Ever feel like your website's playing hide and seek with Google, and Google's not even trying to find it? If this sounds relatable and you've found yourself looking for ways to speed up your indexing (which is probably why you're reading this in the first place), you might have a crawl budget problem on your hands.
But don't worry, we're about to crash course you in crawl budget optimization. We promise, it's not as dry as it sounds.
We're about to dive into the real-life crawl budget optimization case that helped Yaroslav Beshta grow his client's website grow 3X which he presented at Collaborator's recent webinar.
Here's what we're unpacking:
- How to know if your website has indexation problems and needs crawl budget optimization;
- How to analyze website's logs;
- How to optimize crawl budget and fasten website's indexation;
- How to protect your website from spam attacks;
- How to optimize internal linking to grow 3x — based on a real-life case study.
Ready to make search engines fall head over heels for your site? Let's dive in.
About the Speaker

Here are a few facts about Yaroslav:
- Has worked in SEO since 2012;
- Co-hosts "Sho Za Shum" (What's That Noise) podcast;
- Had experience working in an agency setting on various e-commerce projects across Ukraine, the US, and the UK;
- Currently works at Promova — a Ukrainian-made language learning platform.
Crawl Budget: What It Is and Why Is It Important for SEO
Crawl budget is basically the attention span of search engine bots — it refers to the number of pages a crawler will scan on your site. Search engines allocate a crawl budget to ensure they efficiently index the most valuable content on your site while avoiding the waste of resources on low-value or duplicate pages.
To figure out whether your website is in need of crawl budget optimization, Yaroslav points out two red flags that may signal about it:
- You've got a ton of pages that just aren't getting indexed;
- New pages take forever to start appearing in search results.
While crawl budget optimization is crucial for large websites (we're talking millions of pages), even smaller sites with 5k-10k pages can benefit from it.
Let's look at a real case Yaroslav worked on. This client had over 12 million pages just sitting in Google Search Console, marked as "Discovered, Not Indexed."
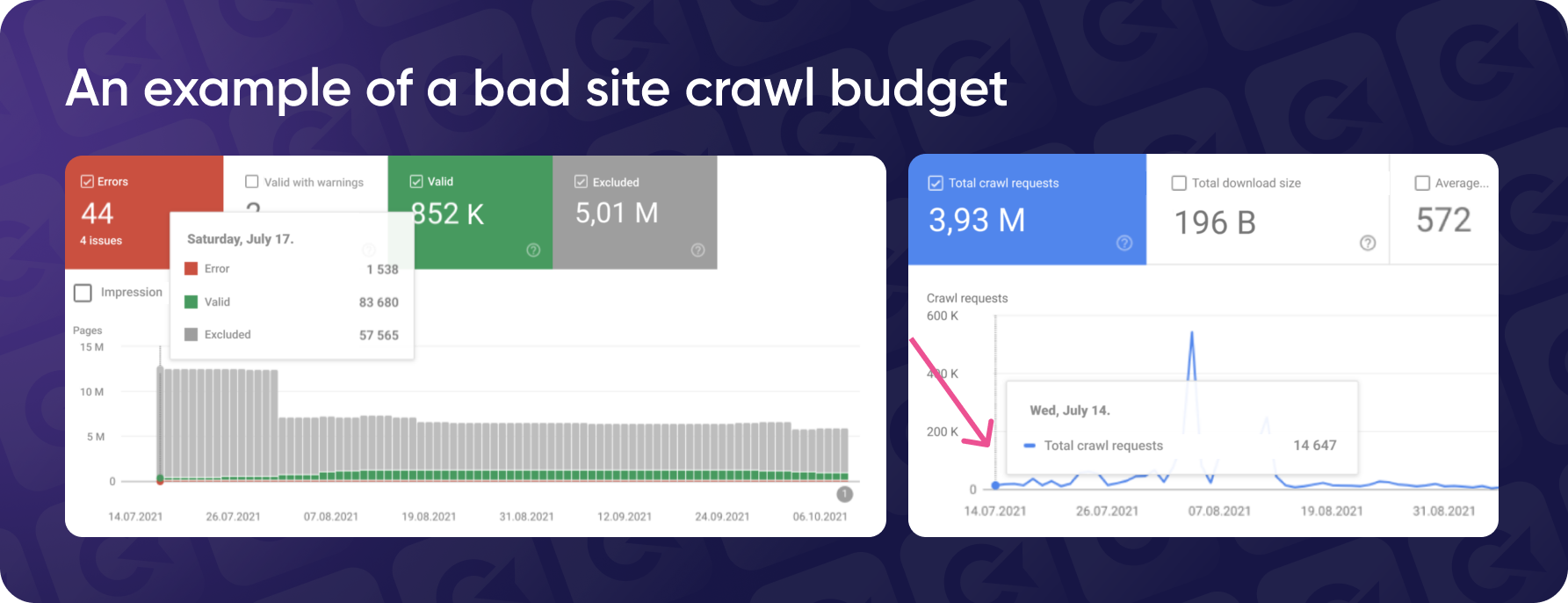
The same screenshot shows that despite the site having over 20 million pages, the bot only visited about 14 thousand pages a day.
How to Analyze Website Logs & Which Tools To Use
If you want to effectively manage your site's crawling budget, you need to get your hands dirty with log files. We promise, it's not as boring as it sounds.
Just a heads up though: logs won't directly point out the problem. Before you start digging, you'll need a theory. Maybe you want to see how often the bots are visiting pages with that new indexing plugin you installed, or if they've ghosted certain pages since you added new filters.
When analyzing your website's logs, here are the key points to focus on:
- Identify the Bots
Pay attention to which bots are crawling your site. It's not just Google; other bots might scan your pages and consume your server resources. If you notice excessive crawling by certain bots, especially less critical ones, consider limiting their access. For instance, you can use Bing Webmaster Tools to reduce the crawl frequency of Bing's bot. - Prepare for High Traffic
If you run an e-commerce site, especially around high-traffic events like Black Friday, ensure your site can handle the traffic load. Tools like Imperva can help you manage the surge. However, increased bot activity during these times can also inflate your hosting costs if mismanaged. - Monitor Page Visits by Bots
Check which pages are frequently visited by search engine bots. Typically, the homepage gets the most traffic, as it's often the entry point for both users and bots. By analyzing these patterns, you can identify under-indexed pages and strategically place links on frequently visited pages to encourage bots to crawl and index them. - Analyze Response Codes
Pay close attention to pages with high response codes, like 404 (Not Found) or 500 (Server Error). If a page frequently shifts between statuses (e.g., 200 OK one day, 404 the next), it may indicate a problem that needs addressing. - Check Page Load Times
Analyze how long it takes bots to load your pages. If specific pages take too long to load (e.g., more than two seconds), it could indicate issues like large images or heavy scripts needing optimization. - Review URL Structures
Bots might generate URLs through filter combinations that users wouldn't normally create, consuming excessive resources. If you find such URLs in your logs, consider blocking them or returning a 410 status to conserve resources. - Evaluate Crawl Budget Usage
Ensure that the bot's crawl budget is being used effectively. If a significant portion of the crawl budget is spent on pages blocked from indexing, you might need to adjust your site's structure or hide certain links from bots. This will ensure that more of your important pages are crawled and indexed.
Now that you know what to look for, let's take a look at Yaroslav's go-to tools for log analysis.
Google Search Console
Our first tool is Google Search Console, the holy grail of any SEO specialist. We won't dive too deply into it (for obvious reasons) and will go straight to log analysis. First things first, you have to make sure you have access to all domains and subdomains.
It might seem obvious, but here's a real-life example from Yaroslav. His client's website had multiple domains, including a test domain that was hidden among the rest. Upon closer examination, he noticed that the bots were frequently crawling the hidden test domain in question, wasting resources on something invisible to the naked eye.
