawling from a specific subfolder and still want Screaming Frog to crawl the whole site check «Crawl Outside of Start Folder».
Pro Tip — Exclude image, CSS, and Javascript crawling
To disable crawling of images, CSS, and Javascript files in Screaming Frog uncheck the items you don't need. This will save time and disk space (reduce the size of scanned files).
How to set up Screaming Frog to crawl a single folder
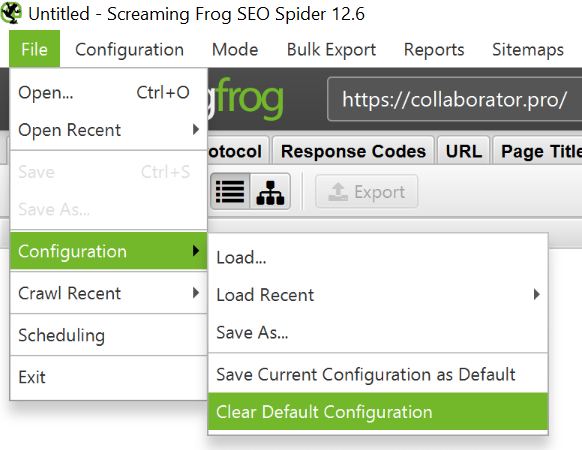
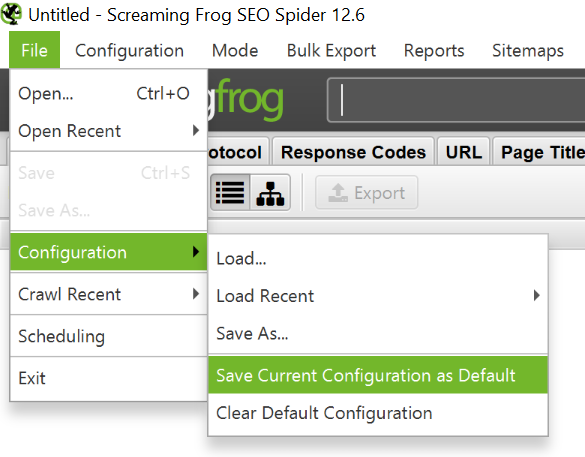
To restrict the Screaming Frog Seo Spider to a single folder just enter the URL and hit start without changing any of the default settings. If you have overwritten the initial settings, reset the default configurations in File > Configuration > Clear Default Configuration. See instructions below.
If you want to start crawling in a specific folder, but continue in the remaining subdomain, select «Crawl outside of start folder» from the Configuration menu before entering the start URL. This screenshot will help you understand the settings.
How to check subdomains and subdirectories: customizing Screaming Frog
To restrict the Screaming Frog check to a specific set of subdomains or subdirectories, you can use RegEx to set these rules in the Include or Exclude settings in the Configuration menu.
Exception
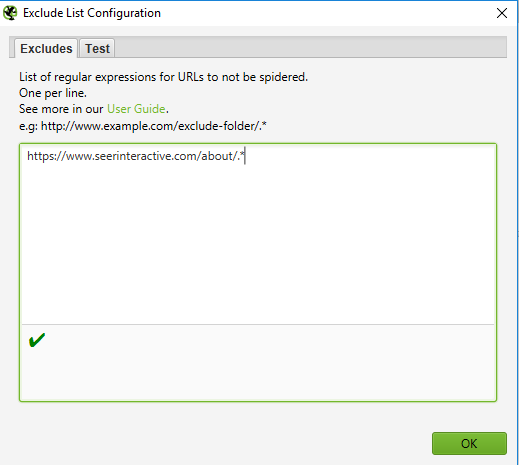
In this example, we have crawled every page on seerinteractive.com, excluding the "About" page in each subdomain.
Step 1 — write the exclusion rules
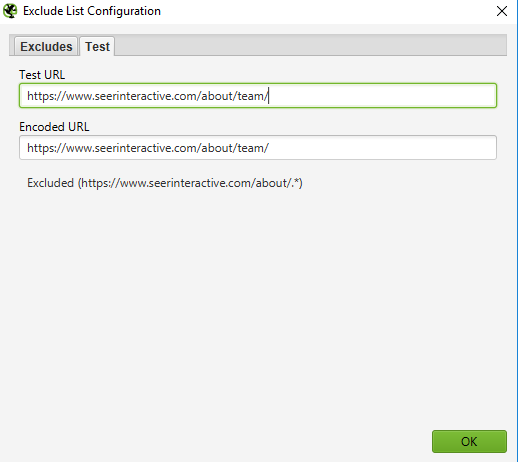
Open Configuration > Exclude; use a wildcard expression to exclude parameters or URLs.
Step 2 — Testing how the exclusion will work
Test the expression to make sure there are pages that should be excluded before starting the test.
Inclusion
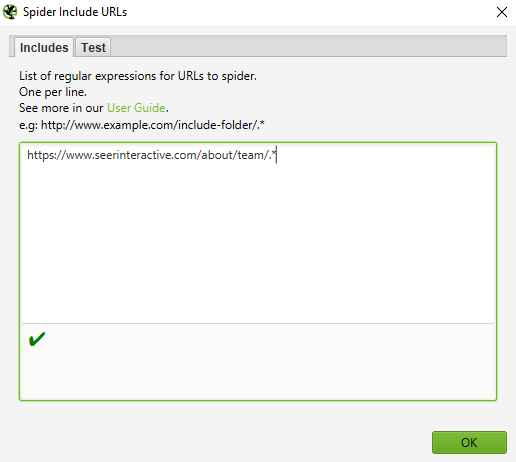
In the example below, we wanted to crawl a command subfolder on seerinteractive.com. Use the Test tab to test multiple URLs to make sure the RegEx for the sub-rule is set correctly.
This is a great way to test large sites. In addition, Screaming Frog recommended this method if you need to split and validate a large domain.
How to collect all pages on a site
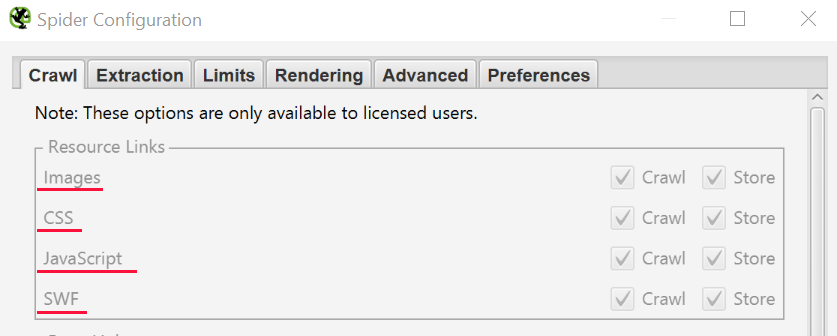
By default Screaming Frog checks all images, JavaScript, CSS, and flash files.
To collect all the pages of the site (HTML only) in Screaming Frog uncheck «Check Images», «Check CSS», «Check JavaScript» and «Check SWF» in the Configuration menu.
When you disable the above options, Screaming Frog Seo Spider will collect all the pages on the site with internal links to them.
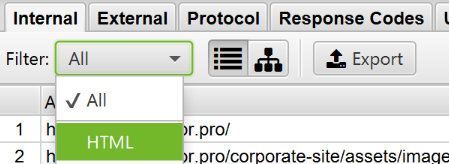
Once the crawl is complete, select the «Internal» tab and filter the results by «HTML». Click «Export» and you will have a complete list of pages in CSV format. See instructions on how to use this feature.
Pro Tip — Save the Screaming Frog settings you use for each check
How to list all pages in a separate subdirectory
In addition to resetting «Check CSS», «Check CSS», «Check JavaScript», and «Check SWF», you can also reset «Check links outside folder» in settings. If you disable these settings and crawl, you will additionally get a list of all pages in the start folder.
How to Find All Subdomains on a Website Using Screaming Frog and Check External Links
There are several ways to find all subdomains on a website.
Method 1: use Screaming Frog to get all subdomains on the specified site.
Go to Configuration > Spider and make sure the «Crawl all Subdomains» option is selected. This will help check any related subdomain during the crawl. Note that unlinked subdomains will not be found.
Method 2: use Google to find all indexed subdomains.
Using the Scraper Chrome extension and advanced search operators, you can find all indexed subdomains for a given domain.
Step 1 — using the site and inurl operators
Start by using the site search operator: in Google to limit your results to a specific domain. Then use the -inurl search operator to narrow your search results by removing the main domain. After that, you will start to see a list of Google-indexed subdomains that do not contain the main domain.
Step 2 — use the Scraper extension
Use the Scraper extension to extract results into a Google spreadsheet. To do this, right-click on the link in the SERP, select «Scrape similar» and export to a Google Doc.
Step 3 — remove extra data
In Google Docs use the following function to trim URLs in a subdomain:
=LEFT(A2,SEARCH("/",A2,9))This guide will help you remove any subdirectory, page or filename at the end of your site. The function tells the sheets or Excel to return whatever is to the left of the slash. The leading number 9 is significant because we are asking to start looking for a slash after the 9th character. This is taken into account for the https:// protocol with a length of 8 characters.
Remove duplicates from the list and load it into Screaming Frog in list mode.
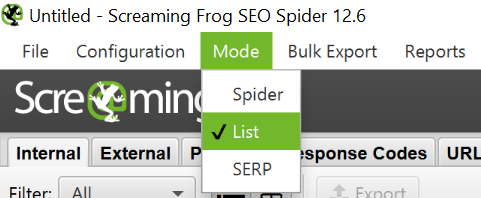
You can insert a list of domains manually, use a function or upload a CSV file.
Method 3: find subdomains in Screaming Frog
Enter the domain's root URL into the tools, which will help you find sites on the same IP address. Alternatively, use dedicated search engines such as FindSubdomains. Create a free account to login and export the list of subdomains. Then upload the list to Screaming Frog using list mode.
Upon completion of the crawl, you will be able to see the status codes, as well as any links to subdomain home pages, anchor texts and duplicate page titles etc.
How to analyze an online store and other large sites using Screaming Frog Spider
What you need for scraping large sites using Screaming Frog Spider:
- you can increase the memory allocation.
- split the check into subdirectories or check only specific parts of the site using the Include/Exclude settings.
- you can choose not to select images, JavaScript, CSS and flash files. By deselecting these options in the Screaming Frog Seo Spider settings, you save memory for crawling HTML only.
Pro Tip — pause crawling when necessary
Until quite recently, Screaming Frog SEO Spider could pause or crash crawling on a large site. Now, with default database storage, you can pick up the crawl where you left off. In addition, you have access to a queue of URLs in case you want to exclude or add additional parameters to test a large site.

How to check a site that is stored on an old server
In some cases, old servers may not be able to process a certain number of requests per second by default. By the way, we recommend setting this limit in order to respect server etiquette. It's best to let the client know when you plan to check the site against unknown user agents. In this case, they may whitelist your IP before you start crawling the site. Otherwise, you will send too many requests to the server and accidentally crash the site.
To change the crawl speed, open Configuration > Speed and in the pop-up window select the maximum number of threads that should run simultaneously. In this menu, you can also select the maximum number of URL requests per second.
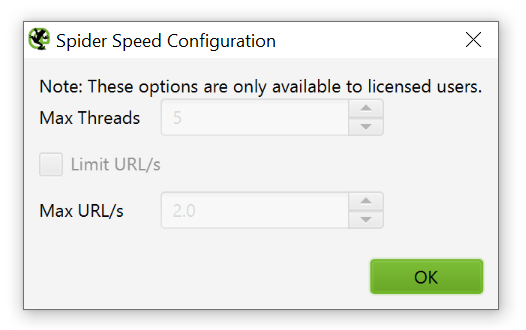
Pro Tip — increase Response Timeout in settings
If the crawl result gives a lot of server errors, go to Configuration > Spider > Advanced in settings and increase «Response Timeout» and «5xx Response Retries» to get better results.
