Робота SEO-спеціаліста часто вимагає опрацювання великої кількості даних із декількох сторінок водночас. Без автоматизації рутинних задач тут не обійтись. У цьому допоможуть xPath та регулярні вирази (RegEx) — інструменти для витягування та обробки даних із вебсайтів.
Завдяки xPath ви можете швидко парсити структуровані елементи сторінок, а RegEx допоможе знаходити та впорядковувати потрібну інформацію навіть у хаотичних даних. Ці методи не тільки заощаджують час, але й роблять процеси збору та аналізу інформації більш ефективними, дозволяючи зосередитися на стратегічних задачах.
Валерія Карпова, Head of SEO компанії Boosta, розповідає про можливості використання xPath, регулярних виразів та API для автоматизації SEO-задач. Практичні поради та конкретні приклади — у детальному конспекті із розгорнутими відповідями на важливі питання.
Відео та презентацію шукайте в архіві вебінарів👈
Усе, що ви хотіли знати про xPath та парсинг даних, RegEx та їх користь у роботі SEO-спеціаліста, а ще про API та що з цим всім робити — далі зі слів Валерії👇
xPath: що це і як працює в SEO

xPath (XML Path Language) — мова запитів, яка використовується для вибору вузлів із XML-документів, що також застосовується для HTML. У контексті SEO xPath є надзвичайно корисним інструментом для парсингу даних із вебсторінок.
Почнімо з того, що HTML-документ, як відомо, має деревоподібну структуру, де теги вкладені один в одного: стартовим завжди є тег <html>, він поступово розгалужується на <head> і вкладені у нього теги, <body> та інші внутрішні елементи. Завдяки xPath ви можете швидко «достукатися» до потрібного елементу на сторінці, до змісту конкретного тегу. Наприклад, якщо на HTML-сторінці є заголовок H1, xPath допомагає безпосередньо звернутись до цього елементу та отримати його текстове значення. Аналогічно для кожного елементу структури.
Основні можливості xPath:
- Трекінг змін на сторінках: дозволяє моніторити зміни на власних сайтах або сайтах конкурентів, зокрема, відстежувати оновлення контенту, заголовків, канонічних URL тощо.
- Парсинг даних: допомагає витягувати інформацію з вебсторінок, як-от ціни, характеристики товарів, зображення, відео або інші елементи, що є актуальними для ніші e-commerce.
- Перевірка лінків: дозволяє перевіряти наявність та активність лінків на ваш сайт на сайтах-донорах.
xPath широко використовується для виконання рутинних SEO-задач, адже надає швидкий доступ до ключової інформації.
Використання xPath для автоматизації SEO-задач
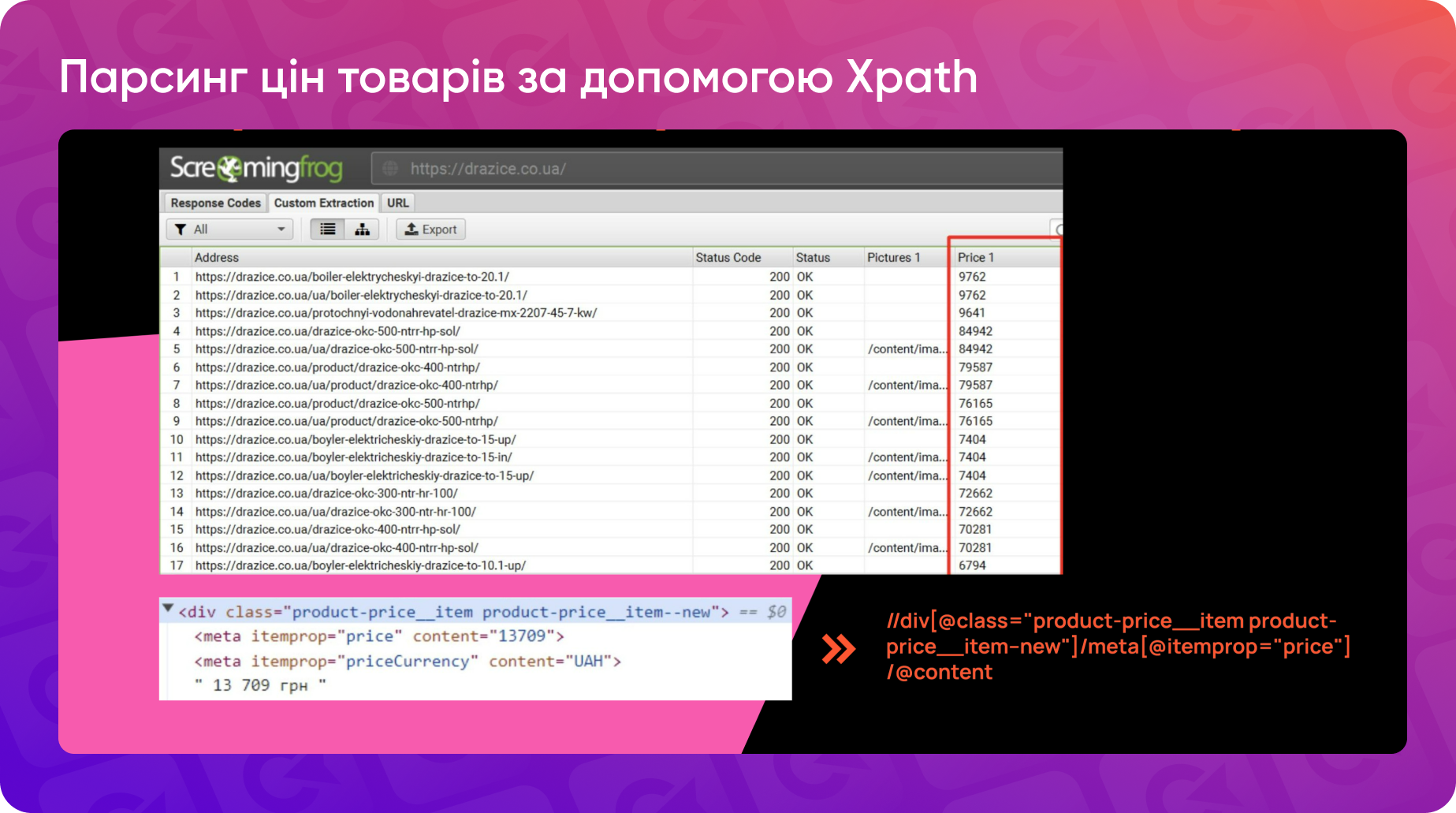
Щоб працювати з xPath, ви можете скористатися інструментами для перевірки коду сторінки. Для цього достатньо викликати контекстне меню в браузері (правий клік миші → «Перевірити»). Ця функція дозволяє побачити структуру HTML. Наприклад, для парсингу ціни товару в інтернет-магазині ви знайдете елемент div з класом class="product-price-item". Натиснувши на елемент і скопіювавши його xPath, ви отримаєте абсолютну адресу ціни в коді.