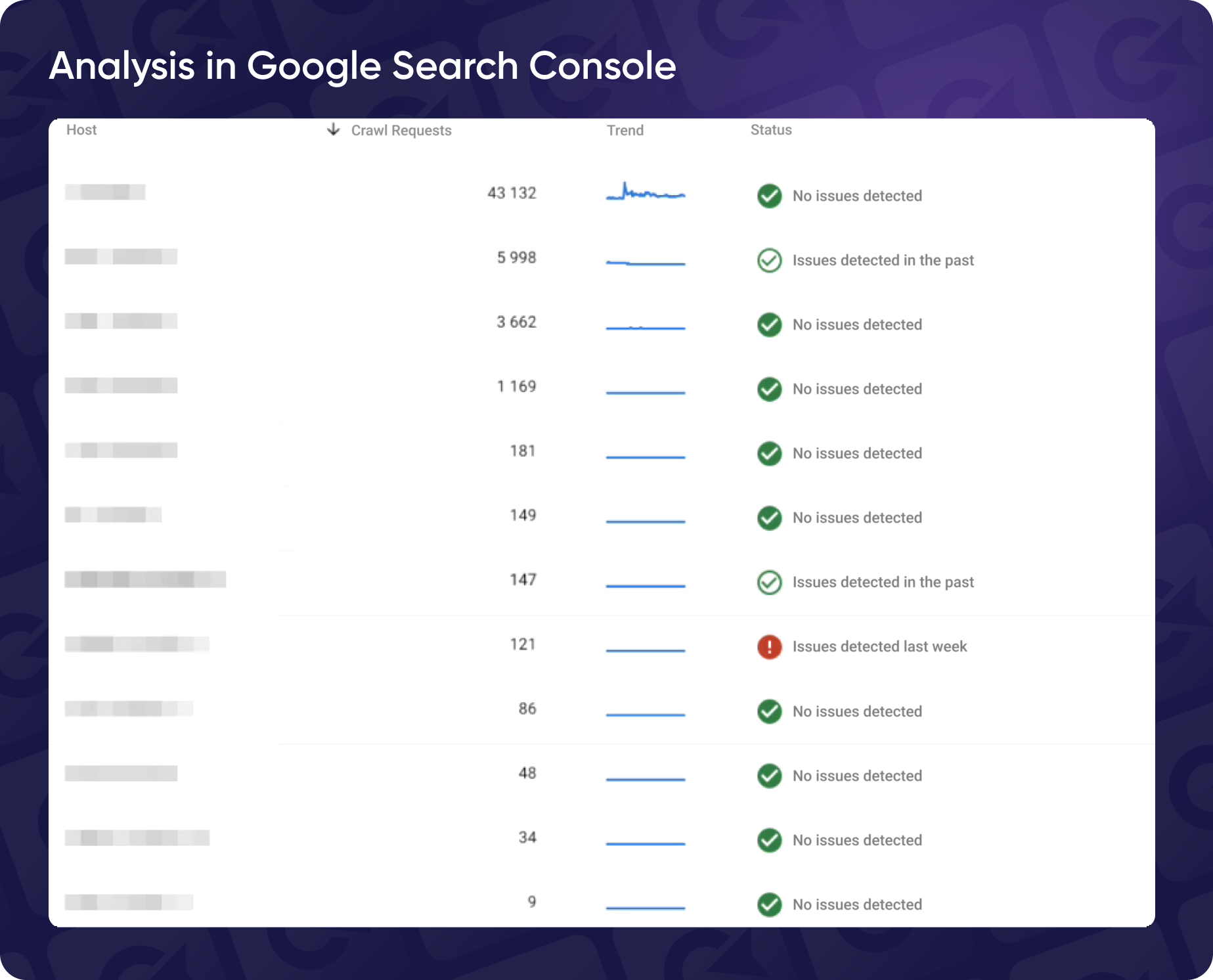
Another common issue comes from larger websites using different domains for smoother content delivery (think images hosted on a CDN.) Search bots do need expanded access to crawl those images, and granting that access allowed Yaroslav to see how much the bots interacted with the said CDN.
Digging further, Yaroslav says that a really common mistake in Google Search Console analysis is overlooking which bots are scanning your site. For instance, if the AdsBot is more active than the Mobile or Desktop bot, it might signal that your site isn't optimized for regular Google search.
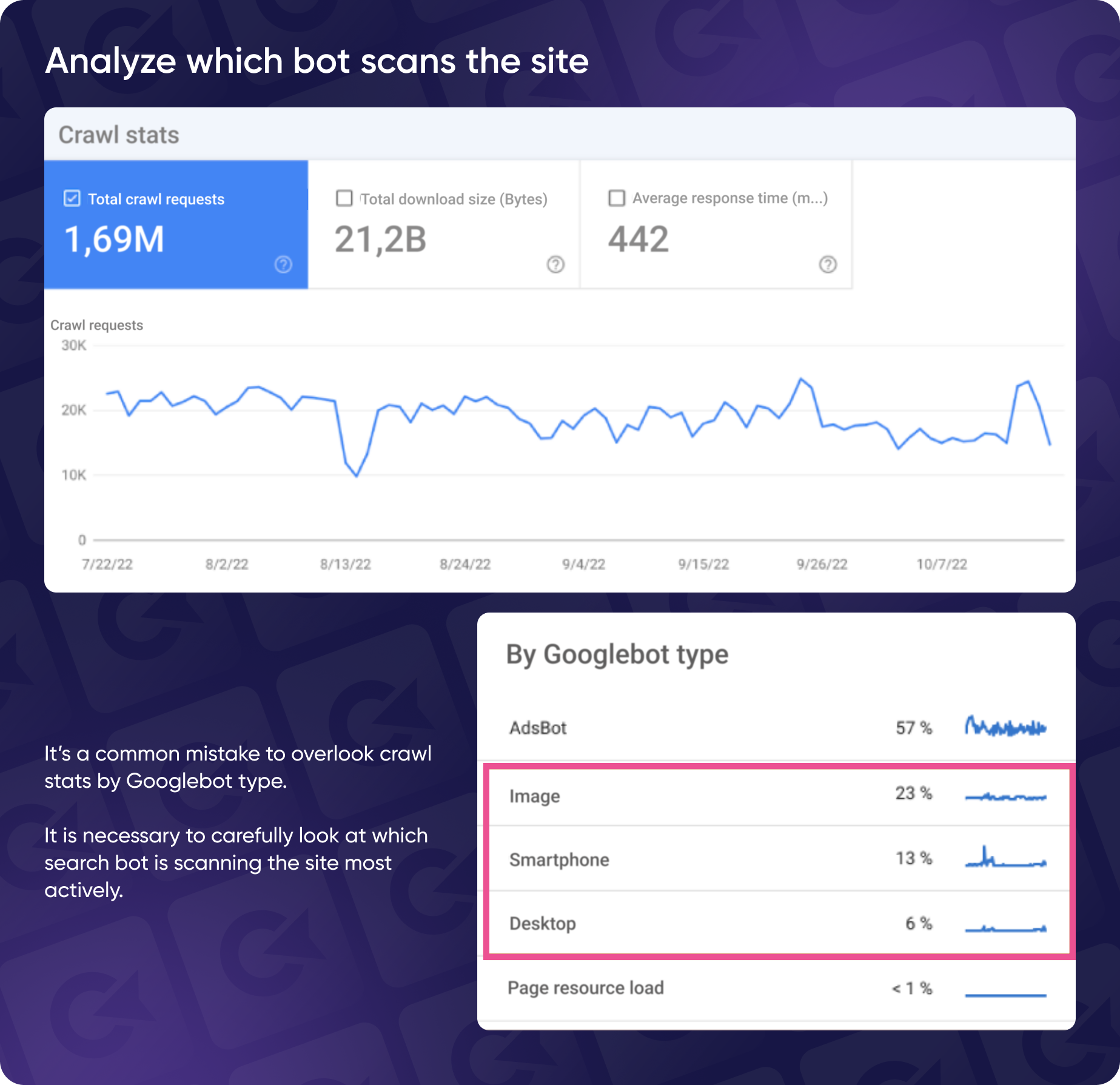
Always check which bot is crawling your site and adjust your strategy accordingly. In this case, the Mobile bot was underutilized, indicating poor crawl budget management.
Jet Octopus
Up next in our log analysis toolkit is Jet Octopus. With its built-in crawler and real-time tracking, you can get an hour-by-hour look at how your site is behaving. Plus, it syncs up nicely with Google Search Console, giving you a full picture of what the crawler is finding, what’s in your logs, and what’s happening in the Console—like a 360-degree view of your website.
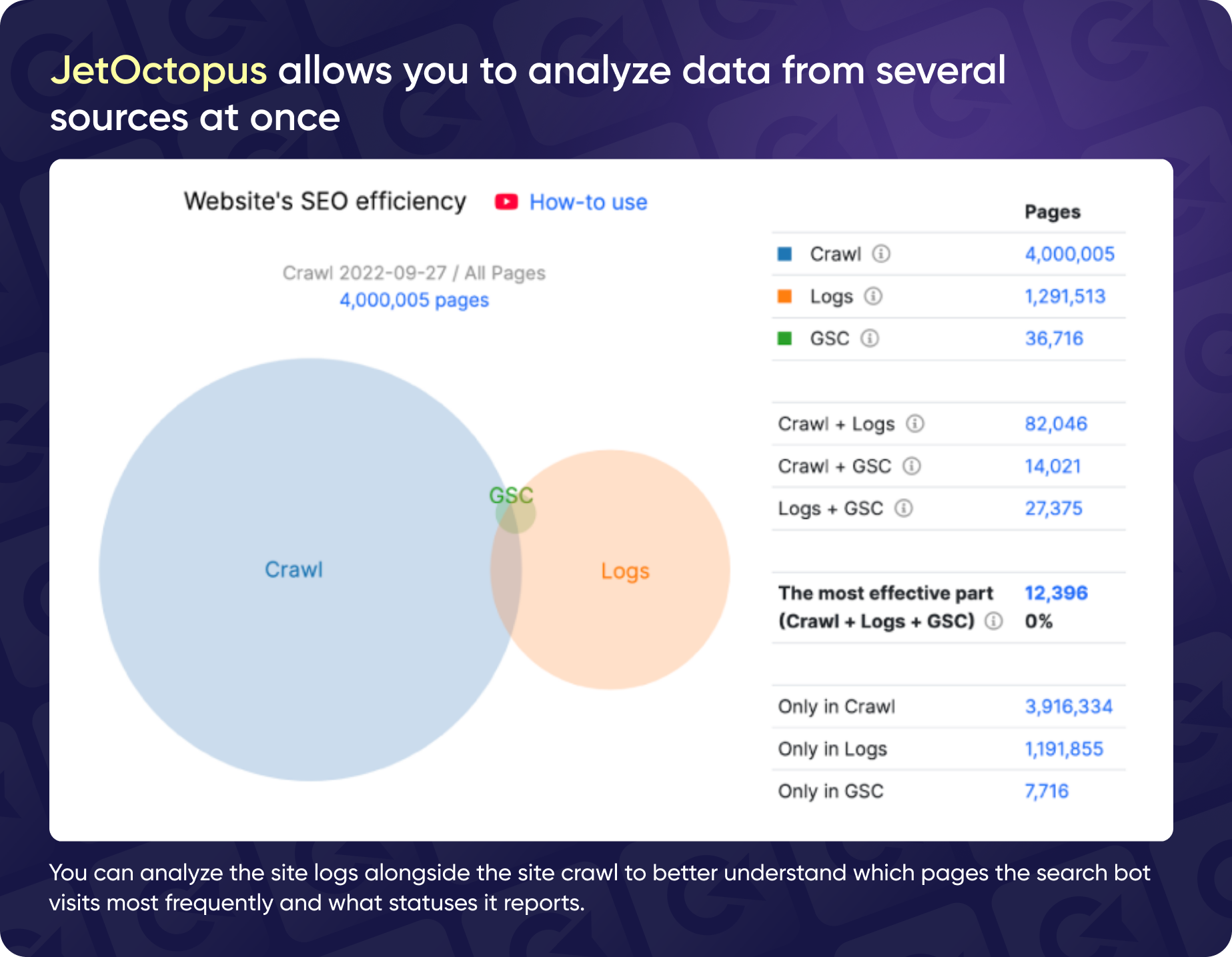
The Euler diagram shows that the Jet Octopus crawler found four million pages, logs recorded only one million, and the Console displays 36,000 pages.