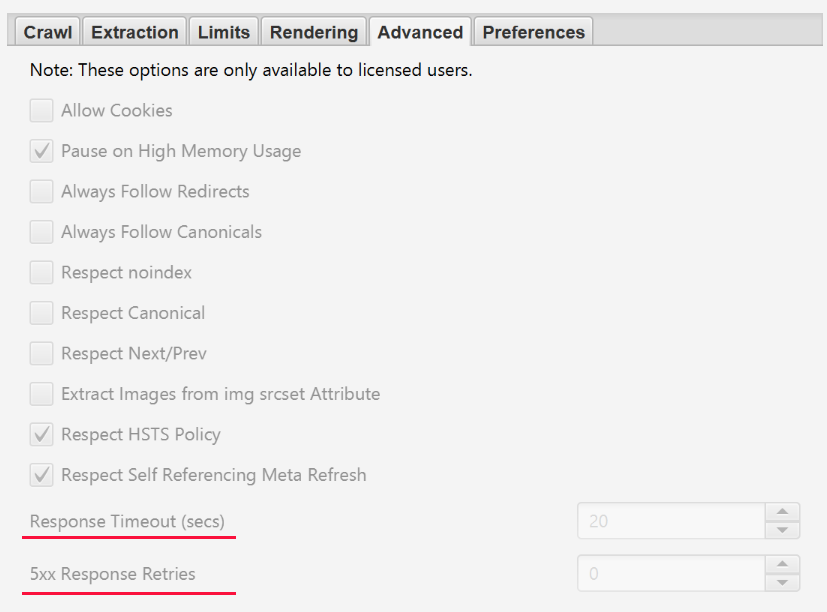
How to analyze a site that requires cookies
Screaming Frog Seo Spider allows you to crawl sites that require cookies. Although search bots don't accept cookies, if you're crawling a site and need to allow them, just go to Configuration > Spider > Advanced and select «Allow Cookies».
Can Screaming Frog check pages that require authentication?
Yes, you can manage authentication in the Screaming Frog settings. When the Screaming Frog algorithm encounters a password-protected page, a pop-up window will appear where you can enter the required username and password.
Forms-based authentication is a powerful feature that may require JavaScript to work effectively.
Note that forms-based authentication should be used infrequently and only by advanced users. The algorithm is programmed so that it clicks on every link on the page. So this could potentially affect links that create posts or even delete data.
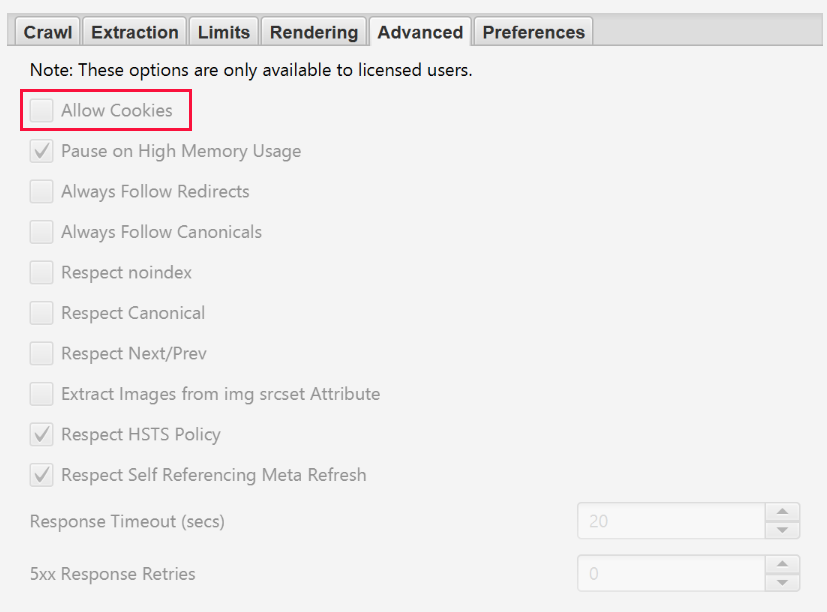
To manage authentication, go to Configuration > Authentication.
To turn off authentication requests go to Configuration > Authentication and uncheck «Standards Based Authentication».
Search for internal and external links in Screaming Frog
How to get information about all internal and external links on the site
If you do not need information about JavaScript, CSS and flash files, disable these options in the settings menu to save processing time and memory.
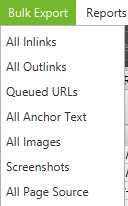
Once the algorithm has finished crawling, use «All links» in the Bulk Export menu to export the CSV. You will learn about the location of all links along with the corresponding anchor texts, directives etc.
All links can be a big report. Keep this in mind when exporting. For large sites the export may take time.
To quickly count the number of links on each page open the «Internal» tab and filter by «Outlinks». Anything above 100 may need to be revised.

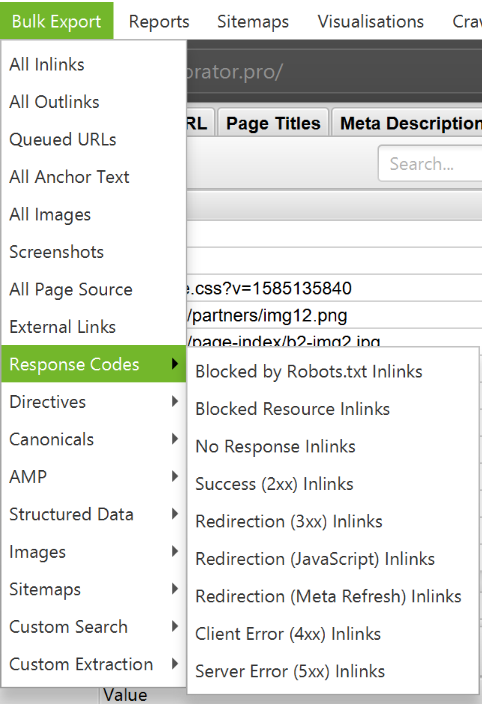
How to find broken links in Screaming Frog (page or website)
Screaming Frog Seo Spider can also serve as a broken link checker. Once the algorithm has finished checking, filter the results in the «Internal» tab by «Status Code». All 404, 301 and other status pages will be shown.
By clicking on any individual URL as a result of the check, you will see the information change at the bottom of the program window. By clicking on the «In Links» tab at the bottom of the window, you will find a list of pages that are linked to the selected URLs, along with the anchor text and directives used on those links. You can use this feature to monitor pages where internal links need to be updated.
To export a complete list of pages with broken or redirected links, go to Bulk Export > Response Codes and select «Redirection (3xx) In Links», «Client Error (4xx) In Links», or «Server Error (5xx) In Links». This way you will get the exported data in a CSV file.
To export a complete list of broken pages, open the Bulk Export menu. Scroll down to the response codes and look at the following reports:
- no response inlinks;
- redirection (3xx) inlinks;
- Redirection (JavaScript) inlinks;
- redirection (meta refresh) inlinks;
- client error (4xx) inlinks;
- server error (5xx) inlinks.
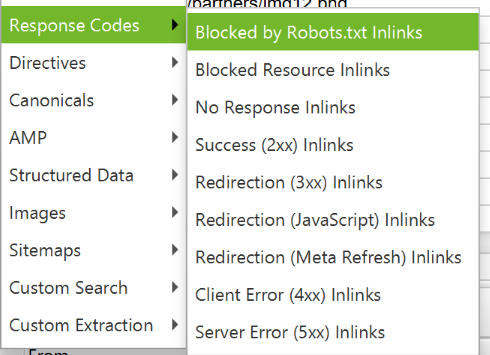
Screaming Frog Seo Spider finds all broken links on the site. Looking at these reports should give you an idea of which internal links need to be updated. This will ensure that they point to the canonical version of the URL and are distributed efficiently.
How to use Screaming Frog SEO Spider to check outbound links
Screaming Frog SEO Spider allows find external links from the site you are checking.
Make sure the «Check External Links» option is checked in Configuration > Spider.
After the algorithm has finished checking, go to the «External» tab in the top window. Then filter the data by «Status Code» and you will see URLs with all codes except 200. By clicking on a specific URL in the search result and then on the «In Links» tab at the bottom of the window, you will find a list of pages that indicate the selected URL. You can use this feature to identify pages that need to update outbound links.
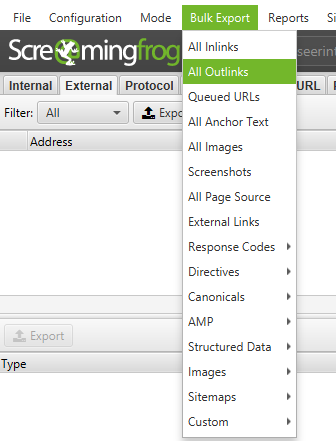
To export a complete list of outgoing links, go to Bulk Export > External Links.

For a complete list of all locations and anchor texts for outbound links, Bulk Export > All Outlinks. This report also contains outgoing links to your subdomain. If you want to exclude your domain, refer to the «External Links» report above.
How to find redirected links
After the algorithm has finished checking, select the «Response Codes» tab in the main interface and sort by Status Code. Because Screaming Frog uses regular expressions to search, validate the following filter criteria: 301|302|307. This should give you a fairly large list of all the links that came back with a certain type of redirect.
It will also let you know if the content has been permanently moved, found or redirected, or temporarily redirected according to the HSTS settings (most likely caused by the 307 redirect in Screaming Frog). Sort by «Status Code» and you can split the results by type. Click on the «In Links» tab at the bottom of the window to see all pages that have redirected links.
If you export directly from this tab, you will only see the data shown at the top of the window (original URL, code status, and where the redirect went).
To export the full list of pages with redirected links, go to Bulk Export > Response Codes and select «Redirection (3xx) In Links». You will receive a CSV file containing the location of all redirected links. To display only the internal redirect, filter the «Destination» column in the CSV to include only your domain.
Pro Tip — Use VLOOKUP between the two exported files above to connect the Source and Destination columns to the location of the final URL.
For example:
=VLOOKUP([@Destination],'response_codes_redirection_(3xx).csv'!$A$3:$F$50,6, FALSE)
(Where 'response_codes_redirection_(3xx).csv' is the CSV file that contains the redirect links, and '50' is the number of lines in this file)
Using SEO Spider for internal linking
Internal linking can bring good ROI (return on investment), especially when you have a PageRank distribution strategy, keyword rankings and keywords containing anchor texts.
How to view Screaming Frog link position, path type and target
Screaming Frog SEO Spider v.13 records some new attributes for each link.
To see the position of each link in a crawl, such as navigation, page content, sidebar or footer, look at the crawl results. The classification is done using the path of each link (like XPath) and the known semantic substrings, which can be seen in the «Inlinks» and «Outlinks» tabs.
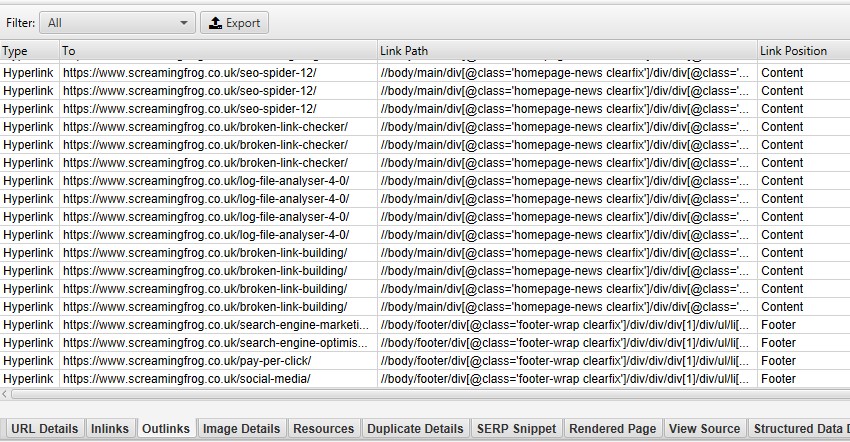
If your site uses HTML5 semantic elements (or well-named non-semantic elements like div id="nav"), SEO Spider will be able to automatically detect the different parts of the web page and the links within them.