Однак, скопійований xPath може бути досить довгим і складним (оскільки він є абсолютною адресою ціни для HTML-документа, яка вказує всі вкладені теги), а його точність залежить від конкретної структури сторінки. Якщо структура зміниться (наприклад, додадуться нові елементи), ця конструкція xPath не спрацює.
Саме тому рекомендується будувати xPath самостійно, орієнтуючись на елементи, які є стандартними для вашого шаблону. Наприклад, якщо на всіх сторінках товарів є однаковий клас class="product-price-item", можна створити універсальний xPath, що працюватиме стабільно.
Для побудови універсальних конструкцій потрібно мати базове розуміння синтаксису xPath.
Основи синтаксису xPath прості:
- Запити xPath починаються з двох слешів //.
- Далі вказується назва елементу, який потрібно спарсити.
- Якщо потрібно звернутись до конкретного значення елементу (наприклад, тексту у класі), використовуються атрибути text(), @content тощо.

Побудова правильного xPath дозволяє не тільки ефективно парсити дані, але й створювати гнучкі рішення для автоматизації SEO-задач, що робить вашу роботу значно швидшою та ефективнішою.
Покрокова інструкція: як парсити дані з сайтів за допомогою xPath
Для парсингу даних зручно використовувати Screaming Frog або аналогічні інструменти.
Ось як це зробити:
- Відкрийте Screaming Frog, перейдіть у меню Configuration -> Custom -> Extraction.
- У вікні Extraction вкажіть назву колонки для вивантаження даних.
- Оберіть xPath як метод для парсингу і введіть потрібний вираз. Наприклад, //img/@src допоможе витягнути URL-адреси зображень. Щоб отримати лише URL без додаткових атрибутів, таких як alt-тексти чи розміри, використовується атрибут @src.
- Натисніть ОК і запустіть парсинг.

У результаті ви отримаєте колонку з усіма URL-адресами зображень або іншими даними, які вам потрібні. Цей метод простий і дозволяє швидко збирати потрібну інформацію.
Аналогічно можна використовувати xPath для парсингу цін товарів: будуємо xPath з орієнтацією на div певного класу. Використовуючи вираз //meta[@itemprop="price"]/@content, ви отримаєте лише числове значення ціни, без валюти чи додаткового тексту.
Цей підхід широко використовується для регулярного парсингу конкурентів або моніторингу власного сайту. Він дає змогу швидко отримувати потрібну інформацію та автоматизувати рутинні завдання.
Розширення Scraper для швидкого парсингу даних
Якщо ви використовуєте Screaming Frog і стикаєтеся із труднощами при налаштуванні формул xPath, або ж не отримуєте очікуваний результат, надійним помічником стане корисний інструмент — розширення Scraper для Google Chrome.
Після встановлення Scraper його легко знайти в контекстному меню, яке відкривається правою кнопкою миші. Використовуючи функцію Scrap Similar, ви отримуєте можливість швидко парсити вміст поточної сторінки та тестувати свої xPath-формули. Це особливо корисно для перевірки правильності складних виразів.