An FYI: Jet Octopus isn't a Googlebot clone. In fact, it can spot pages that Googlebot might miss. So while it’s super useful, don’t forget to double-check its findings with your actual logs for the full story on how bots are navigating your site.
Screaming Frog Analyzer
Next up is Screaming Frog Analyzer (you probably have already used it at some point). Same as Jet Octopus, it let's you combine crawl data with the logs, allowing for a full view of how bots interact with the website. The only difference would be having fewer flashy graphs and animations in contract to Jet Octopus.

We won’t go too deep into either tool here since they both pack a ton of features that could each fill a whole presentation. Just know that they’re both great options, offering unique insights. It’s all about picking the one that fits your needs best.
Excel + Looker Studio
Don't worry if you don’t have access to tools like Jet Octopus or Screaming Frog. You can still analyze your logs effectively with Excel and Looker Studio (a recently rebranded Data Studio).
Here’s how to do it:
1. Collect the Data
Looker Studio gives you insights on keywords, pages, impressions, and average positions. Start by exporting your logs and Looker Studio data into Excel.
2. Process & Organize Data
In Excel, create a pivot table to combine the data from your logs and Looker Studio. This will help you organize and analyze how your pages and keywords interact with each other.
3. Conduct Analysis
Use the pivot table to explore impressions, average positions, and visit frequency. This lets you spot trends and issues, like pages with low visibility or keywords that need a boost.
By combining the two, you can create a detailed picture of your site’s performance, similar to what specialized log analysis tools offer. It's just a bit more of manual work.
How to Optimize Crawl Budget & Speed Up Website Indexation
Now that you know how to analyze website logs and determine whether you're in need of crawl budget optimization, it's time to learn how to do it. Below are some crawl budget optimization strategies and methods Yaroslav used in his real-life case study.
Let's dive in!
Understand How Search Engines See Your Content
The most crucial aspect is understanding how search engines perceive the content on your pages. The well-known rule that "content is king" holds, but there are nuances to how search engines evaluate content.
To check this, you can use the Rich Results Test.
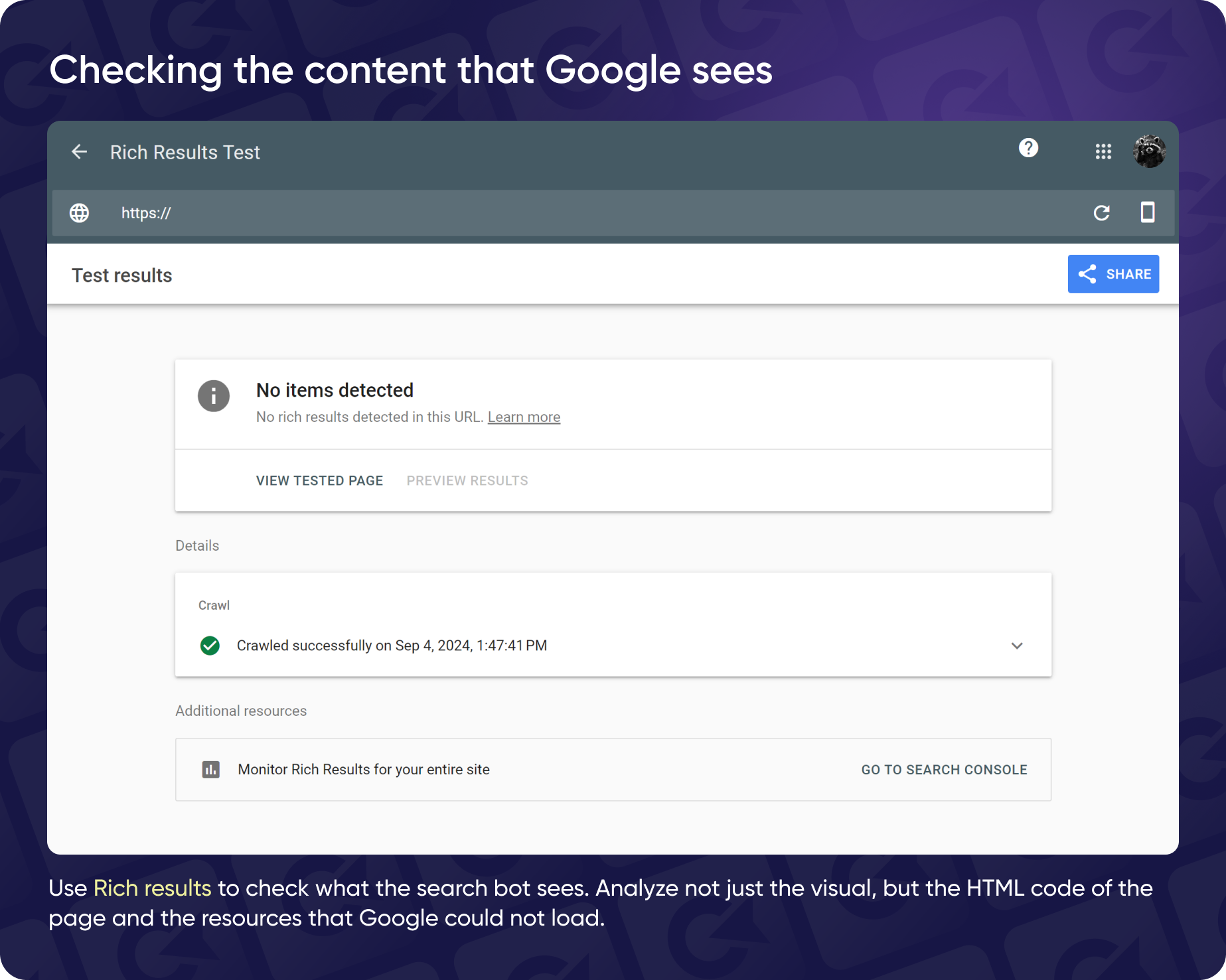
The Rich Results Test is mainly used to check and validate the markup on your pages, but it also offers a glimpse into how search engine bots view your content. The problem is, many specialists focus too much on visual representations rather than digging into the actual code behind it.
Analyze HTML Code
Instead of relying solely on screenshots or visuals, it’s important to analyze the actual HTML code. You can copy the HTML that search engines see and paste it into a text editor like Visual Studio Code or Notepad. This way, you can check how links, images, and other elements are presented to search engines.
Common issues to look for:
- Link Visibility
Make sure your internal links aren’t hidden or missed due to JavaScript rendering issues. If a section of internal links is dynamically loaded with JavaScript, search engines might not see them if they’re not properly rendered.
- Image Loading
Many websites use lazy loading to improve page speed, but it can cause problems if search engines don’t load those images. Double-check that lazy loading isn’t preventing search engines from indexing your images.
Use API for Faster Indexing
Another effective way to speed up indexing is by using indexing APIs. For example, the Google Indexing API lets you submit URLs directly to search engines. Refer to the API documentation for detailed instructions on setting it up and integrating it with your site.

For example, if you need to quickly index a batch of pages, you can submit up to 200 URLs at a time using the API. This can be especially useful if you've recently closed a group of pages from indexing and want to notify search engines of these changes — this is what was done with the client who had 12 unindexed pages.
Focus on Frequently Crawled Pages
When analyzing the number of visits, you can observe how frequently different pages are accessed. Understanding which pages are visited by search engine bots often helps you identify opportunities to enhance indexing for less visible or poorly indexed pages.