But not every website is built this way, so you can customize the classification of link positions in Config > Custom > Link positions. This allows you to substring the path of the link to classify it however you want.
For example, we have mobile menu links outside of the nav element that are defined as content links. This is not true, as they are additional mobile phone navigation.
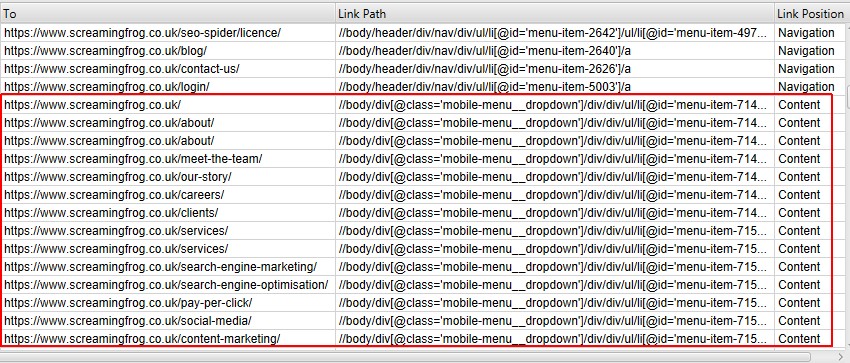
The class name «mobile-menu__dropdown» (which is in the link path as shown above) can be used to determine the correct position of the link using the «Links Positions» function. See below how to properly configure the Screaming Frog Seo Spider program.

These links will then be properly classified as navigation links.
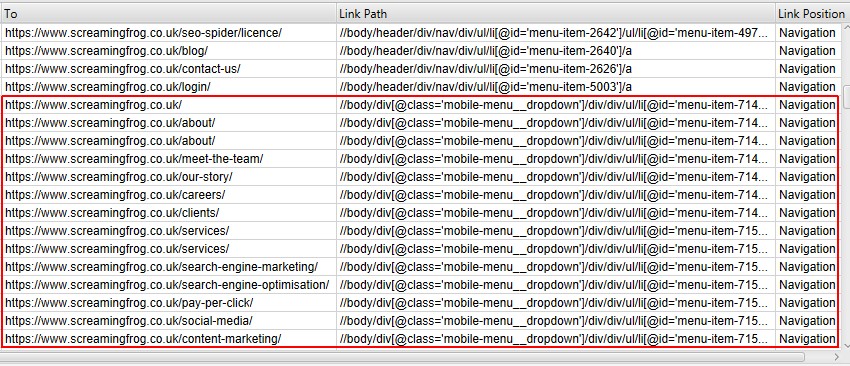
This can help identify incoming links to a page only from the content, for example ignoring any links in the main navigation or footer for better analysis of internal links.
How to find out absolute and relative links
Screaming Frog allows you to find out the path type of a link (absolute, relative, protocol, or root). It can be seen in links, outbound links, and all bulk exports.
This can help identify incoming links to a page only from the content, for example ignoring any links in the main navigation or footer for better analysis of internal links.
How to find out absolute and relative links
Screaming Frog allows you to find out the path type of a link (absolute, relative, protocol, or root). It can be seen in links, outbound links, and all bulk exports.
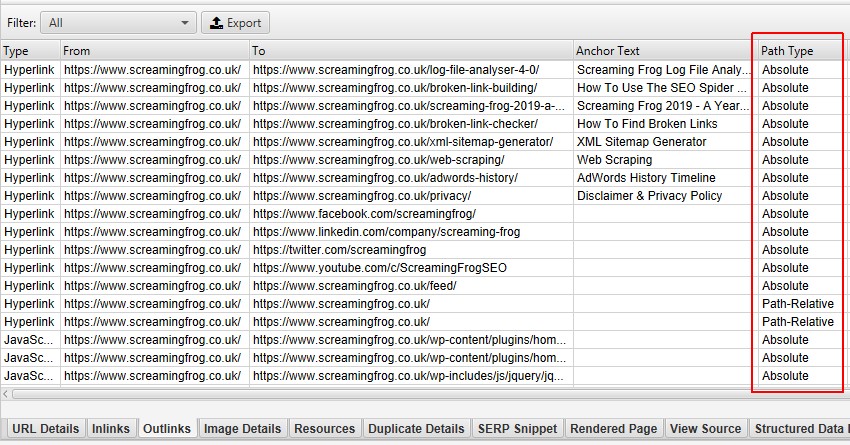
This can help identify links that should be absolute, as there are integrity, security, and performance issues under some circumstances. You can sort and export only absolute links.
Link Target Attribute
In addition, you can now look at the «target» attribute to detect links that use «_blank» to open in a new tab.
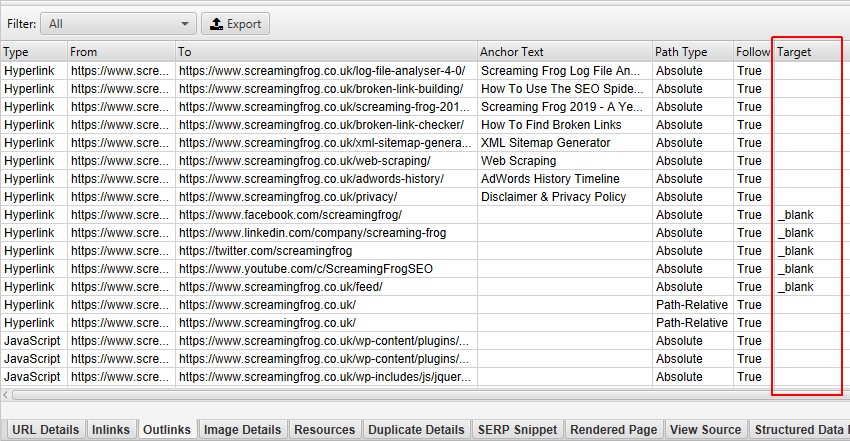
This is useful when analyzing usability as well as performance and security, which brings us to the next feature.
Checking website content with Screaming Frog
How to find low content pages
Screaming Frog allows you to view pages with little or no content. Instructions:
- After the algorithm has finished checking, open the «Internal» tab, sort by HTML and scroll right to the «Word Count» column.
- Sort the «Word count» column from smallest to largest to find pages with the low text content. You can drag the «Word Count» column to the left to better understand which pages are related to a certain number.
- Click «Export» in the «Internal» tab if you prefer to work with data in CSV format.
The above word count method determines the amount of actual text on a page. But there's no way to be specific — it's a product name or a keyword-optimized text block.
Pro Tips for E-commerce Sites. To determine the word count of text blocks, use ImportXML2 to separate text blocks in any page list when counting characters from there. If xPath queries are not your forte, then the xPath Helper or Xpather Chrome extensions will do the solid job of determining xPath for you.
How to find duplicate content on a site
To find duplicate content, you need to go to the «Content» tab, which contains filters for «Near Duplicates» and «Exact Duplicates».
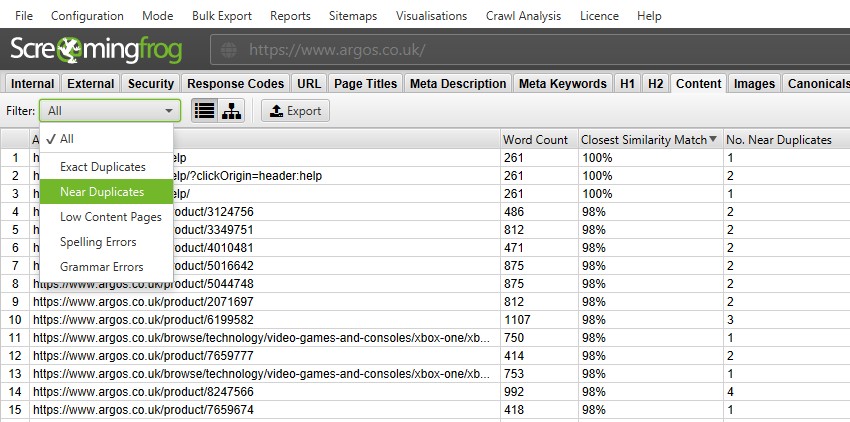
While there are no duplicate content penalties, having similar pages can cause crawling and indexing inefficiencies. Similar pages should be kept to a minimum, since high similarity is a sign of low-quality pages.
How to view content matching percentage
For «Near Duplicates», SEO Spider will show you the closest matching percentage as well as non-obvious duplicates for each URL. The «Exact Duplicates» filter uses the same algorithmic check to identify identical pages that were previously named «Duplicate» in the «URL» tab.
The new «Near Duplicates» tab uses the minhash algorithm, which allows you to set up a nearly identical threshold, which is set to 90% by default. This can be configured via Config > Content > Duplicates.
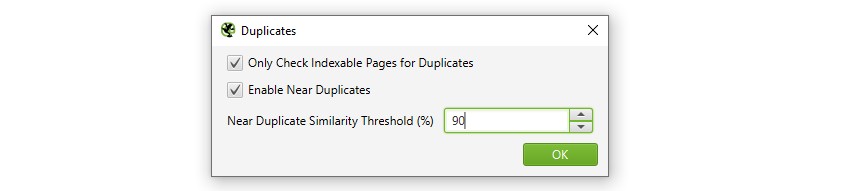
Semantic elements such as navigation and footer are automatically excluded from content checking, but you can refine it by excluding or including HTML elements, classes, and IDs. This can help focus the analysis on the main content area, avoiding well-known template text. It can also be used to provide more accurate word counts.
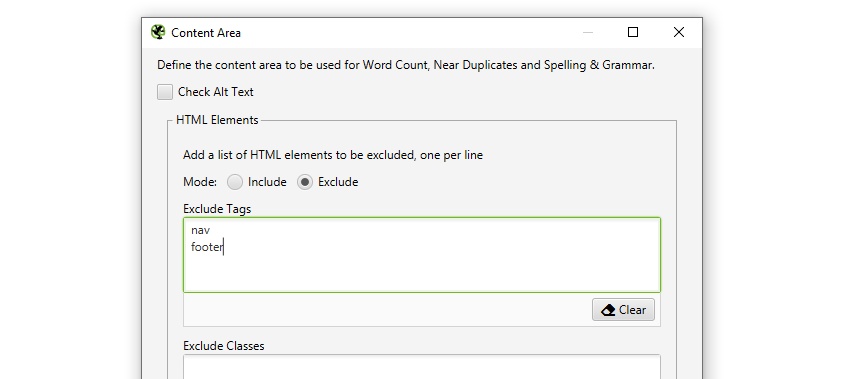
Next to duplicates, analysis is required to complete after the scanning, and more details about duplicates can be seen on the new bottom tab «Duplicate details». This displays all identified nearly identical URLs and their matches.