Після тестування формули і отримання потрібного результату, її можна використовувати для масового парсингу у Screaming Frog. Scraper — це зручний інструмент для попереднього тестування та оптимізації xPath перед масштабними завданнями, що допомагає уникнути помилок і заощаджує час.
Читайте також: Шпаргалка з XPath для SEO-спеціалістів
Функції IMPORTXML та ImportHTML: парсинг даних в Google Sheets
Формули xPath можна використовувати не лише в таких інструментах, як Screaming Frog, але й безпосередньо в Google Sheets або Excel для витягування даних із вебсторінок. Це особливо корисно, коли під рукою немає спеціалізованих SEO-тулів або потрібно швидко отримати інформацію з кількох сторінок.
У Google Sheets доступні дві функції для парсингу даних — IMPORTXML та ImportHTML:

Приклад використання IMPORTXML
Уявімо, що у вас є кілька URL, з яких потрібно витягнути значення тайтлів (title), заголовків H1 та описів (description). Функція IMPORTXML дозволяє це зробити, парсячи XML-структуру документа. Для цього:
- Вставляємо URL у відповідну комірку (наприклад, у комірку A2).
- Для отримання потрібних даних (наприклад, title сторінки) використовуємо формулу: =IMPORTXML(A2, "//title").
Аналогічно за допомогою xPath-виразів можна отримати заголовки H1 або метаописи.
Важливо: якщо URL зазначений у комірці, потрібно вказати на неї у формулі. Якщо ж ви вставляєте URL безпосередньо у формулу IMPORTXML, він має бути в лапках.
Функція IMPORTXML зручна для отримання повної структури заголовків (H1-H3) на сторінці. Хоча Screaming Frog та інші SEO-інструменти також виконують цю задачу, IMPORTXML дозволяє швидко порівняти структуру сторінки зі сторінками конкурентів.
Варто зазначити, що для великої кількості URL (наприклад, 10 000) цей метод є дещо повільним, а от для невеликих задач він працює ефективно та гнучко.
Приклад використання ImportHTML
Функція ImportHTML використовується для парсингу специфічних елементів, як от таблиці або списки зі сторінок. До того ж вона допоможе це зробити без спотворення структури.
Наприклад, для імпорту таблиці зі сторінки можна скористатися формулою =ImportHTML("URL", "table", 1):
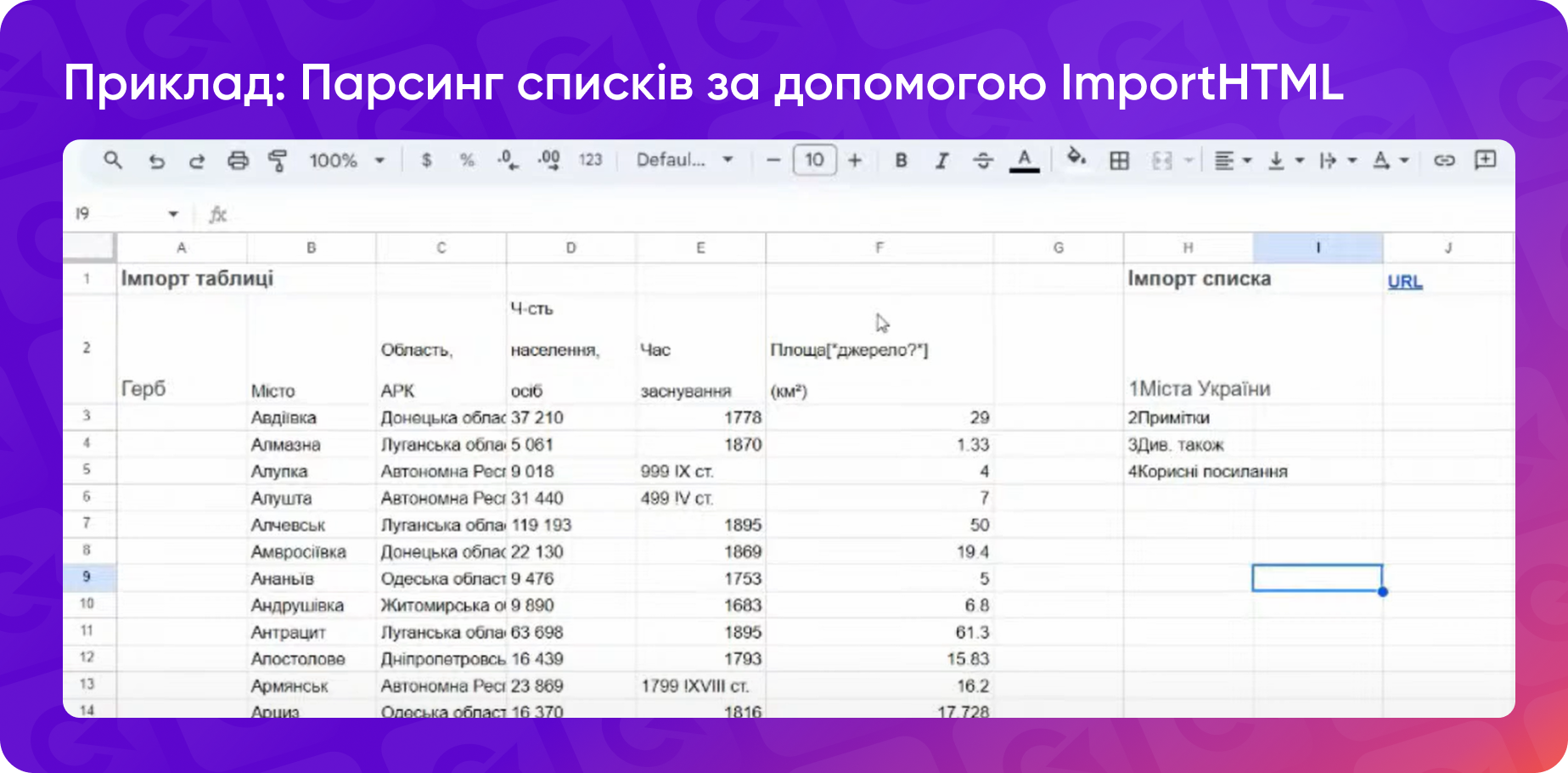