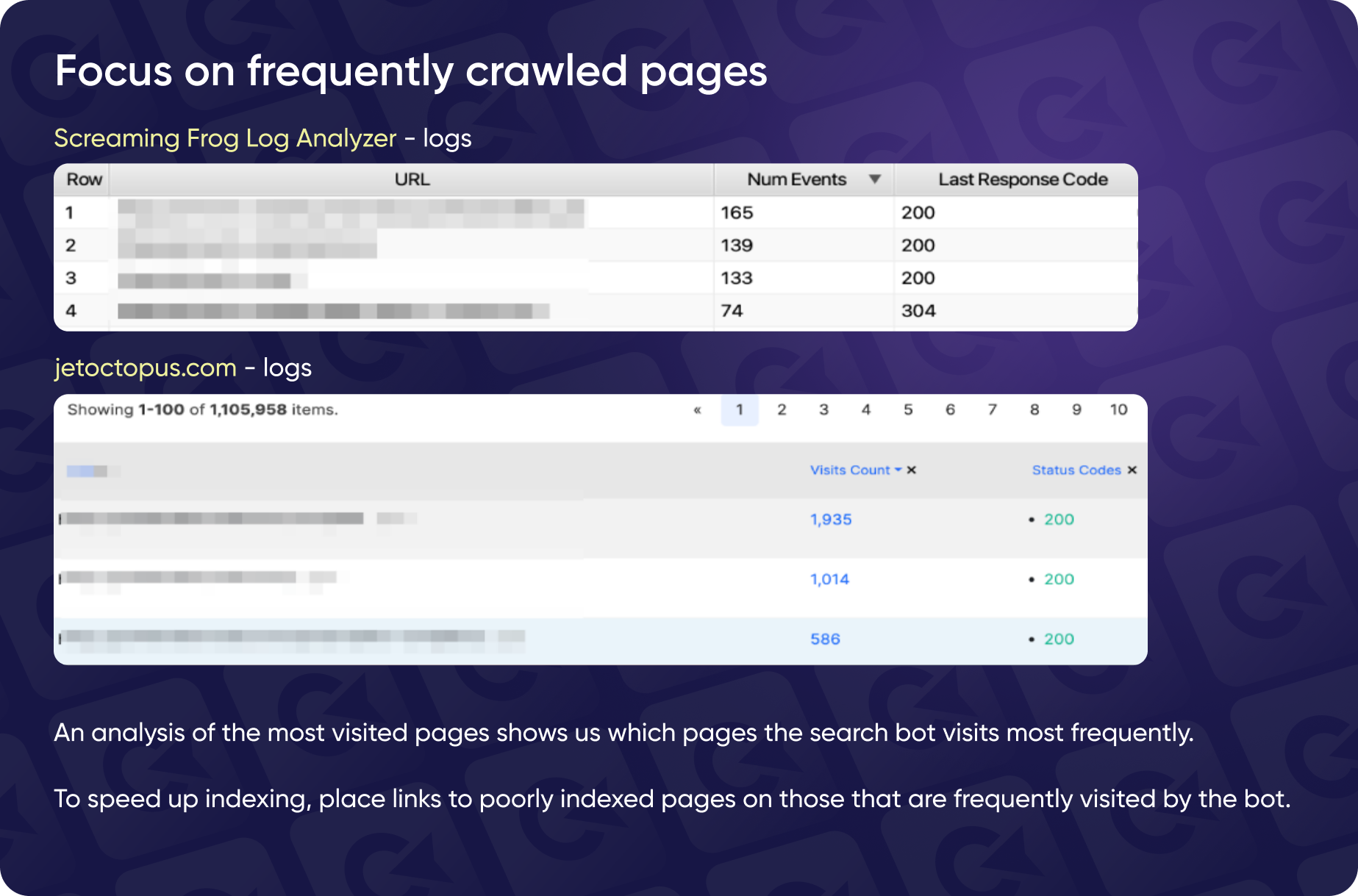
If a page receives frequent visits, consider adding links to pages that need better indexing. Yaroslav has tested this strategy multiple times and found it to be effective.
Avoid Irrelevant Linking
Mske sure your internal linking makes sense. If you have a category like "Mobile Phones," don't link to unrelated stuff like "Garden and Home" on that page. It will water down the page's relevance and focus. Link to related content, like specific phone brands or other filter options. Not only it will speed up your indexing; your customers will be thankful, too.
Dealing With Error Codes & 404 Pages
Another common approach is managing "Not Found" 404 error reports. Googlebot has a built-in "fool-proof" system that periodically checks pages that were once indexed but are no longer available. It revisits these pages to ensure they still return a 404 error, confirming they're truly gone.
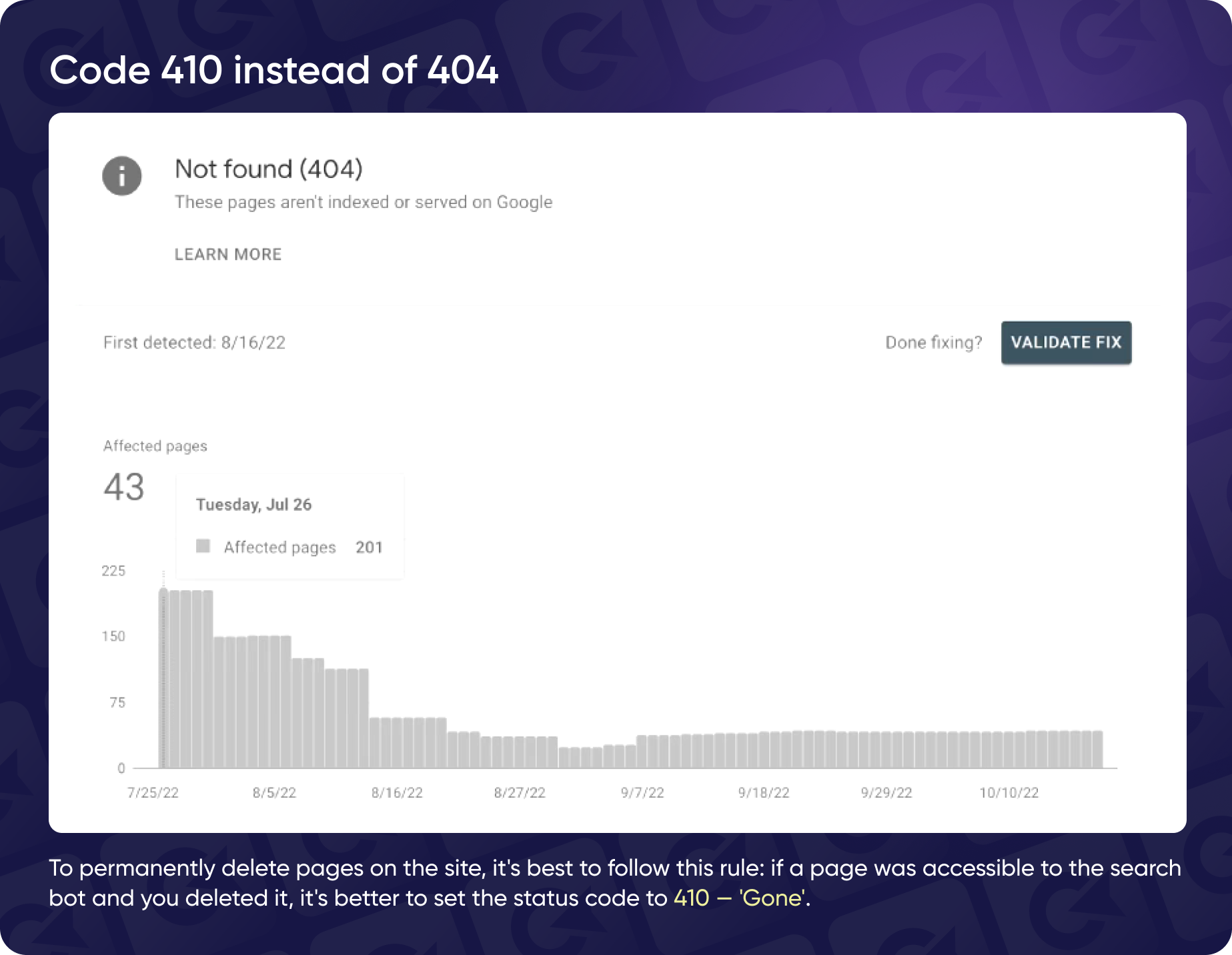
It's handy if you have a large site with user-generated content, where users can add or remove items or pages. If a significant page is accidentally deleted or removed, Googlebot keeps track of it, and if the page is restored, traffic can bounce back.
But if you know for sure that certain pages are no longer needed and want to prevent the bot from wasting resources, do the following:
- Check Links
Start by using a link checker tool like Ahrefs to identify if any links are pointing to 404 pages. - Redirect Valuable Links
If there are valuable links, implement a 301 redirect to a relevant and related page or category; this way, you won't lose link equity and traffic. - Use 410 Status Code
If you're 100% sure you don't need those pages, use the 410 status code. Unlike the 404, the 410 means that the page is permanently removed. Googlebot will double-check it a few times and then stop crawling it altogether.
Use Last-Modified HTTP Header
Another way to optimize your crawl budget is to use the Last-Modified header, which helps search engines determine if a page has been updated since the last crawl. When a bot crawls a page, the server provides an HTTP header indicating the date and time of the previous update.
When the bots revisit the page, it sends a request with an If-Modified-Since header containing the last modification date. The server compares the dates and responds with a 304 (Not Modified) status code, telling the bot that it doesn't need to download the content again.

To check if your Last-Modified header is set correctly, you can use any HTTP checker (like Google's PageSpeed Insights.) A great example of a proper Last-Modified header implementation is Wikipedia.
Utilize ETag Header
Another header similar to Last-Modified is the ETag header. While Last-Modified uses a date and time to indicate when a page was last changed, ETag works a bit differently.