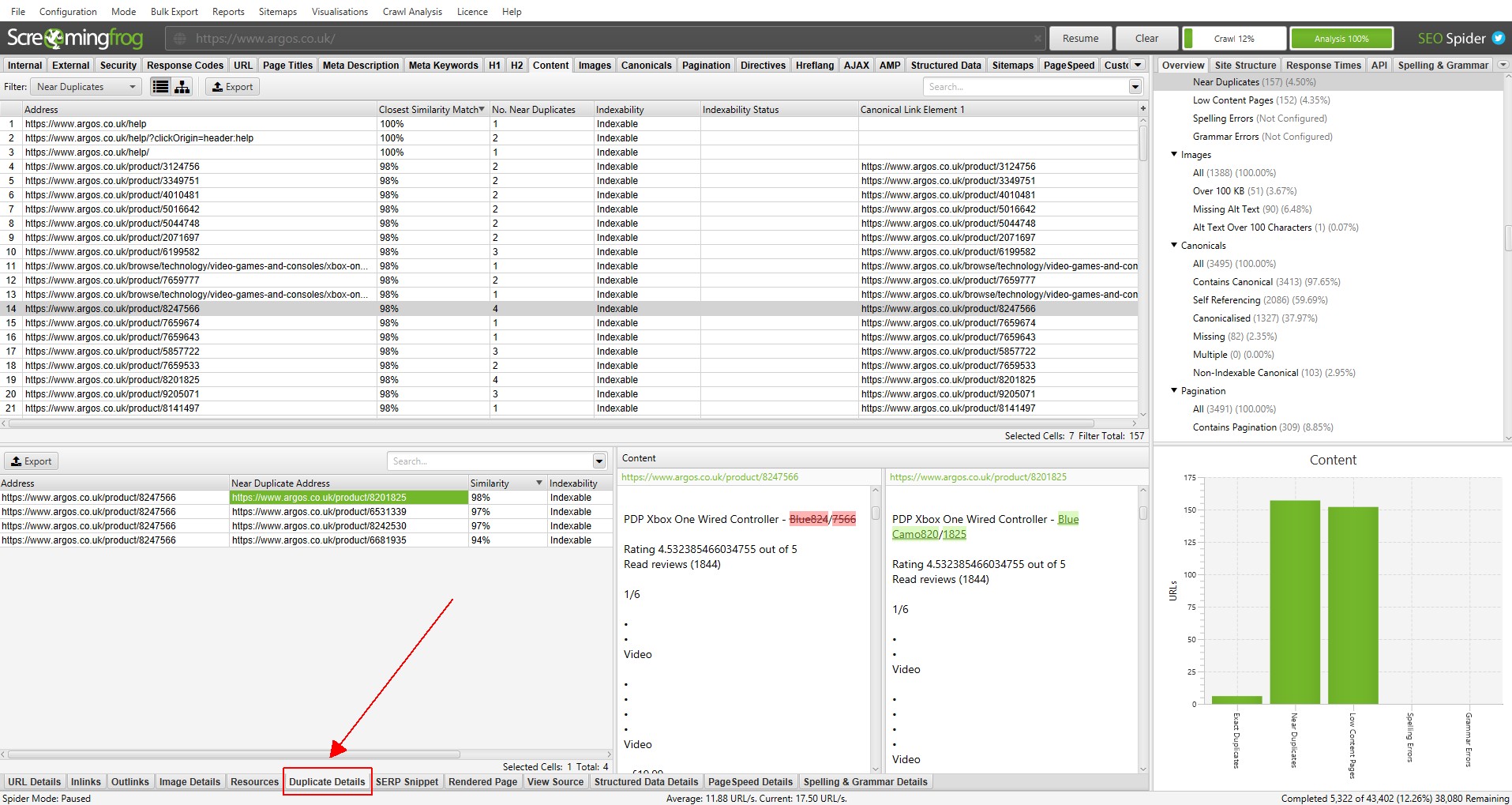
By clicking on «Near Duplicate address» in the «Duplicate details» tab, you will see non-obvious duplicate content found among the pages.
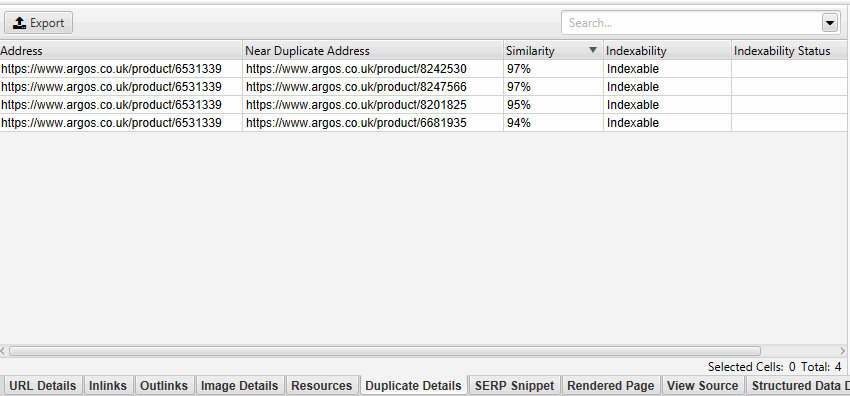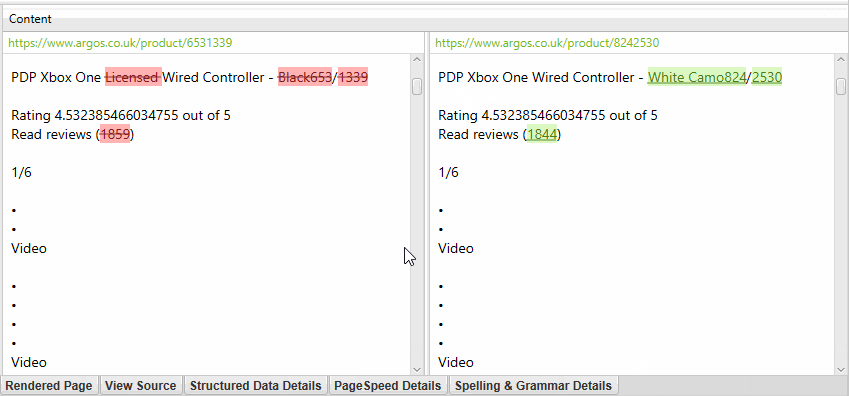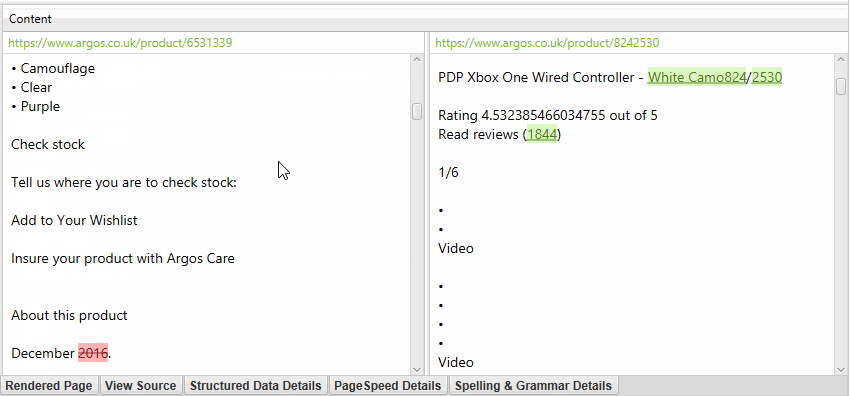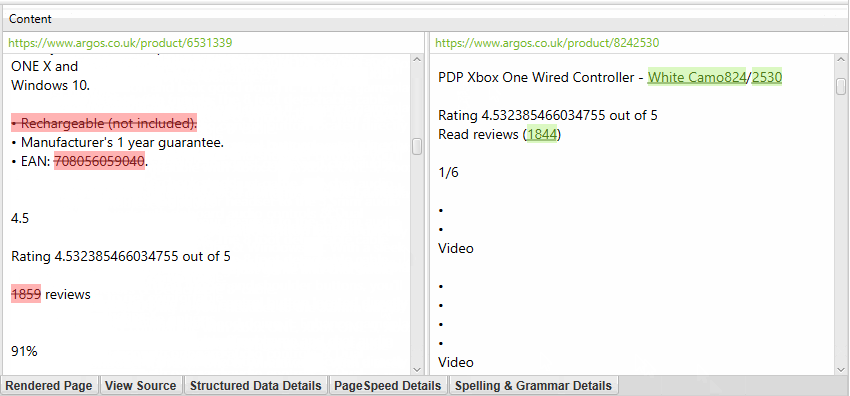
The near-duplicate content threshold and content area used in the analysis can be updated after the crawl.
The Content tab also includes a «Low Content Pages» filter that identifies pages with less than 200 words using an improved count. This can be customized to your preference in Config > Spider > Preferences as there is no universal criteria for a minimum SEO word count.
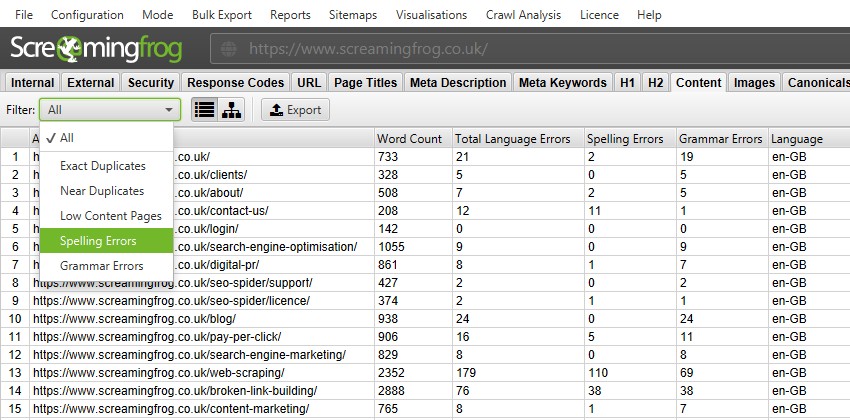
Spelling and grammar checking
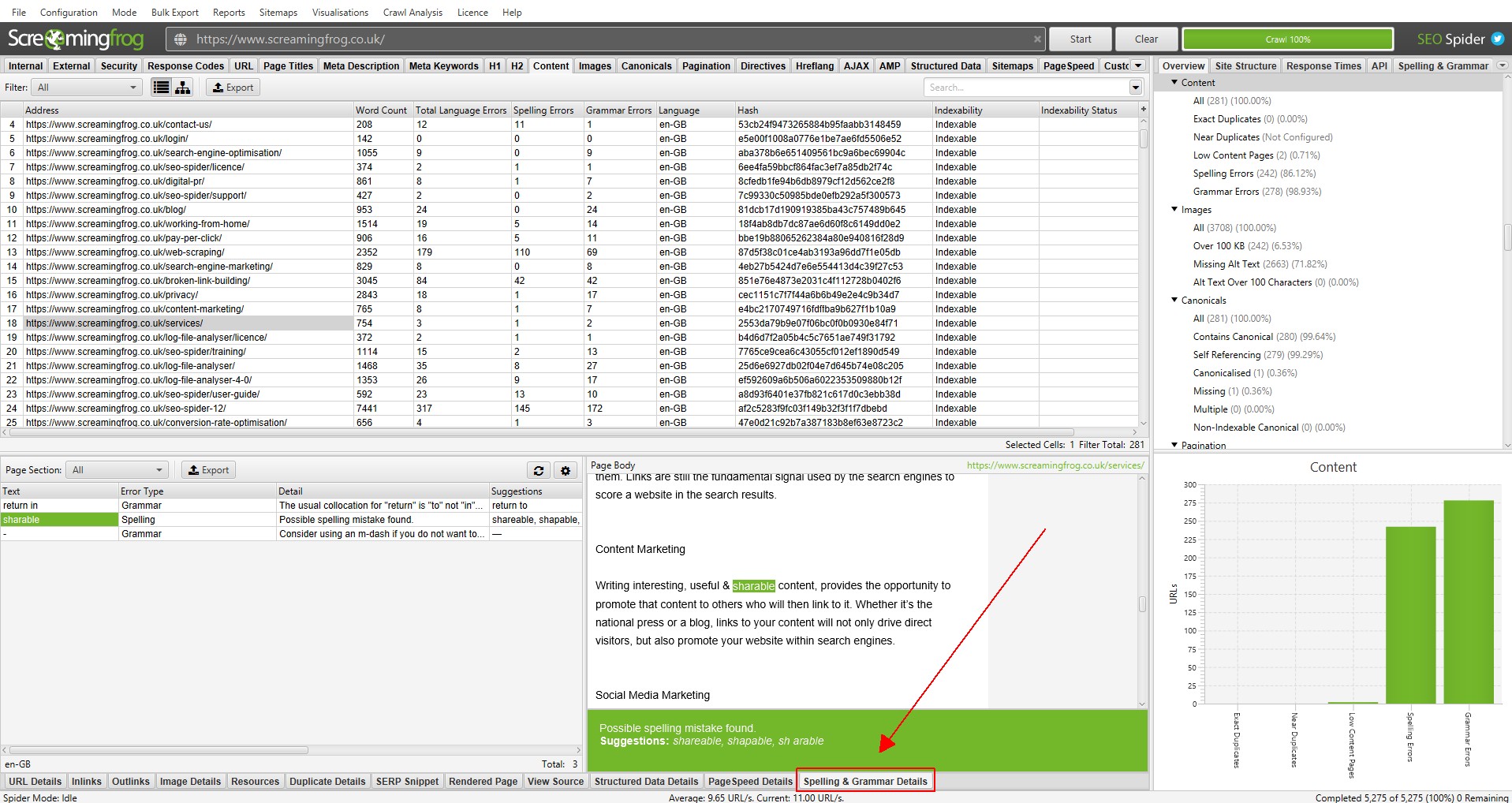
Aside from knowing how to write a high-converting press release or content of any other type, it is essntial to make sure it is error-free. How to check spelling and grammar with Screaming Frog? The new «Content» tab contains filters for «Spelling Errors» and «Grammar Errors» and displays counters for each page crawled.