Синтаксис простий: ви вказуєте URL сторінки, тип елемента (таблиця чи список) і порядковий номер елемента на сторінці (його можна переглянути у коді сторінки).
Аналогічно імпортуються нумеровані та марковані списки.
Цей метод зручний для регулярного оновлення таблиць і списків у Google Sheets.
RegEx: приклади та способи використання в SEO
Регулярний вираз (RegEx) — послідовність символів, що формує шаблон пошуку, який використовується для здійснення операцій з текстом, таких як пошук, заміна або розбір інформації.
RegEx широко використовується у різних завданнях, зокрема для парсингу даних у поєднанні з xPath.

Одне з поширених завдань лінкбілдерів — витягування електронних адрес зі сторінок. Для цього використовують регулярний вираз, який включає символ «@» для позначення пошти. Цей шаблон знаходить усі поштові адреси на сторінці.
Де використовуються RegEx:
- фільтрація сторінок за певними шаблонами;
- аналіз контенту;
- формування директив у robots.txt;
- фільтрація логів чи даних з аналітичних інструментів.
Якщо ви працюєте з великим сайтом, скажімо, на 10 тисяч сторінок, різноманіття шаблонів URL може ускладнювати аналітику або контентну роботу. Регулярні вирази дозволяють швидко відфільтрувати сторінки за заданими умовами, що значно прискорює роботу SEO-спеціаліста.

Синтаксис регулярок передбачає набір символів, кожен з яких відповідає за певну послідовність символів чи один символ. Найчастіше використовується знак крапки (.), який позначає будь-який символ — букви, цифри або пунктуацію. Однак існують і інші важливі символи.
Приклад застосування регулярних виразів
Уявімо, що ви працюєте з інтернет-магазином товарів для тварин. Кількість URL на сайті значна, і не всі вони організовані за чітким шаблоном, зручним для фільтрації по підпапках. Ваше завдання — знайти всі URL товарів від брендів Savory і Brit Care:
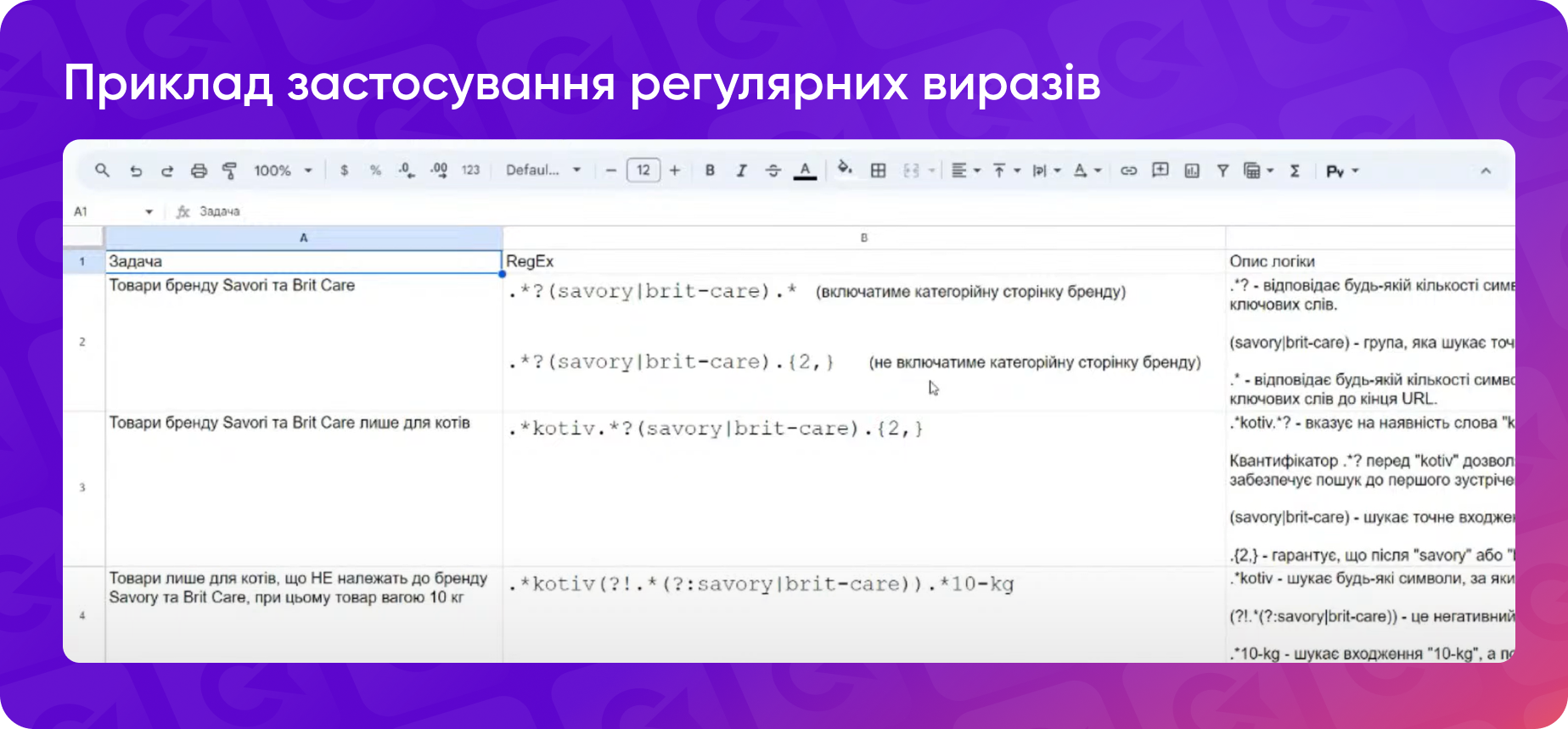
Регулярний вираз може виглядати так:
.*?(savory|brit-care).*
- .*? — відповідає будь-якій кількості символів перед назвою бренду, веде пошук до першого входження одного з ключових слів;
- (savory|brit-care) — група, яка шукає точні входження ключових слів — назв брендів;
- .* — відповідає будь-якій кількості символів після знаходження одного з вищевказаних ключових слів до кінця URL.