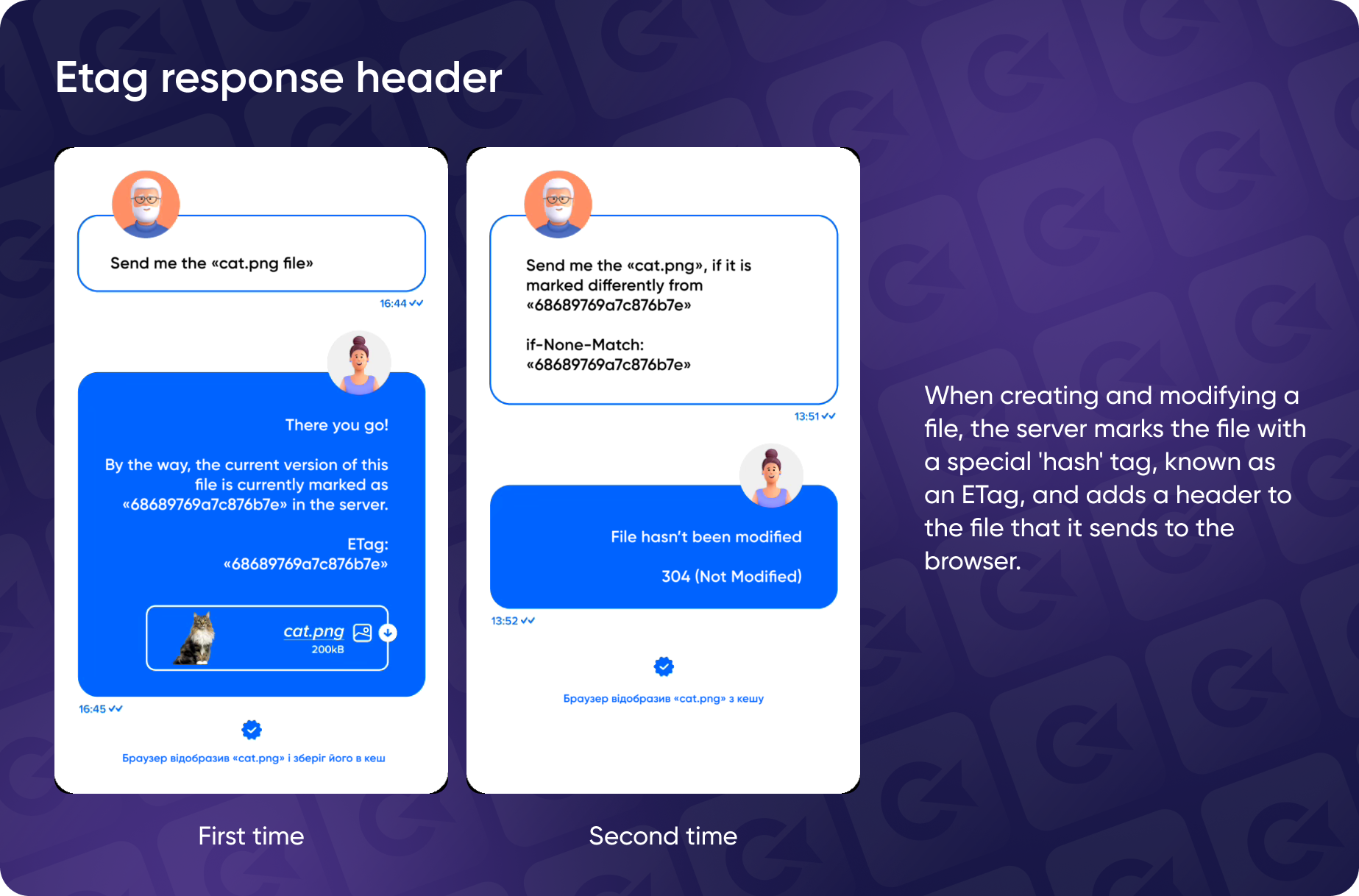
The ETag (Entity Tag) header provides a unique identifier (usually a hash or some form of token) for the current version of a resource. Instead of a date, ETag uses a string that represents the page's content.
When the server receives the request, it compares the client's ETag value with the resource's current ETag value. If the values match, this means the content has not changed since the last request, and the server responds with a 304 (Not Modified) status. It they don't match, the server sends the updated content and a new ETag.
Beware: implementing ETag headers requires additional server-side storage as this means managing a lot of meta data (especially for larger sites).
Implement Internal linking
Another effective way to optimize crawl budget is through proper internal linking. Everyone is familiar with the concept, yet many specialists often overlook it and fail to set up internal links correctly.

First, make sure that search engine bots can see your internal links (you can do so by using tools like Rich Results). Pay attention to keeping them relevant, visually appealing, and user-friendly. A great example of proper internal linking is Booking.com.
Some common types of internal linking are:
- Category and Subcategory Pages
For example, you have a main category for mobile phones and then various subcategories for different types of phones. This helps users navigate through related products easily. - Tag Blocks
Use keyword tags related to product filters. For example, if a product is a mobile phone from a specific brand, link to pages with all phones from that brand or related filters. Look at large e-commerce sites to see how they manage their internal linking through filters. This method helps with SEO and improves user navigation by linking directly to relevant filters and products. - Anchor linking in texts and blogs
It's effective but should be used wisely. Avoid overloading every third word with keywords. While blogs drive informational traffic, they also serve as an opportunity for internal linking. You can either manually find and insert keywords or use tools like Semrush to automate the process. - Filter Pages in Categories
This is common in e-commerce sites. Make sure to handle filter pages carefully, mainly if they are not meant to be indexed. For example, if a search engine bot encounters a filter combination that doesn't need indexing, consider hiding these filters from the bot using JavaScript to prevent it from wasting resources on these pages. - Geographical Internal Linking
This trend involves creating separate pages for different cities or regions. It helps target specific locations and attract local traffic. However, this approach should be tested and optimized to see what works best for your site. - HTML Sitemaps
This classic method involves creating a page listing all accessible pages for indexing. However, an HTML sitemap can consume significant resources on very large sites. It might be better to focus on narrow pages and filter pages for sites with millions of pages instead of a full HTML sitemap. For instance, a site with 150 million pages had a sitemap that caused the bot to prioritize it over the homepage, leading to inefficiencies. - Hub Pages
These pages are designed to serve as central points for related content. They can be used to attract traffic and organize links to other pages. Hub pages often appear in the breadcrumb navigation, efficiently guiding users and search bots to related content.
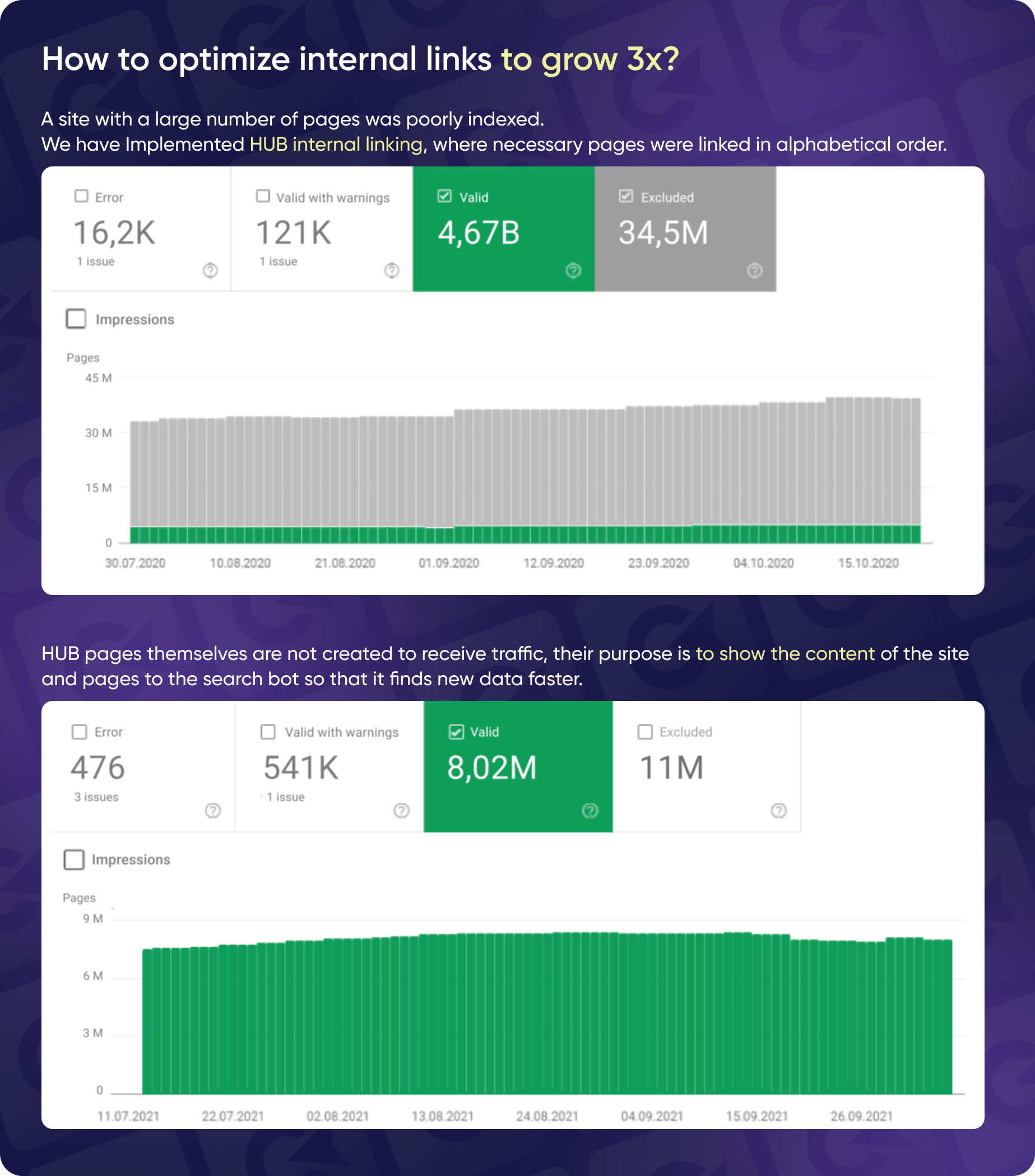
Based on an example from one of Yaroslav's clients that you can see on the screenshot above, hub pages are one of the best ways to improve indexing. The website he was working on was similar to You Control, which lists registered businesses and other entities.