You can enable spelling and grammar check Config > Content > Spelling & Grammar.
While this is a bit different from Screaming Frog's usual SEO-focused features, the main role of developers is to improve websites for users. Google's Search Quality Guidelines repeatedly describe spelling and grammatical errors as one of the characteristics of low-quality pages.
The right side of the details tab also displays the visual text from the page and the errors found.
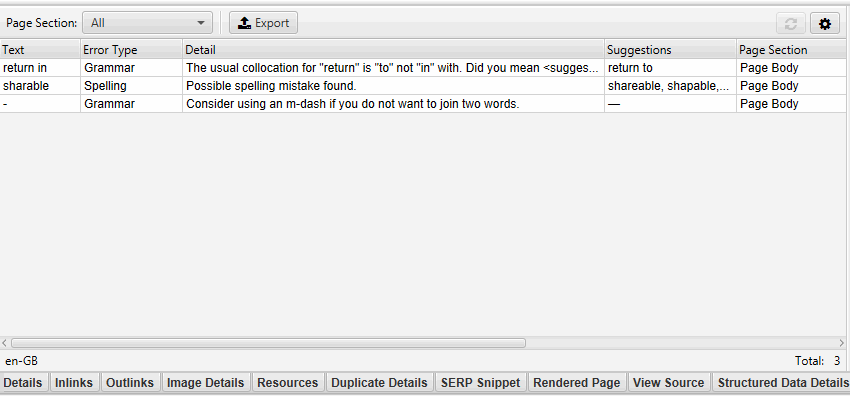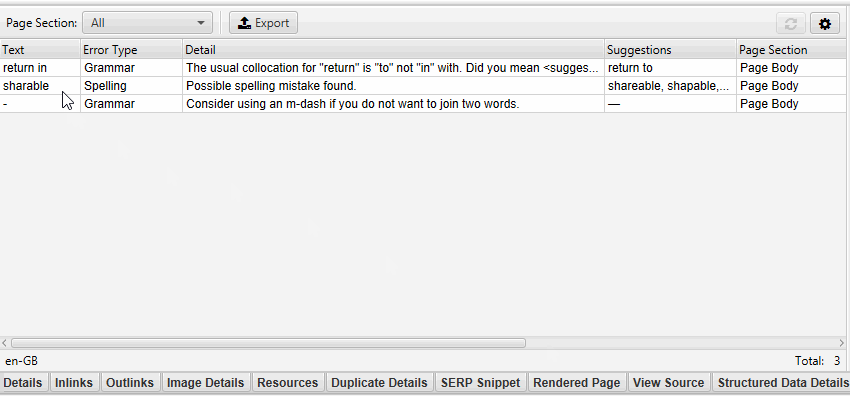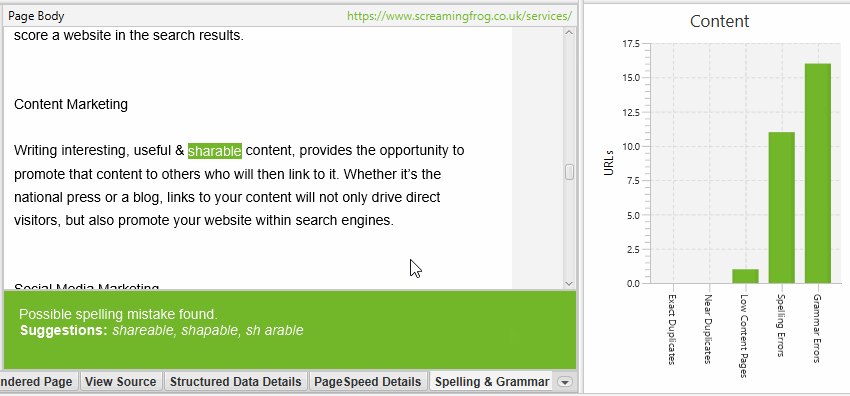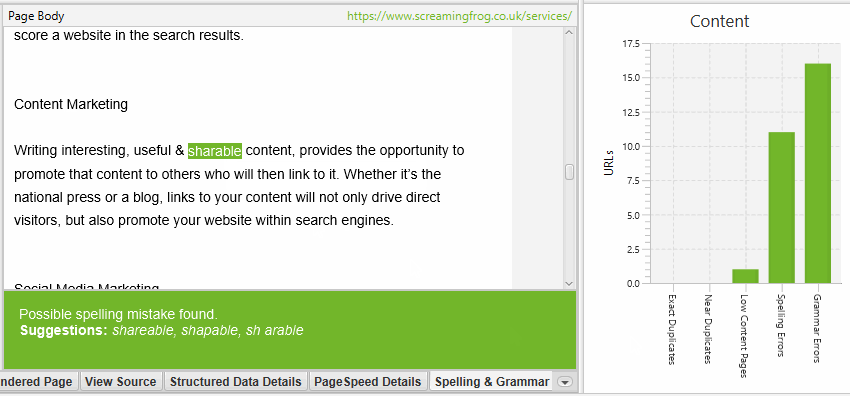
The Spelling & Grammar tab in the right pane shows the 100 unique errors found and the number of URLs they affect. This can be useful for finding errors in templates, as well as building your dictionary or list of ignored words.
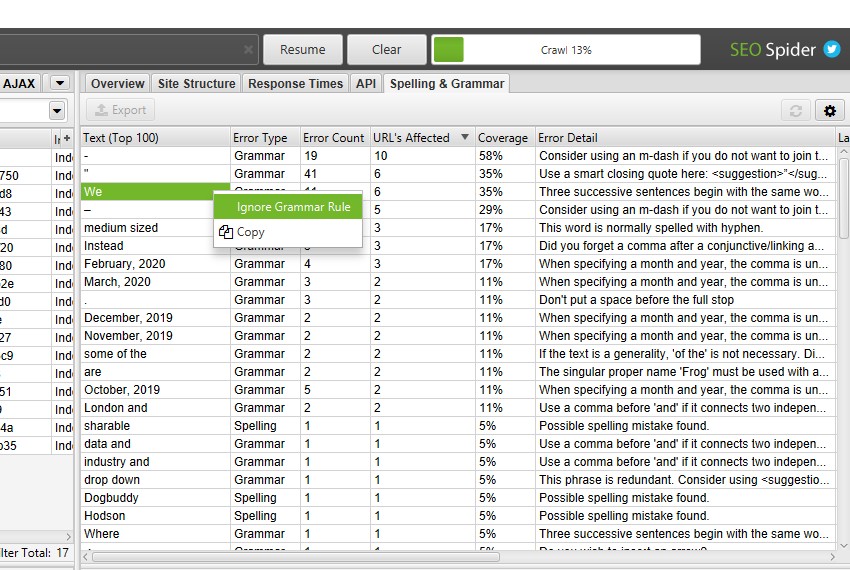
Screaming Frog's spelling and grammar checker automatically detects the language used on the page through the HTML language attribute, but also allows you to manually select it if needed.
In the Screaming Frog SEO Spider settings, you can update the spelling and grammar check to reflect changes in your vocabulary, ignore the list or grammar rules without rescanning URLs.
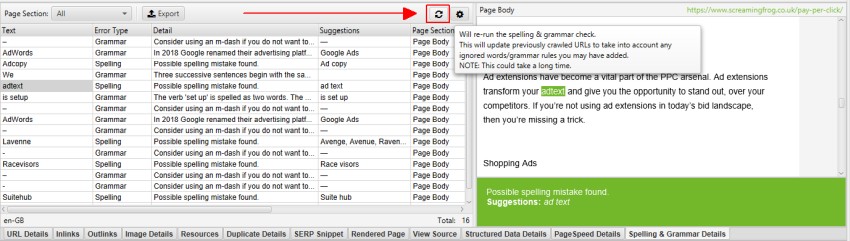
You can export all data via the Bulk Export > Content menu.
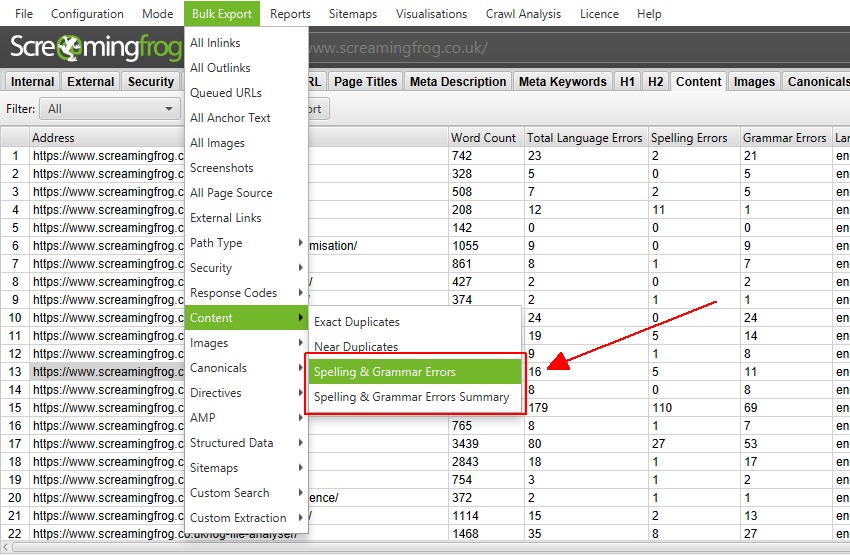
How to get a list of image links on a specific page
No matter whether you check the whole site or only crawl subfolder, simply select the page at the top of the window, click the «Image Info» tab at the bottom to see all the images found on the page. They will be listed in the «To» column.
Pro Tip — Right click on any entry at the bottom of the window to copy or open the URL.
Alternatively, you can also see the images on the page by only crawling that URL. Make sure Scan Depth is set to «1». Once the page has been crawled, click on the «Images» tab. There will be all the images found by the algorithm.
Alt check for images
Screaming Frog Seo Spider allows you to search for text alternative to images: alt. How to do it:
- Look at the settings and make sure «Check Images» is checked in Configuration > Spider.
- After the check is complete, open the «Images» tab and sort by «Missing Alt Text» or «Alt text Over 100 Characters».
- You can find image pages by going to the «Image Info» tab at the bottom of the window. These pages will be listed in the «From» column.
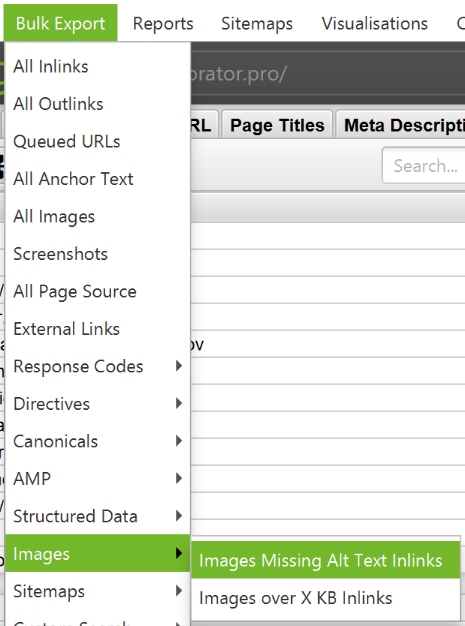
- If you're more comfortable working with CSV, open Bulk Export > All Images or Bulk Export > Images > Images Missing Alt Text Inlinks to see the full list of images. In the same place you will see their location, the alt text associated with them or problems with it.