RegEx знайде всі URL, що містять назви брендів Savory або Brit Care.
Цей вираз ми можемо вставити у фільтр ScreamingFrog або іншого інструменту для аналізу сайту, щоб вибрати лише необхідні URL. Наприклад, у ScreamingFrog ми використовуємо функцію Matches Regex для фільтрації даних за регулярними виразами.
Однак інколи фільтр може захопити зайві сторінки, наприклад, категорійні сторінки брендів. Щоб уникнути цього, можна уточнити регулярний вираз, додавши правило, що після назви бренду мають бути ще два символи:
.*?(savory|brit-care).{2,}.*
Це гарантує, що регулярний вираз знайде лише URL товарів, а не категорій.
Як ускладнити регулярку?
Можна розширювати вираз для фільтрації за кількома параметрами, наприклад, не тільки за брендом, але й за іншими характеристиками, як от за типом товару. Також можна використовувати зворотні регулярні вирази для виключення певних URL або даних.
Інколи простіше в ScreamingFrog застосувати функції типу contains або not contains, однак регулярні вирази пропонують більше гнучкості, особливо для складних завдань.
Чи складно створювати регулярні вирази?
На перший погляд, може здаватися, що RegEx виглядають досить складно і їх складно формувати. Однак сьогодні створювати та перевіряти регулярки стало простіше завдяки таким інструментам, як ChatGPT. Ви можете навести приклад шаблону URL і попросити згенерувати регулярку для конкретного завдання. Це суттєво полегшує процес.
Аналогічно можна зробити з xPath. Тобто, якщо у ChatGPT кинути ваш шматок структури HTML, конкретного div з class-ом, який ви хочете спарсити, і задати промпт «Сформулюй мені xPath» — це теж чудово спрацює.
Сьогодні є багато інструментів для перевірки коректності регулярних виразів:
- Regex101
- Regexr
- Regex Tester
- RegExp Tester для браузера chrome
- Функція REGEXMATCH в Google Spreadsheet
Вони допоможуть переконатися, що вираз працює правильно.
Використання API: практичні приклади автоматизації SEO-задач
API — це своєрідний посередник, що допомагає програмам «спілкуватися» одна з одною. Як офіціант передає замовлення від клієнта до кухаря, так і API передає дані між двома програмами. Цю абревіатуру часто можна почути в контексті технологій.