Initially, the website had:
- 34 million pages that were excluded from indexing
- 4 million pages that were indexed
- Various other errors.
Below, is the case study from Yaroslav's POV.

The first step we took was a thorough audit to tackle common issues like duplicate content and other standard errors. The game-changer, though, was setting up hub pages. Given the site’s focus on business registrations, we organized the content alphabetically—creating a hub page for each letter that listed businesses starting with that letter.
These hub pages weren’t just about driving traffic directly. They acted like a map, showing bots how many pages were under each category.
Here’s what we saw from this approach:
- Increased Indexed Pages
The number of indexed pages doubled from 4 million to 8 million. - Reduced Excluded Pages
Pages excluded from indexing dropped from 34 million to 11 million, showing we’d successfully filtered out unnecessary content. - Traffic Growth
Traffic, which had been on the decline, saw a sharp increase. The traffic graph clearly showed a rise after implementing our internal linking strategy.
If your site has a similar structure or content, setting up hub pages and improving internal linking can make a big difference. It helps search engines understand your site better and can significantly boost your traffic and indexing efficiency.
Acquire Quality Backlinks
Getting quality backlinks was another key factor in our case. One thing to keep in mind is that the backlinks need to be indexed to be useful.
We won't dive too deep into the whole "backlinks are king" thing here, as you probably already know that. Just a friendly reminder: if you need top-notch backlinks, check out Collaborator. Not our words, but Yaroslav's!
Case Study: Growing The Website 3X
In our project's beginning, we dealt with a massive website containing over 20 million pages. These pages were primarily generated by product categories following specific rules, leading to a bloated site structure.
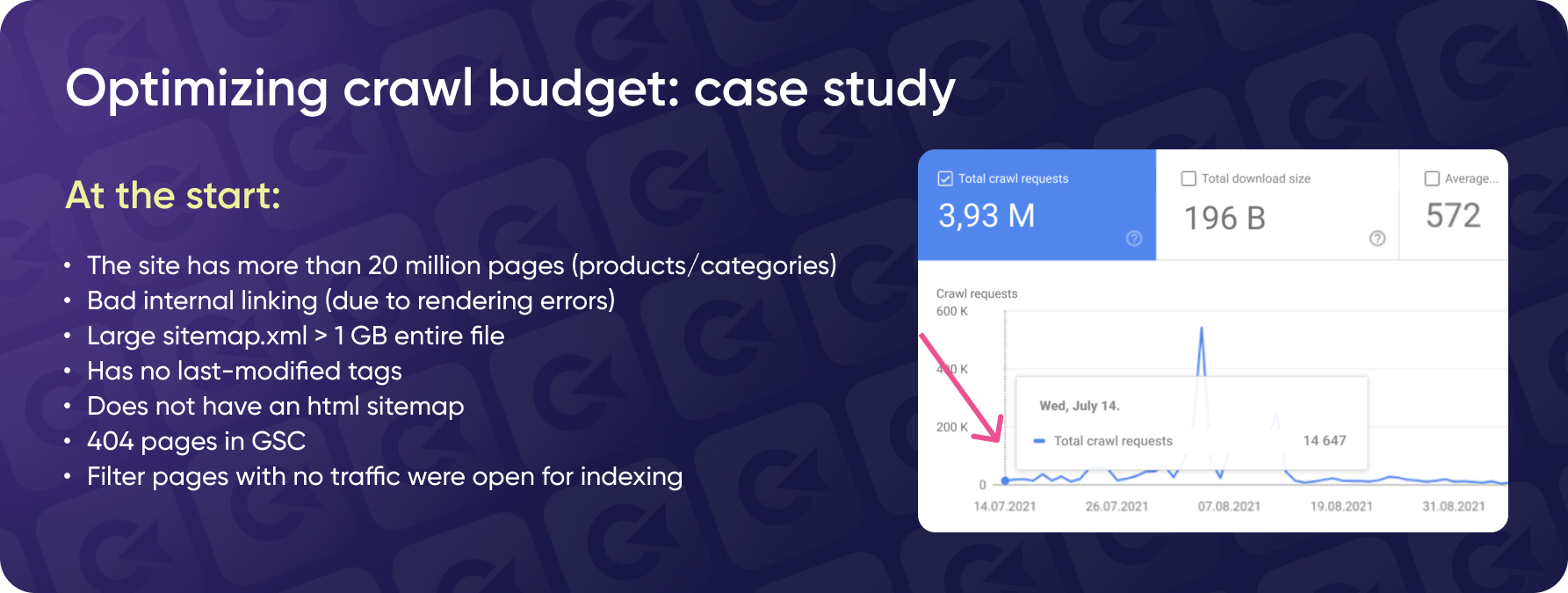
The main issues included:
- Poor internal linking
The website's internal linking structure was ineffective, making it difficult for search engine bots to navigate and index the site.
- Oversized sitemap.xml
The sitemap was over one gigabyte in size, far exceeding the recommended limit of 50 MB and 50,000 URLs. This made it impossible for search engine bots to process the sitemap effectively.
- Lack of essential SEO elements
The site was missing key SEO elements such as a "last-modified" tag, an HTML sitemap, and proper handling of 404 errors.
- Outdated and irrelevant pages
The website contained numerous filter pages that were no longer relevant, yet they remained open for indexing, contributing to the site's bloat.
Step-by-Step Implementation
- Audit and Internal Linking Fixes
We began by conducting a comprehensive audit of the site's internal linking structure using tools like Rich Snippet Tools to analyze the HTML code. We discovered that a critical block of internal links, which should have been displaying all product links, was not rendering correctly. We fixed this issue, ensuring the search engine bots could now access and navigate these links effectively. - Sitemap Optimization
The original sitemap was far too large, making it difficult for search engine bots to crawl. Following best practices, we compressed the sitemap into smaller, manageable archives. This allowed the bots to download and process the sitemaps more efficiently. - HTTP Response Code Optimization
We optimized the handling of HTTP response codes on the site. We implemented a 304 status code for unmodified pages, indicating that the content had not changed and did not need to be re-downloaded by the bots. - HTML Sitemap and Section Indexing
We created a new HTML sitemap that highlighted all the sections of the site that needed to be indexed, ensuring that the most important content was easily discoverable by search engines.
We also started closing sections of the site that had not generated traffic in the last 12 months. Pages that were no longer relevant were either removed or marked with a 410 status code), signaling to search engines that these pages should be deindexed. - Google API Integration
We integrated Google API to manage the indexing of new and existing pages more effectively. For instance, when a client rolled out hundreds of new categories, we used the API to upload these new pages directly to Google, ensuring they were indexed promptly.
Additionally, we used the API to inform Google about pages that had been removed or closed from indexing, speeding up the process of deindexing irrelevant content.
Results
The steps we implemented significantly improved the site's crawl budget and overall SEO performance.
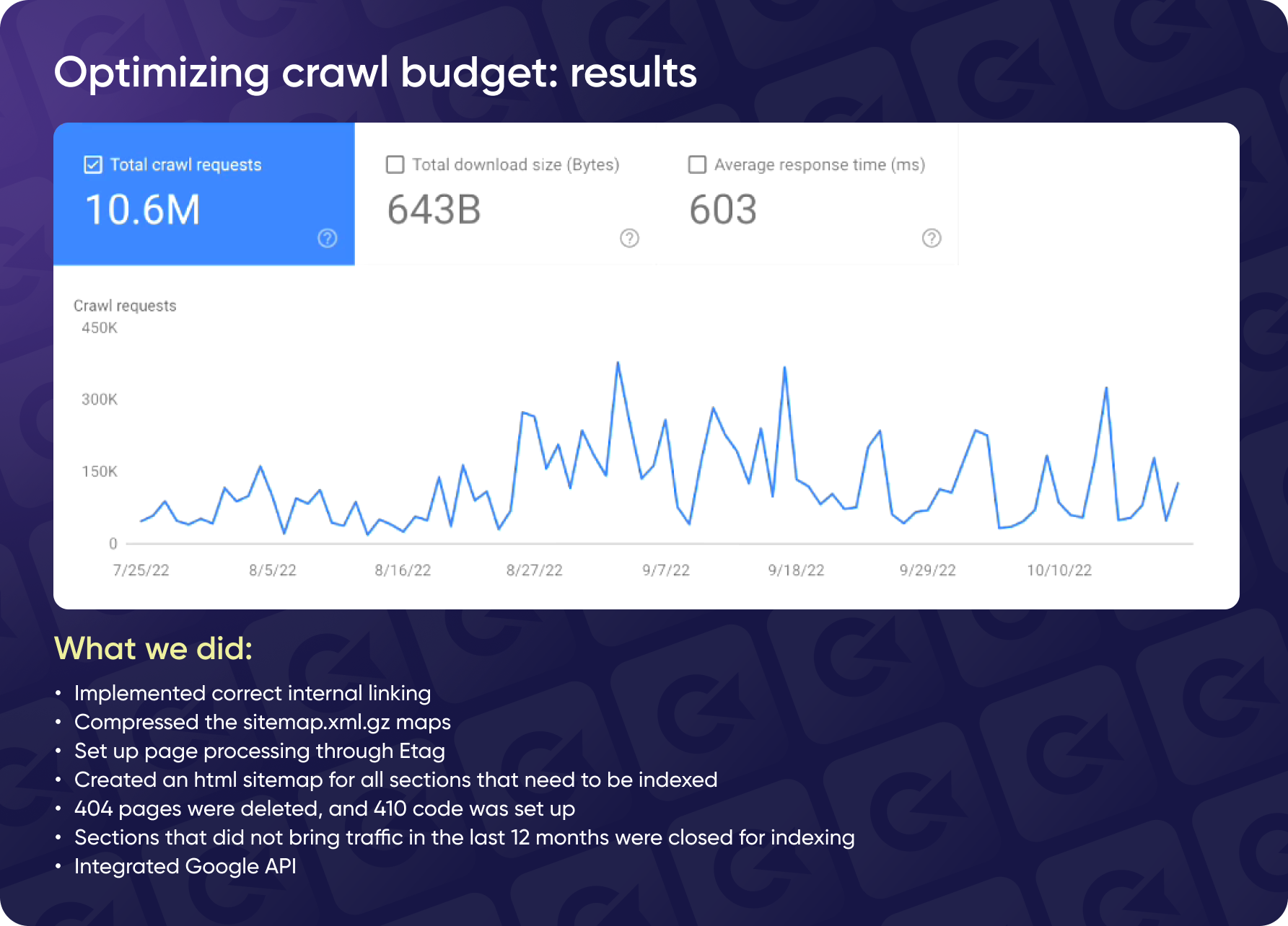
- Improved Crawl Budget.