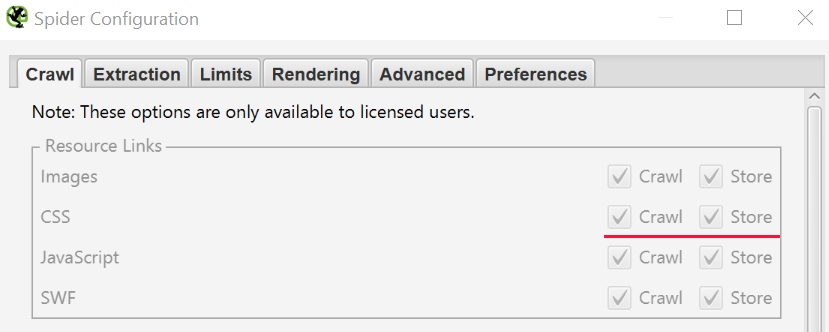
How to find CSS files
In the Configuration > Spider menu, select «Crawl» and «Store» the CSS before checking. Once completed, sort the results by «CSS» in the «Internal» tab.
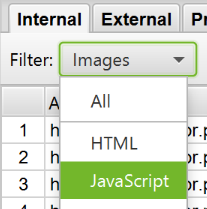
How to find JavaScript files
In the settings menu, select «Check JavaScript» before checking. Once completed, sort the results by «JavaScript» in the «Internal» tab.
How to detect all jQuery plugins on a site and which pages they are used
Check the settings and make sure «Check JavaScript» is selected in the Configuration > Spider menu. After the check is complete, sort the results in the «Internal» tab by «JavaScript», and then search for «jquery». This will give you a list of plugins. If necessary, sort the list by «Address» for easier viewing. Then look for «InLinks» at the bottom of the window, or export to CSV to find the pages where the files are used. They will be displayed in the «From» column.
Also via Bulk Export > All Links menu you can export a CSV file and filter the «Destination» column to show URLs with jQuery only.
Pro tip — how to use Screaming Frog
Not all jQuery plugins are bad for SEO. If you see that the site is using jQuery, it's good to make sure that the content you want to index is included in the page source and is processed during page load, not after.
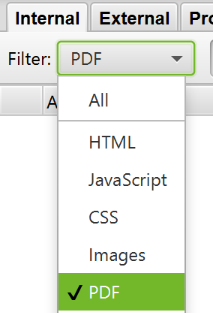
How to find linked internal PDF files
Once the scan is complete, sort the results by «PDF» in the «Internal» tab.
How to find pages with a share button on social media
To find pages that contain the «Share» button, you need to set up a custom filter before running the check. To do this, open Configuration > Custom. From there, enter any code snippet from the page source.

In the example above, we wanted to find pages that contain a Facebook Like button. To do this we created a filter for facebook.com/plugins/like.php
How to Find Pages That Use Frames
To find pages that use frames, set a custom filter for the iframe via Configuration > Custom before starting the test.
How to find pages with embedded video and audio content
To find pages with video or audio content, set a custom filter for the embed code snippet from Youtube or another media player that is used on the site.

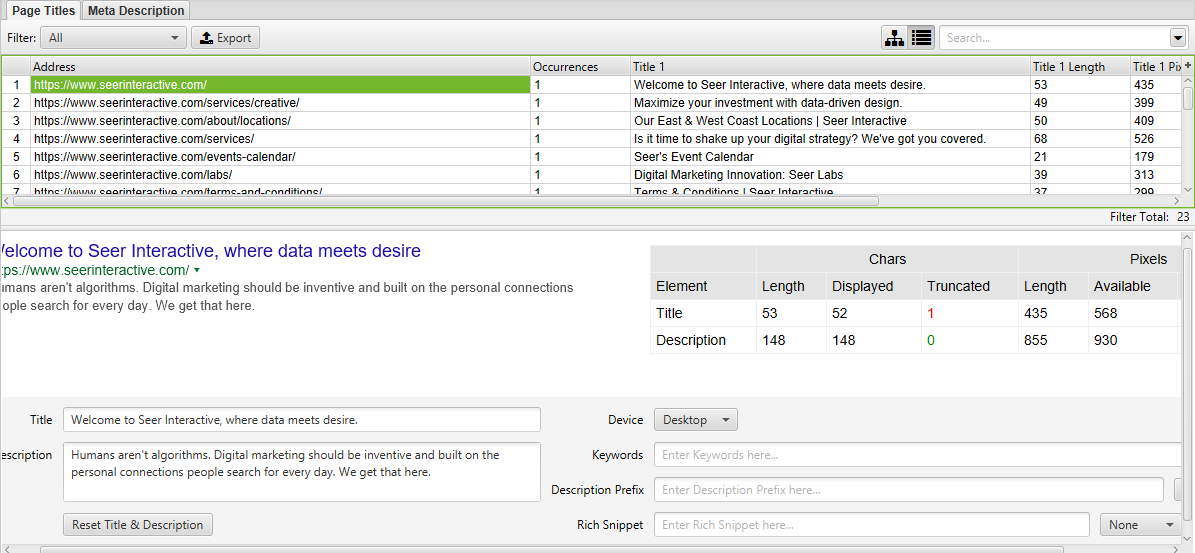
Checking meta data: how to find duplicate titles and descriptions
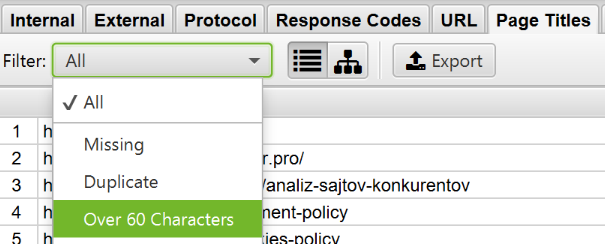
How to find pages with long metadata
To find long titles and descriptions, after the check is complete, open the «Page Titles» tab and sort by «Over 60 Characters» to see the long page titles. You can do the same in the «Meta Description» and «URL» tabs.
How to find duplicate titles and descriptions
To find duplicate title and description metadata, after checking is complete, open the «Page Titles» tab, then sort by «Duplicate». You can do the same in the «Meta Description» «URL» tabs.
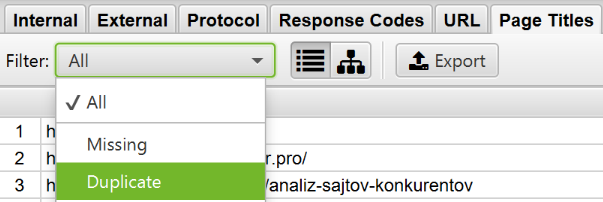
How to find pages with meta-directives noindex, nofollow, etc.
Using Screaming Frog Seo Spider, you can find pages that are closed from indexing. After completing the check, go to the «Directives» tab. To see the type, scroll to the right and see which column is filled. You can also use the filter to find any of the following tags:
- index;
- noindex;
- follow;
- nofollow;
- noarchive;
- nosnippet;
- noodp;
- noydir;
- noimageindex;
- notranslate;
- unavailable_after;
- refresh.
This information can also be viewed in the right sidebar.
Is it possible to check the robots.txt file?
Screaming Frog matches the robots.txt file by default. As a priority, it will follow the instructions made specifically for the Screaming Frog user agent. If there are no such instructions, the algorithm follows the instructions of Googlebot. If there are none, then the algorithm will execute the global instructions for all user agents.
The algorithm will follow one set of instructions, so if there is a set of rules set only for Screaming Frog, it will only follow them. If you want to hide certain parts of the site from the algorithm, use the normal «Screaming Frog SEO Spider» robots.txt syntax. If you want to ignore robots.txt, just select this option from the settings menu: Configuration > robots.txt > Settings.
How to find or check microdata on a site
Today, there many markups are available for webmasters. FAQ Schema is the most widely used one. If you don't have it on your site but want to add it, learn about the benefits of using FAQ Schema for SEO, how to create it, and avoid or correct common errors on our blog.
To find pages with markup or microdata using Screaming Frog, use a custom filter. Go to Configuration > Custom > Search and enter the snippet you want.
To find pages with markup, add the following code snippet to a custom filter: itemtype=http://schema.org
To find a specific kind of markup, specify the details. For example, using a custom filter will give you all pages marked up for ratings.
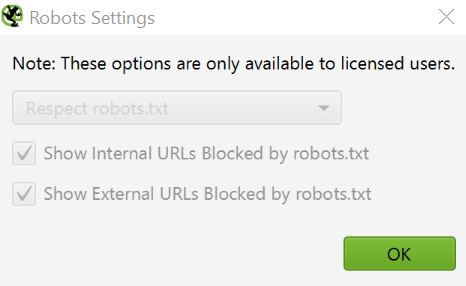
Speaking of Screaming Frog 11.0, the SEO algorithm also provides the ability to check, extract, and structured data directly from search results. Check any JSON-LD, Microdata or RDF structured data against Scema.org guidelines and Google specifications in real time during the process of checking. To access structured data checking tools, select the Configuration > Spider > Advanced > Structured Data option.
Now you will see the Structured Data tab in the main interface. It will allow you to switch between pages with structured data in which this data is omitted. They may also contain validation errors and warnings.
You can also bulk export structured data issues with Screaming Frog by visiting Reports > Structured Data > Validation Errors&Warnings.
Creating and validating a Sitemap in Screaming Frog
How to build sitemap in Screaming Frog (XML)
There are many SEO tools online that allow for building an XML or visual sitemap. Screaming Frog is one of the most popular and easy-to-use software that offers an XML sitemap generator. To create a sitemap.xml file with Screaming Frog Spider, after the site has been crawled, go to Sitemaps > Sitemap XML.

Once you open the Sitemap XML settings, you can include and exclude pages by response code, modification date, priority, change frequency, etc. Screaming Frog includes 2xx URLs by default, but double-checking is a good rule.
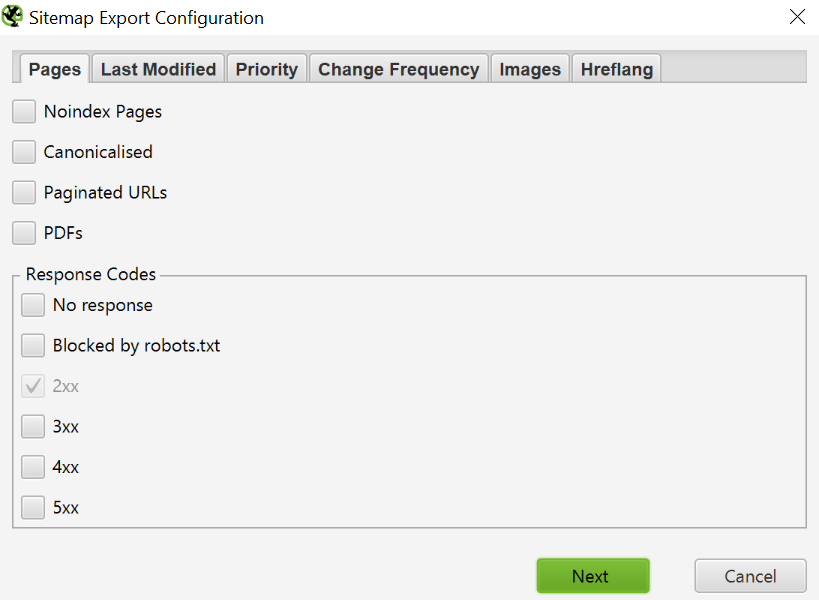
Ideally, the sitemap should contain pages with status 200, the canonical version of each URL without any duplicate factors. Click OK to save your changes. The Sitemap XML will be downloaded to your device and will allow you to edit the naming convention at your discretion.