Це набір протоколів та правил, які допомагають зв'язати дві програми між собою і інтегрувати дані однієї в іншу.
Одним із найпоширеніших прикладів є використання Screaming Frog. У цьому інструменті можна підключити API до популярних сервісів, таких як Google Analytics, Google Search Console, PageSpeed Insights, Majestic, Ahrefs і багато інших.
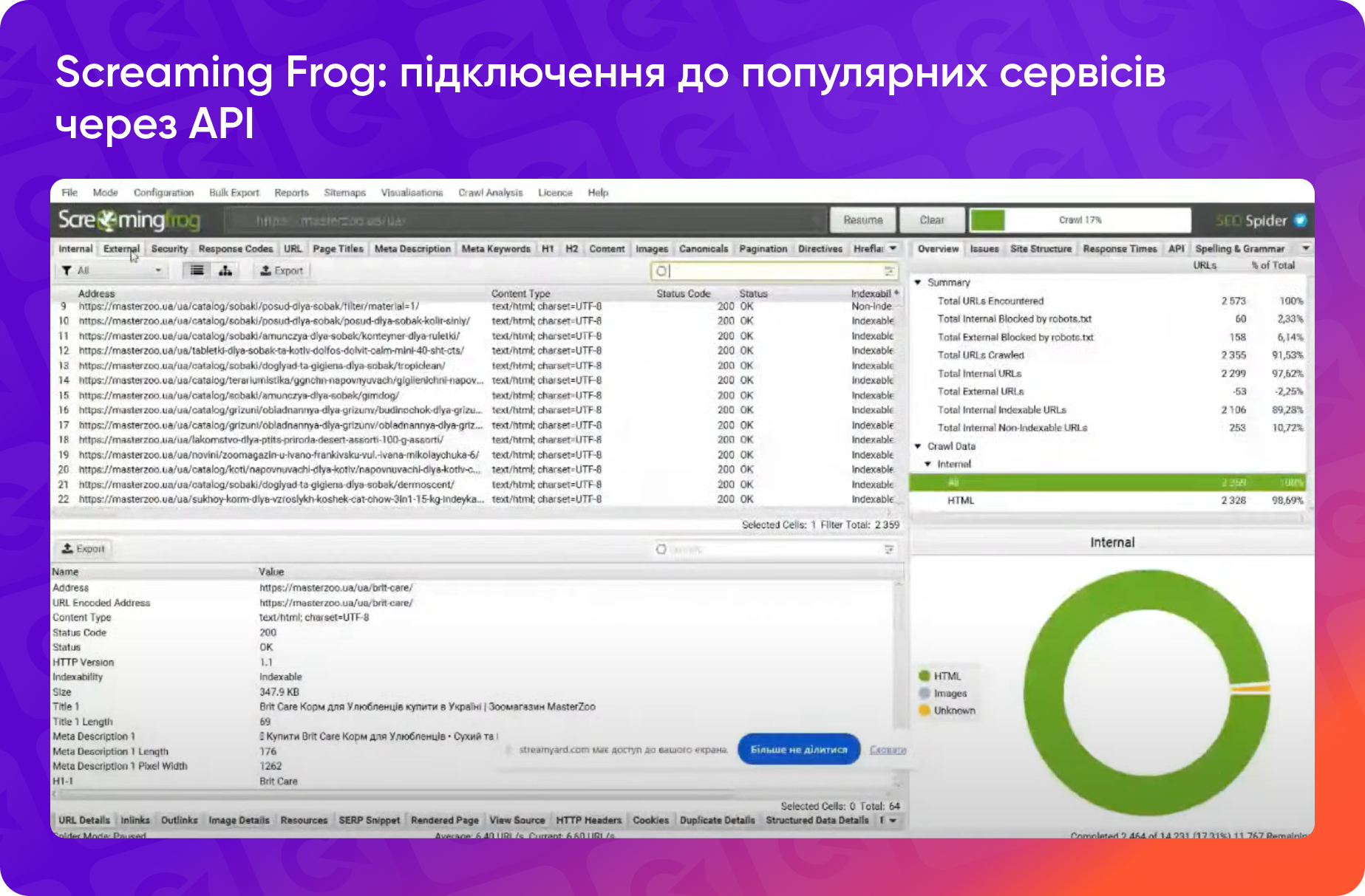
Наприклад, підключення до Google Search Console дозволяє автоматично завантажувати додаткові метрики, такі як кліки, покази, CTR і позиції безпосередньо до результатів парсингу сайту.