The search engine bot now indexes around 100,000 pages daily, with occasional spikes exceeding 300,000 per day, depending on the site's updates and structure. This is a substantial improvement from the previous situation.
- Enhanced Search Bot Activity.
Thanks to the optimized internal linking and sitemap structure, the search bot visits the site more frequently and can now discover and index more pages.
- Reduction in Irrelevant Pages.
By removing outdated and irrelevant pages and improving the site's overall structure, we reduced the site's bloat and improved its overall SEO health.
This case study demonstrates the importance of a comprehensive approach to optimizing a large website. Through careful auditing, strategic fixes, and the use of tools like Google API, we significantly improved the site's indexation and crawl budget, leading to better visibility and performance in search engines.
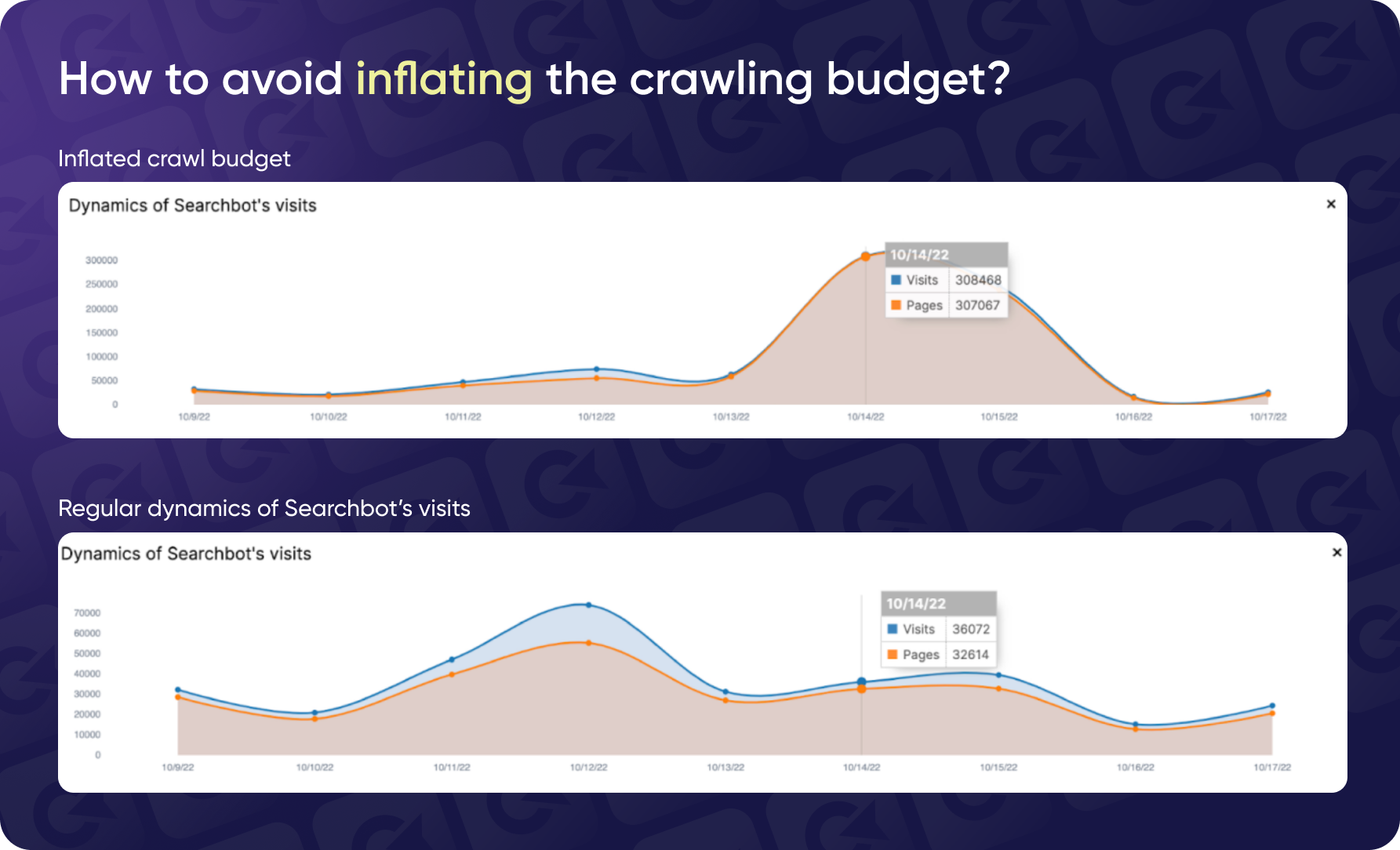
How To Avoid Spam Attacks & Inflated Crawling Budget
We encountered a serious issue while managing a website with over 150 million pages a month ago. Despite the number of pages, the website had a daily crawl budget of only around 100,000 pages, which is insufficient for a site of this scale. After implementing some initial recommendations, we observed a steady increase in the crawl budget over eight months. However, one day, the site experienced an unusual spike where the search engine bot crawled almost 500,000 pages in a single day.

Upon closer examination, we discovered that this spike was not due to legitimate pages but was caused by a spam attackthat led the bot to a massive number of non-existent pages. The URLs in question were not generated by the site's CMS, raising red flags and prompting a deeper investigation.
Step-by-Step Response
- Identifying the Issue
We first analyzed the logs and found that the sudden spike in crawl activity was directed toward a suspicious URL that led to the homepage. The URL did not resemble any pattern generated by the site's CMS. We confirmed with the site owners that they had not created such URLs, indicating that this was likely an external attack designed to waste the site's crawl budget. - Initial Damage Control
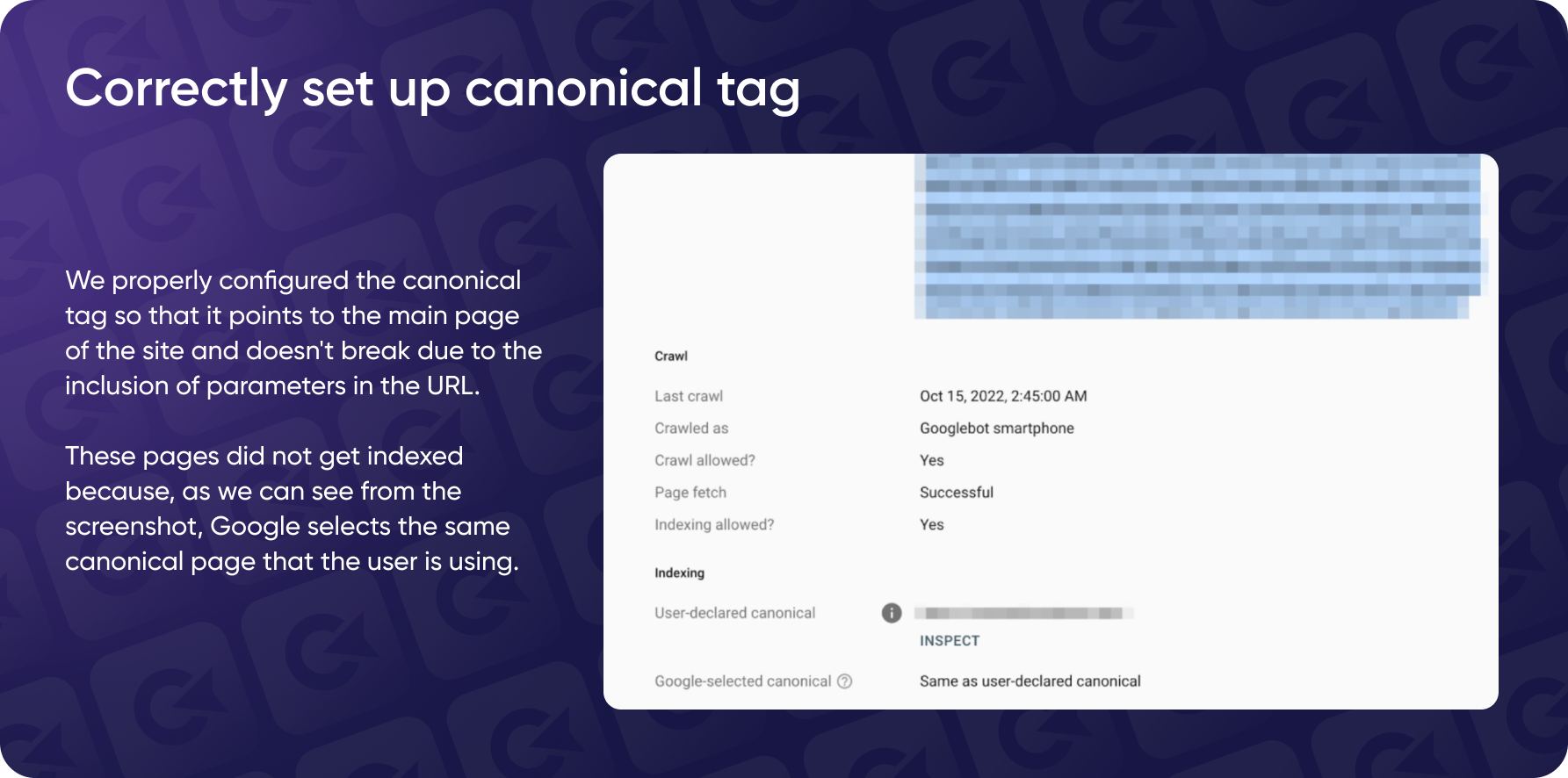
The first line of defense was examining the spam URL's canonical tags. Fortunately, the site had a canonical tag pointing to the homepage, which partially protected the site by preventing the bot from indexing these irrelevant pages.