How to build an XML Sitemap by uploading a URL
You can also create an XML Sitemap by uploading URLs from an existing file or manually pasting them into Screaming Frog.
Change the mode from Spider to List in Mode and click Upload to select any of the options.
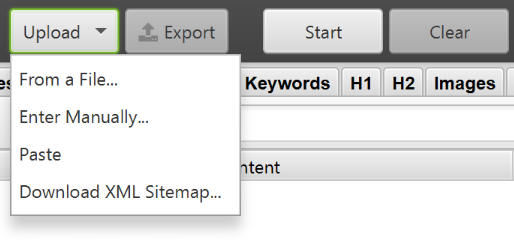
Click the Start button and Screaming Frog will check the uploaded URLs. Once he does, you can do the above steps.
How to crawl an existing XML Sitemap
You can upload an existing XML Sitemap to check for errors or discrepancies.
Open the «Mode» menu in Screaming Frog and select «List». Then, click «Upload» at the top of the screen and select Download Sitemap or Download Sitemap Index, enter the sitemap URL and start checking. Once completed, you will be able to find redirects, 404 errors, duplicate URLs, etc.
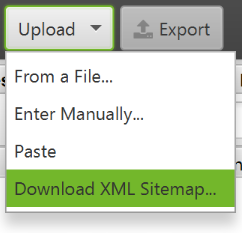
Checking for missing pages in an XML Sitemap
You can set up validation options to examine and compare the URLs in the sitemap with the URLs from the search.
Go to Configuration > Spider in navigation and you will have several options for Sitemap XML - Auto discover XML sitemaps via robots.txt file or enter a link to Sitemap XML in the window.
Note: If your robots.txt file doesn't contain the correct target links for all the XML Sitemaps you want to scan, enter them manually.
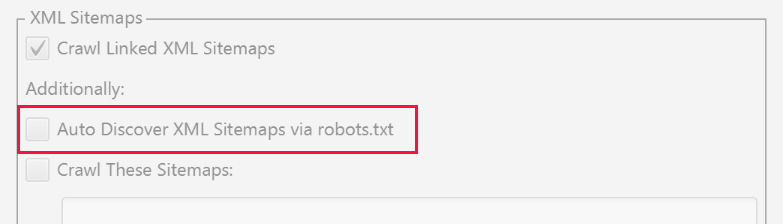
Once you've updated your sitemap validation settings, open «Crawl Analysis» and then click «Configure» and make sure the Sitemap button is checked. If you want to do a full site crawl first, then go back to Crawl Analysis and click Start.
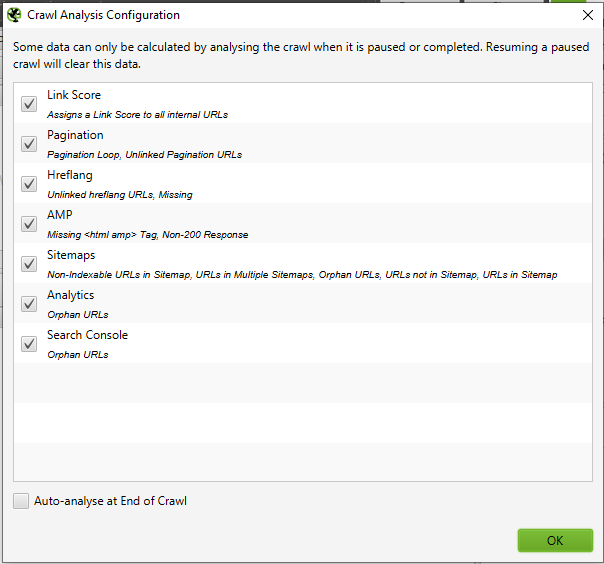
Upon completion of Crawl Analysis, you will be able to see all inconsistencies. For example, links that were identified during a full crawl, but missed in the sitemap.
Other technical problems that Screaming Frog will help to solve
Why a particular section of a site isn't Indexed or ranked
Trying to figure out why certain pages aren't indexed? First, make sure they don't accidentally end up in robots.txt or are marked as noindex. We wrote above which Screaming Frog Seo Spider reports you need to watch.
Next, check that the algorithms can reach the pages by checking internal links. Pages without internal linking are referred to as Orphaned Pages. How to find orphan pages on a website using Screaming Frog? To identify such pages, follow these steps:
- go to Configuration > Spider. At the bottom there will be some options for the sitemap XML. Either auto-validate the sitemap via robots.txt or manually enter the sitemap XML link.
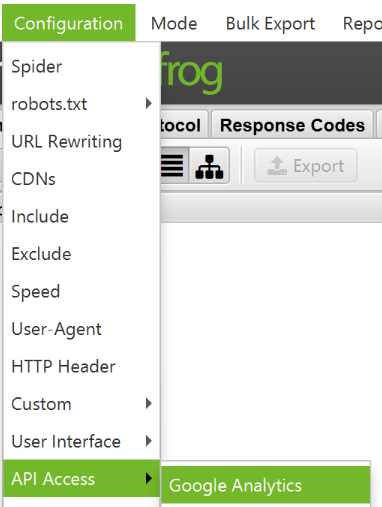
Note that if robots.txt doesn't contain the correct target links to all the XML sitemaps you want to scan, you'll need to enter them manually; - go to Configuration > API Access > Google Analytics. Using the API, you can get and view analytics data for a specific account. To find orphan pages from organic search, make sure to segment by «Organic Traffic»;
![what is screaming frog used for]()
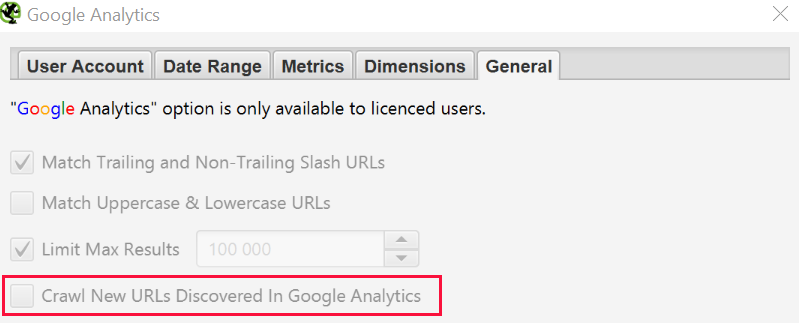
- you can also go to the General > Crawl New URLs Discovered in Google Analytics tab if you want them to be included in the full site check. If this setting is not enabled, you will only be able to view new URLs from Google Analytics in the Orphan Pages report;
![how to use screaming frog seo spider]()
- go to Configuration > API Access > Google Search Console. Using the API, you can get and view Google Search Console analytics data for a specific account. To find orphan pages, you can search for URLs getting clicks and impressions that weren't included in the crawl. Tip: You can also go to General > Crawl New URLs Discovered in Google Search Console if you want them to be included in the full site check. If this setting is not enabled, you will only be able to view new URLs from Google Search Console in the Orphan Pages report;
- crawl the whole site. Once completed, go to Crawl Analysis > Start and wait for it to complete;
- see the orphan URLs in each tab, or bulk export the URLs by going to Reports > Orphan Pages.
If you do not have access to Google Analytics or Search Console, you can export the list of internal URLs as a CSV file using the «HTML» filter in the «Internal» tab.
Open the CSV file and on the second page paste a list of URLs that aren't indexed or don't rank very well. Use VLOOKUP to see the URLs found during the crawl on the second page.
How to check if the site migration was successful
You can use Screaming Frog to check if old URLs were redirected using List mode to check code statuses. If the old links return a 404 error, then you will understand which URLs should be redirected.
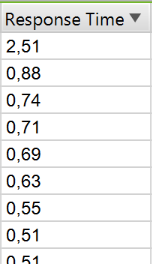
How to find pages with a slow loading speed
Screaming Frog will help you find pages with a slow loading speed. After the scan is complete, open the «Response Code» tab and sort the «Response Time» column in descending order. This way you can identify pages with the slow loading speed.
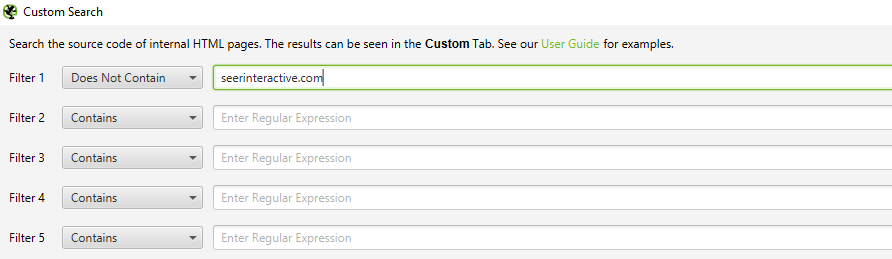
How to find malicious software or spam on a site
First you need to identify traces of malicious software or spam. Next, go to Custom > Search in the settings menu and enter the snippet you are looking for.
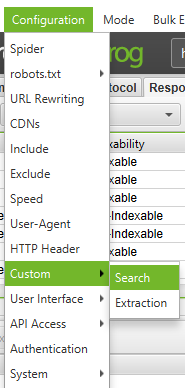
You can enter up to 10 fragments per scan. Then click OK and continue scanning the site or list of pages.
After the scan is complete, select the «Custom» tab at the top of the window to see all pages that contain the specified fragment. If you have entered more than one custom filter, you can see each one by changing it in the results.
PPC verification and analytics
How to validate a PPC URL list
Save the list as a .csv or .txt file. Change the «Mode» setting to «List».
Then select a file to upload. You can click Start, or paste the list into Screaming Frog manually. Look at the status code of each page in the «Internal» tab.
Cleaning up information in Seo Frog Spider
How to clean up metadata for a page list
So you have a bunch of URLs, but you need more information about them? First of all, set the mode to «List». Upload the list of URLs (.csv or .txt file). Once verified, you can see code statuses, outbound links, word counts, and meta data for each page on your list.
How to clean up the site from pages that contain certain information
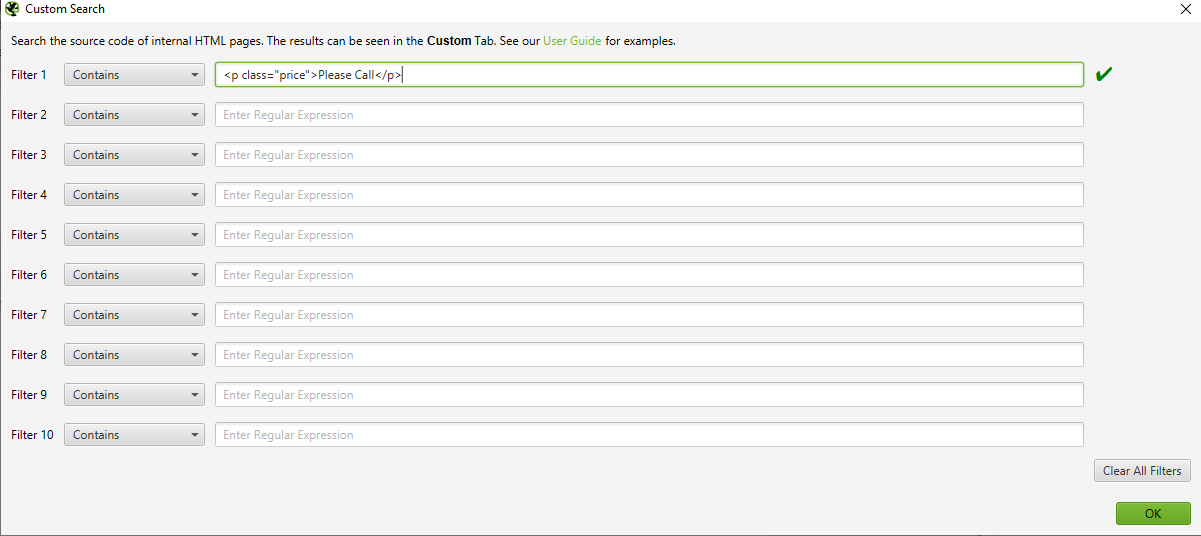
Go to «Settings», select Extraction or Search in the «Custom» menu and enter the desired fragment.