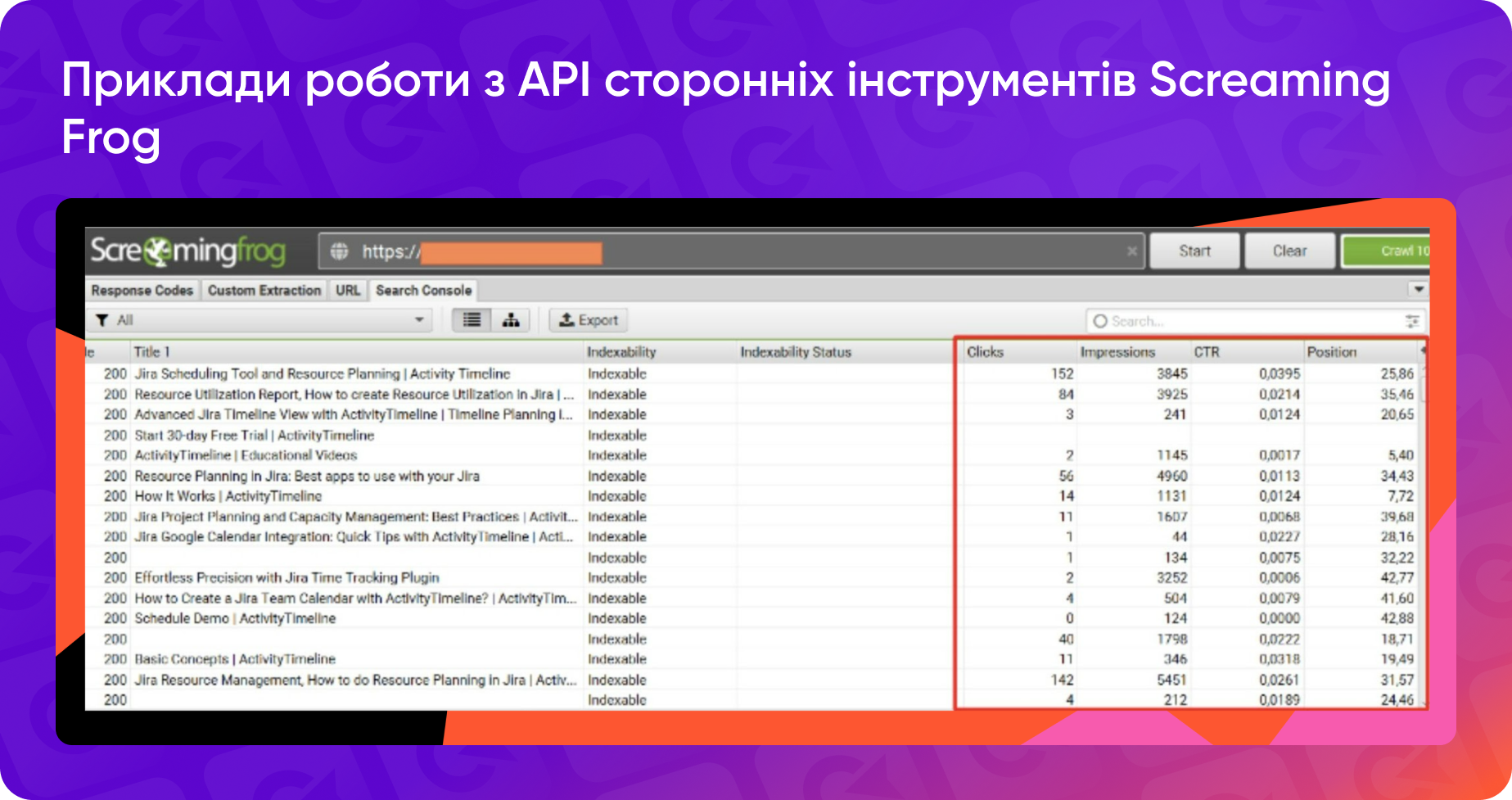
Це значно полегшує аналіз, адже всі дані зібрані в одному файлі.
API не тільки заощаджують час, але й дозволяють оптимізувати роботу з великими масивами даних, роблячи процес SEO-аналізу швидшим та ефективнішим.
Питання-Відповідь
Якщо потрібно парсити ціни та наявність товарів з сайту постачальника кожного дня, чи є інші варіанти, окрім як парсити Screaming Frog-ом?
Все залежить від розміру сайту постачальника. Якщо сайт невеликий, можна використовувати importXML, де ви вшиваєте ваш xPath-запит. Це простий спосіб отримати потрібні дані без складних інструментів.
Якщо ж сайт великий, тоді дійсно ScreamingFrog є більш ефективним рішенням. Для автоматизації процесу, якщо потрібно щоденно парсити дані та зберігати їх, вам доведеться звернутися до розробників. Вони можуть налаштувати мініінструмент, який буде автоматично запускати парсинг і зберігати результати, наприклад, у CSV-файлі.
Якщо ресурсу на розробників немає, доведеться продовжувати використовувати ScreamingFrog для щоденного парсингу вручну. У випадку, коли урлів не дуже багато, можна керувати процесом через Google Таблиці, як я показувала раніше.
Існують також готові сервіси для парсингу, але якщо потрібне кастомне рішення, то або треба робити це самостійно або з допомогою розробників.
Чи можна використовувати API API Google Search Console для перевірки, чи є пул сторінок в індексі Google?