![Representation of correctly set up canonical tags]()
- Analyzing External Links
Suspecting that the attack involved external links, we reviewed the site's backlink profile using tools like Ahrefs and Google Search Console. This revealed a pattern of toxic backlinks, likely part of the attack strategy.
We promptly disavowed these harmful links to prevent them from affecting the site's SEO and crawl budget further.
- Applying a 410 Status Code
To prevent the bot from continuing to waste resources on these non-existent pages, we implemented a 410 status code for the spam URLs. This status code tells the bot that the page no longer exists, helping to ensure that it does not attempt to crawl these URLs again. - Blocking the Spam Parameter
The spam attack involved a specific URL parameter which was being used to generate these fake URLs. We updated the robots.txt file to block this parameter, ensuring that no further attempts to exploit this vector would be successful.
Results
After blocking the spam URLs and applying the 410 status code, the site's daily crawl rate returned to normal levels, focusing on legitimate pages. By disavowing harmful links and blocking the spam parameter, we prevented potential long-term damage to the site's SEO and ensured that the crawl budget was not being misused.
The steps taken not only resolved the immediate issue but also fortified the site against future attacks of a similar nature.
Q&A
Could you summarize the factors affecting the crawl budget?
First and foremost, analyze server logs to see where the search bot is going. Assess how much resource is spent on pages that are excluded from indexing and other factors. If you have filters and combinations of pages you want to test, formulate your theory and then check the logs to see how the crawl budget is being utilized. This will help you identify what needs improvement and what doesn't.
Moving a site to a new domain with a 301 redirect but without indicating the move in Google Search Console. How can you speed up indexing?
You can use the API to notify Google of a new site. Additionally, acquiring backlinks can significantly help. You can also ping the sitemap; creating and pinging a sitemap will alert Googlebot to the new pages. However, the most effective approach will likely use the API combined with a strategic backlinking campaign rather than just indiscriminately adding links.
What is the largest site you have analyzed using Jet Octopus in practice?
The largest site I've analyzed was around 100-150 million pages. The Jet Octopus tool is divided into the crawler and the log analyzer. While the log analyzer handles large sites well, the crawler struggled with such a massive site—it took about three weeks to scan, and even then, it wasn't fully completed. So, the crawler doesn't handle extremely large sites very efficiently, but working with logs is quite manageable.
If you have a new domain with two million pages, what is better for the crawling budget: (1) moving one million pages to a separate new domain or (2) splitting the pages between two subdomains of the same domain? Is it worth doing this, or should you avoid such actions?
If your content is well-generated and high-quality, you shouldn't have crawling issues. Instead of splitting domains or subdomains, focus on producing good content and managing your site's performance. Analyze how bots view your site, address any issues with duplicate content or unintentional script-generated pages, and fix any errors. If indexing problems persist, use APIs and build quality backlinks to improve visibility. The key is to optimize your content and site structure rather than trying to manipulate crawling through domain splits.
Is it true that pagination can consume a large portion of the crawling budget? What would you recommend?
Pagination is indeed a debated topic. There are two main schools of thought: one advocates for blocking pagination from indexing, while the other recommends allowing it. I belong to the latter camp. Here's why: if you have a diverse inventory, such as mobile phones, different pagination pages will show different products. These pagination pages can be unique and should be indexed. Google's documentation suggests using canonical tags on these pages to point to themselves, helping Google understand the structure.
When implementing pagination, consider how Googlebot interacts with it. For example, some sites provide a full set of pagination links (first, last, and intermediate pages), making exploring easier for bots. In contrast, some sites only show the next page link, which can limit the bot's ability to crawl efficiently.
From my experience, a site with comprehensive pagination allows Googlebot to crawl significantly more pages than sites with limited pagination options. For instance, on one site, the bot crawled 50,000 pagination pages per month, while on a much larger site, it only crawled 86 pages. This suggests that comprehensive pagination allows for better exploration of content.
So, I recommend keeping pagination open, monitoring how Googlebot interacts with it, and analyzing logs to see how often and which pages are being crawled. This will help you optimize pagination and ensure effective crawling.
What do you think about using log analysis to identify pages where bots frequently visit and then adding automatic internal linking blocks to non-indexed pages? Will this work?
I think it could work. This strategy might be particularly effective if you're working with a site in a less competitive market, such as in Ukraine. By placing automatic internal links on frequently crawled pages that direct to non-indexed pages, you help ensure that those pages are more likely to be discovered and indexed.
The key is to make sure that your automatic linking does not dilute the focus of your pages. For example, if your site is about mobile phones and mixes unrelated topics like gardening, it might confuse the intent and negatively impact SEO.
Why is a site indexed without pages in Google's cache or saved?
If a site is indexed but has no pages in Google's cache, the issue might be that the no-cache attribute is set, which tells Google not to cache the pages. If that's not the case, it's hard to determine the exact reason without further details.
How long does analysis typically take? How often should you review logs, and how can you inform people about this?
The time required for analysis depends on the size and complexity of the project. When a new, especially large, project comes in, starting with a thorough audit is crucial, which can be quite time-consuming as you get familiar with the site's structure and data. After this initial phase, establishing a regular monitoring routine is essential to stay updated on site performance and emerging issues. First, checking logs more frequently, such as every week, can help you catch issuesearly and understand the site's crawling behavior.
As you become more familiar with the site, you can adjust the frequency of checks based on its stability, potentially moving to monthly reviews if the site runs smoothly. Creating and testing theories about what you expect to see in the logs helps understand and optimize site performance.
You mentioned that bots revisit pages with a 404 error code. How do they find these pages in their database? I understand how they find them the first time, but if we remove these pages from the site, how do they return to them?
If a bot encounters a 404 page, it remembers that this page existed historically. Even if you remove it from your internal linking and there are no direct links to it anymore, the bot still has a record of it. It will keep checking those URLs because it's part of its historical memory. This is similar to how it handles 304 status codes; the bot first encounters a page and then checks back with the server to see if anything has changed. If not, it gets a 304 response.
In essence, the bot's memory includes these 404 pages, and it continues to revisit them because it has a record that they existed at some point. This is why you might see bots repeatedly checking these pages, even if they are no longer part of your site.
Recently, my site was hacked, and a virus was introduced. It generated 50,000 URLs. The virus has been removed, but the URLs are slowly disappearing from the index. Should I submit all these pages through Google API?
It could help to some extent. Yes, you can submit these URLs for removal through the API. Additionally, make sure you've properly handled the removal of these pages. Check how you closed these pages—if you used a robots.txt rule to block them, make sure that rule has been removed. If the pages were deleted, ensure they returned a 404 or 410 status code.
A 410 status code is preferable in this case because it indicates that the page is permanently gone, which might speed up the removal process. Also, you can use the Google Search Console's URL Removal Tool to request the removal of these pages. Note that this tool generally requires re-submission every six months to maintain the removal status.
Do you recommend closing links to filter pages through Google Search Console, or is it easier to do it by changing the tag from <a> to <label> or through spamming?
You can use any effective method you know to handle this. I suggested using Google Search Console as an option, but if you prefer using <label> or <options>, that's also fine. Even methods like hiding links through obfuscation can work. The key point is that the search bot should not see these links. Whether you choose to use spam techniques, hide them in <div> tags, or manage them differently, what matters most is ensuring that search bots do not have access to these links.
Conclusion
To sum it up, crawl budget optimization is not just something you need to do with an enterprise website — it can benefit websites of all sizes. To learn if it's something worth working on, you need to analyze your logs using tools like Google Search Console, Jet Octopus, Screaming Frog Analyzer, or even a combination of Excel and Looker Studio.
There are multiple (proven!) ways to optimize your crawl budget and prepare for possible spam attacks, with internal linking and hub pages being one of the key strategies to do so.
The Collaborator Team thanks Yaroslav for such an interesting and powerful case study. We wish Yaroslav and you good luck in your future SEO endeavors and the most successful link building deals🙂
Related reading