You can enter up to 10 different snippets per search. Click OK and proceed to crawl the site or list of pages. In the example below, we wanted to find all pages that contain «Please Call» in the pricing section, so we found and copied the HTML code from the page's source.
Upon completion of the search, select the «Custom» tab at the top of the window and see all the pages with the required fragment. If you have entered more than one custom filter, you can view each one by changing the result filter.
Pro Tip — If you're pulling data from a client's site, you can save time by asking the client to pull the data directly from the database. This method is suitable for sites that you do not have direct access to.
Renaming URLs in program settings
How to find and replace session IDs or other parameters on scanned pages
To identify URLs with session IDs or other parameters, simply scan your site with default settings. Upon completion of the check, go to the «URL" tab and sort by «Parameters» to see all links with parameters.
To remove parameters from displaying in validated URLs, go to Configuration > URL Rewriting. Then in the «Remove Parameters» tab, click «Add» to add the parameters you want to remove from the URLs and click OK. Restart the scan with these overwrite settings.
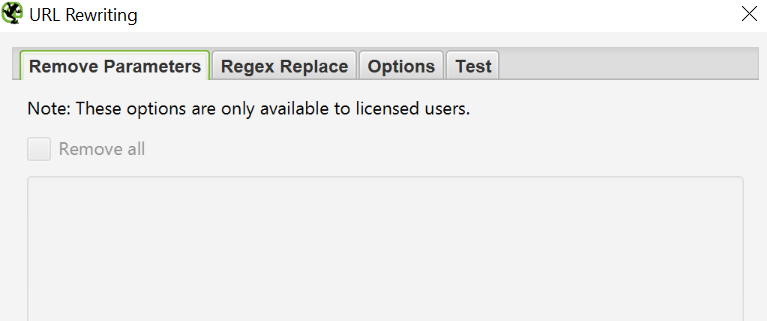
How to rename verified URLs
If you need to rename URLs after crawling a site with Screaming Frog Seo Spider, go to Configuration > URL Rewriting to rewrite any verified URL. Then, in the «Regex Replace» tab, click «Add» to add the Reg Ex for what you want to replace.
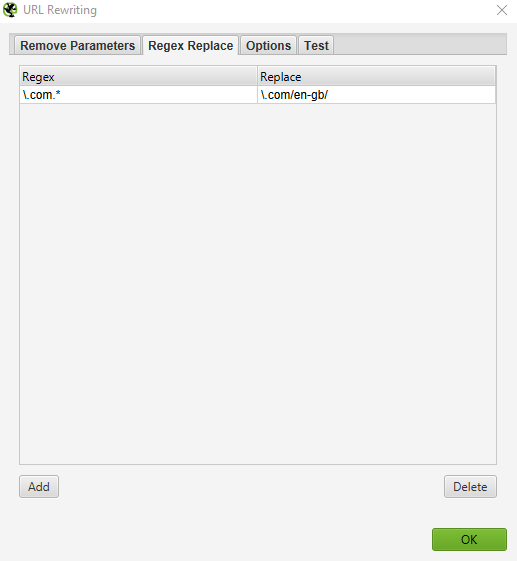
Once you have added all the desired rules, you can test them in the «Test» tab. To do this, enter a test URL in «URL before rewriting». «URL after rewriting» will be updated automatically according to your rules.

If you want to set a rule that all URLs return in lowercase, set «Lowercase discovered URLs» in the «Options» tab. This will remove any duplication on header URLs in the check.
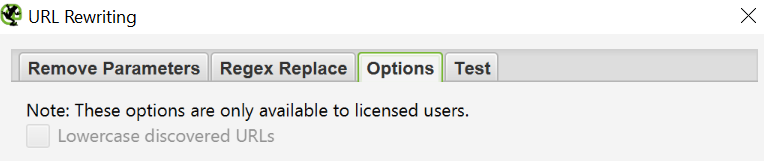
Don't forget to restart the scan with these overwrite settings.
Competitor’s keyword analysis
How to find out my competitors' most important pages
In general, competitors will try to spread link popularity and drive traffic to the most valuable pages using internal linking. Any competitors with a SEO mindset are more likely to link to important pages from the company's blog. Find valuable pages of your competitors by scanning their site. Then sort the «Inlinks» column in the «Internal» tab in descending order to see the pages with the most internal links.
To view pages linked from your competitor's blog, deselect «Check links outside folder» in Configuration > Spider and scan the blog folder. Then, in the «External» tab, sort the results using the search by primary domain URL. Scroll to the right and sort the list in the «Inlinks» column to see the most linked pages.
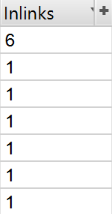
Pro Tip — Drag a column to the left or right to improve the display of data.
What anchors do my competitors use for internal links?
Screaming Frog Seo Spider allows you to analyze anchors on your site or competitors' anchors.
Go to Bulk Export > All Anchor Text to export a CSV file that contains all the anchor texts on the site, where they are used and what they link to.
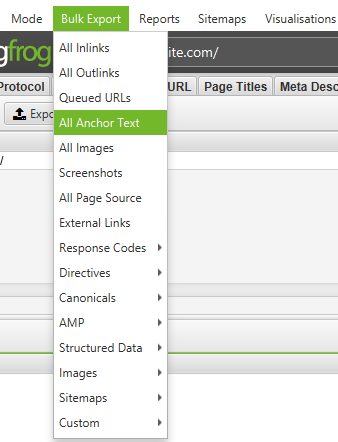
How to find a site's outbound links and use it for link building
How to get a list of promising link locations
If you've deleted or created a list of URLs you need to check, you can download and scan them in «List» mode to get more information about the pages. Check the status codes in the «Response Codes» tab, when the scan is complete. View the outgoing links, their types, anchor texts and nofollow directives in the «Outlinks» tab in the lower window. This will tell you which sites these pages link to. To view the Outlinks tab, make sure the URL you are interested in is selected in the top window.
Of course, with a custom filter, you'll want to check if these pages are linking to you or not.
You can also export the full list of outlinks by going to Bulk export > All outlinks. This will not only give you links to external sites, but it will also show you all the internal links on the individual pages of your list.
How to find broken links for outreach opportunities
So, have you found the site you want to get a link from? Use Screaming Frog to find broken links on the page or site, then reach out to the site owner, suggesting your resource as a replacement for the broken link where possible. It can be a successful tactic when engaging in link building for ecommerce website or any other type of website. Well, or just offer a broken link as a gesture of good faith :)
How to check backlinks and see the anchor text
Load your list of backlinks and run the algorithm in Mode > List mode. Then export the full list of outbound links by going to Bulk Export > All Outlinks. This will give you the URLs and anchor/alt text for all links on those pages. You can then use the filter on the «Destination» column in the CSV to determine if your site is being linked and what anchor/alt text is included.
Read also: Buy Backlinks for SEO and Best Tools for Link Building👈
How to make sure backlinks have been removed
Set a custom filter containing the root domain URL by going to Configuration > Custom > Search. Then load the list of backlinks and run the algorithm in Mode > List mode. Once the scan is complete, click the «Custom» tab to see all the pages that still link to you.
Bonus Round
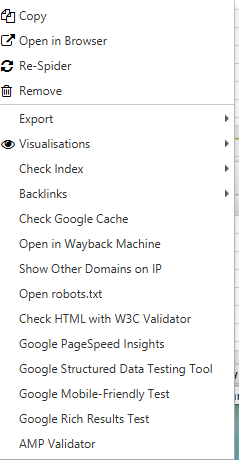
Did you know that when you right click on any URL in the top results window, you can do any of the following?
- copy or open URL;
- re-crawl or remove the URL;
- export URL information, inbound links, backlinks, or image information for this page;
- check page indexing in Google, Bing and Yahoo;
- check backlinks to the page in Majestic, OSE, Ahrefs and Blekko;
- look at the cached version and cache date of the page;
- view old versions of the page;
- check the HTML code of the page;
- open the robots.txt file for the domain where the page is located;
- find other domains on the same IP.
How to edit metadata
SERP mode allows you to view SERP snippets on the device to visualize metadata in search results.
- Upload URLs, titles and meta descriptions to Screaming Frog using a CSV or Excel document.
Note that if you have already crawled your site, you can export URLs by selecting Reports > SERP Summary. This will easily format the URLs and meta you want to download and edit. - Go to Mode > SERP > Upload File.
- Edit the metadata in Screaming Frog.
![screaming frog seo spider regulation]()
- Make a bulk export of metadata to send directly to developers.
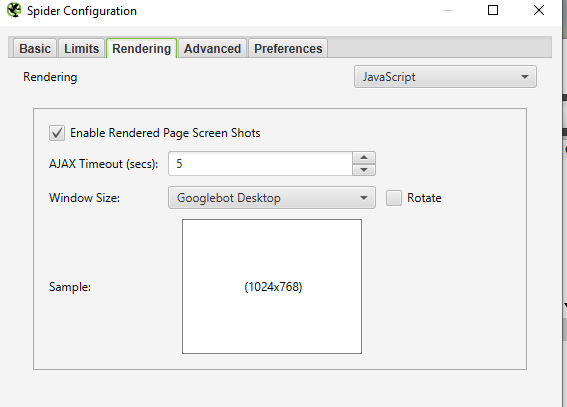
How to crawl a JavaScript website
JavaScript frameworks such as Angular, React, etc. are increasingly being used to build websites. Google recommends using a rendering solution as Googlebot is still trying to scan the JavaScript content. If you have defined a site using JavaScript and want to crawl, follow the instructions below:
- go to Configuration > Spider > Rendering > JavaScript;
![screaming frog seo spider instructions]()
- change the render settings depending on what you are searching for. You can adjust the timeout, window size (mobile, tablet, desktop);
- click OK and start scanning.
At the bottom of the navigation, click the «Rendered Page» tab to see how the page is displayed. If it doesn't display properly, check for blocked resources or increase the connection timeout limit in the configuration settings. If none of the options solve it, a more serious problem will arise.
You can view and bulk export any blocked resources that may affect your site's crawling and rendering by going to Bulk Export > Response Codes.
FAQ (Frequently Asked Questions)
Question 1: Is Screaming Frog software worth it?
Yes, it is. Whatever Screaming Frog SEO Spider review you find on the Internet and read, you’ll see that this tool is definitely worth using. Based on our own experience, we can say with absolute certainty that it does save SEO specialists tons of time.
Surely, it doesn’t mean that there is no need to use any other tools. There are lots of useful software that can help you improve your site’s SEO performance. For instance, you can additionally use the Ahrefs service. On Collaborator’s blog, you will also find Ahrefs guide👈
Question 2: How to use this Screaming Frog SEO Spider tutorial?
- Look through the tutorial.
- Define your SEO tasks clearly.
- Find the relevant section of a tutorial and follow our recommendations.
We give you the best tips for using this tool and share our own experience in our Screaming Frog tutorial.
Question 3: Are there good Screaming Frog SEO Spider reviews?
You can find tons of reviews online on how specialists use Screaming Frog SEO Spider for their work. Virtually all of them are satisfied with this tool and recommend it for use.
Question 4: How many people can use the Screaming Frog SEO Spider license?
Each license key can be used by only one individual user.
Question 5: What is Screaming Frog used for?
It helps to perform a detailed website audit to discover SEO errors from short titles to broken internal and external links. This tool offers lots of features. So you will easily find out what is done properly and what you need to change on your site.
We hope this guide will give you answers to the questions "What is Screaming Frog?" and "How does Screaming Frog work?" as well as help you understand its settings.
In this guide, we have collected the main features of Screaming Frog: how to do a technical audit, how to find duplicate metadata, how to check outgoing links, how to check broken links and redirects, how to use Screaming Frog to simplify link building and other nuances of working with the program.
Did you know about all the features of Screaming Frog Seo Spider?