Через API Google Search Console ви можете відправляти сторінки на індексацію та перевіряти, чи вони вже в індексі. Однак, цю інформацію можна отримати і без API, адже стандартний звіт по проіндексованих сторінках вже доступний у самій Search Console.
Більшість SEO-інструментів, як-от JetOctopus, також показують цю інформацію після краулінгу. Тому використання API для цієї задачі не завжди є обов'язковим.
Ще один варіант — ScreamingFrog. Він дозволяє інтегрувати Search Console через API, і тоді ви отримаєте додаткові колонки з інформацією про індексацію сторінок. Тобто дані про індексацію доступні різними способами, а API корисне більше для автоматичної переіндексації сторінок, особливо якщо сайт деіндексовано або після внесення важливих змін.
У яких ситуаціях можна використовувати xPath в роботі?
xPath має широке застосування, і найпопулярніші приклади його використання наступні:
- Аналіз структури сторінок у Google Таблицях. Одне з найрозповсюдженіших завдань — це порівняння структури заголовків на власній сторінці зі структурою конкурентів. За допомогою xPath можна швидко отримати інформацію про заголовки від H1 до H6, виявити різницю та оптимізувати структуру на своєму сайті. Наприклад, так ви можете побачити елемент, який не повинен бути заголовком, або порівняти порядок заголовків зі своїм сайтом.
- Парсинг контенту. xPath активно використовують для парсингу різних елементів із вебсайтів. Наприклад, нам потрібно було отримати демоверсії ігор для сайту, ми спарсили лінки на них з сайтів виробників. Аналогічно можна витягати зображення, текст чи інші дані від конкурентів, постачальників або виробників.
- Отримання даних з табличок. За допомогою xPath можна діставати дані із таблиць, які погано зверстані або мають нестандартну структуру. В цьому допомагає поєднання xPath з функцією ImportHTML у Google Таблицях, про що уже згадувалось раніше.
Чим більший проєкт і більше завдань, тим частіше виникає потреба в автоматизації, і xPath стає корисним інструментом для прискорення рутинних процесів.
На сайті 17 тисяч товарів. Чи можна спарсити таку кількість через Google Таблиці?
Така кількість рядків значно уповільнить роботу Google Таблиць. Тому для обробки такої кількості даних варто розглянути альтернативні методи.
Чи можна витягнути JS контент, який не рендериться, тобто закритий примусово від ботів, за допомогою xPath або ScreamingFrog?
Складно, оскільки якщо JS контент не рендериться і недоступний для інструментів типу ScreamingFrog, то стандартні методи, скоріше за все, не спрацюють.
Однак, варто перевірити, чи дійсно контент не рендериться. Можливо, деякі інструменти, як JetOctopus, здатні впоратись, адже зчитують складні сценарії. Також важливо зрозуміти, який саме тип JS-контенту потрібно витягнути і яким чином він відображається.
Тобто ця задача вирішується, але стандартних рішень тут може бути недостатньо, і знадобляться спеціальні підходи.
Google Search Console має обмеження в кількості рядків експорту. Чи можна витягнути всі ключові фрази, по яких показувався сайт, та URL сторінок, які відповідають цим запитам, через API?
Так, є спосіб обійти обмеження в Google Search Console. Для цього можна скористатися розширенням для Google Sheets під назвою Search Analytics for Sheets. Воно дозволяє витягувати до 25 тисяч рядків.
Щоб використовувати цей інструмент, вам потрібно:
- Встановити розширення Search Analytics for Sheets у Google Chrome.
- Вибрати сайт, до якого у вас є доступ як користувача.
- Визначити інтервал дат для витягування даних.
Розширення надає можливість експортувати дані, включаючи URL-адреси, кліки, impressions та інші метрики. Ви також можете фільтрувати дані за допомогою папок і регулярних виразів прямо в Google Sheets, що робить цей інструмент дуже зручним для аналізу та роботи з великими обсягами даних.
Чи є можливість обійти захист від парсингу, коли зміна юзер-агента не допомагає? Які методи можна використовувати?
Якщо зміна юзер-агента не допомагає, це означає, що сайт використовує складніші методи захисту.
Тому треба дивитись конкретну ситуацію — на якому рівні цей захист стоїть. І тоді вже думати про методи.
Який ви використовуєте сервіс для динамічного проксі для парсингу кожної сторінки з іншим IP?
По суті аж такі масштаби мені зазвичай не дуже потрібні, бо чорним SEO я не займаюсь. Тому тут не підкажу.
Де можна використовувати RegEx, окрім як для аналізу даних в серч консолі, коли тобі потрібно відфільтрувати звіт по певних сторінках, подивитись трафік на каталог або на товари?
Для будь-якої звітності. Наприклад, в гугл таблицях є навіть вбудована функція RegEx Match, де тягнеш дані лише для урлів, які відповідають RegEx.
Найпопулярніша задача в лінкбілдерів по RegEx — це парсити імейли. Часто також використовується для аналітики.
Дякуємо Валерії за корисну та практичну інформацію🦾