В цій статті я ділюся власним досвідом використання XPath для вирішення 99% типових задач в SEO. Цього недостатньо, щоб робити промисловий парсинг сайтів, але така задача перед більшістю SEO-спеціалістів і не стоїть. Якщо потрібно вирішити більш складні завдання, в кінці є список посилань на документацію та туторіал.
Цей пост — це шпаргалка, яка допоможе новачкам отримати готові рішення, зрозуміти синтаксис, а при потребі до неї можна постійно повертатись.
Де використовувати XPath
XPath — це мова запитів до елементів XML-документа для навігації по DOM, а це означає, що його можна використовувати для вебсторінок, щоб скрапити потрібні дані. Простими словами, це дозволяє зачепитися за потрібний тег і дістати його атрибути або вкладені елементи.
Найчастіші випадки, з якими я стикався:
- Масова перевірка отриманих посилань.
- Знайти сторінки, які мають певне значення. Наприклад, відсутність товару в інтернет-магазині, назва категорії, до якої належить сторінка, товари без цін, товари з певною характеристикою для подальшого тегування, продукти в певному ціновому діапазоні, кількість товарів в категорії або постів в рубриці.
- Парсити потрібні дані з SERP: заголовки та опис в сніппеті, підсвітки, дані по розширеному сніппету.
У Chrome протестувати запити можна через DevTools –> Elements –> CTRL + F…
… або за допомогою розширень SelectorsHub, XPath Helper та інших:
 Використання розширення XPath Helper
Використання розширення XPath Helper
На практиці ж треба знаходити типові елементи одночасно на багатьох сторінках — ціну, залишок товару на складі, повідомлення про відсутність товару, зовнішні посилання тощо. Для цього можна використовувати:
- Вебпавуки та парсери. Я буду наводити приклади за допомогою Screaming Frog SEO Spider, адже впевнений, що кожен SEO-спеціаліст
придбавмає ліцензійну версію (If you know what I mean). - Всю міць Google Sheets за допомогою функції IMPORTXML.
- Будь-які мови програмування, які можуть працювати з вебом.
Перші кроки: кейси для CTRL+C → CTRL+V
Показати Title
«Hello, World!» у світі xPath — це знайти title, бо він лише один на сторінці.
//title
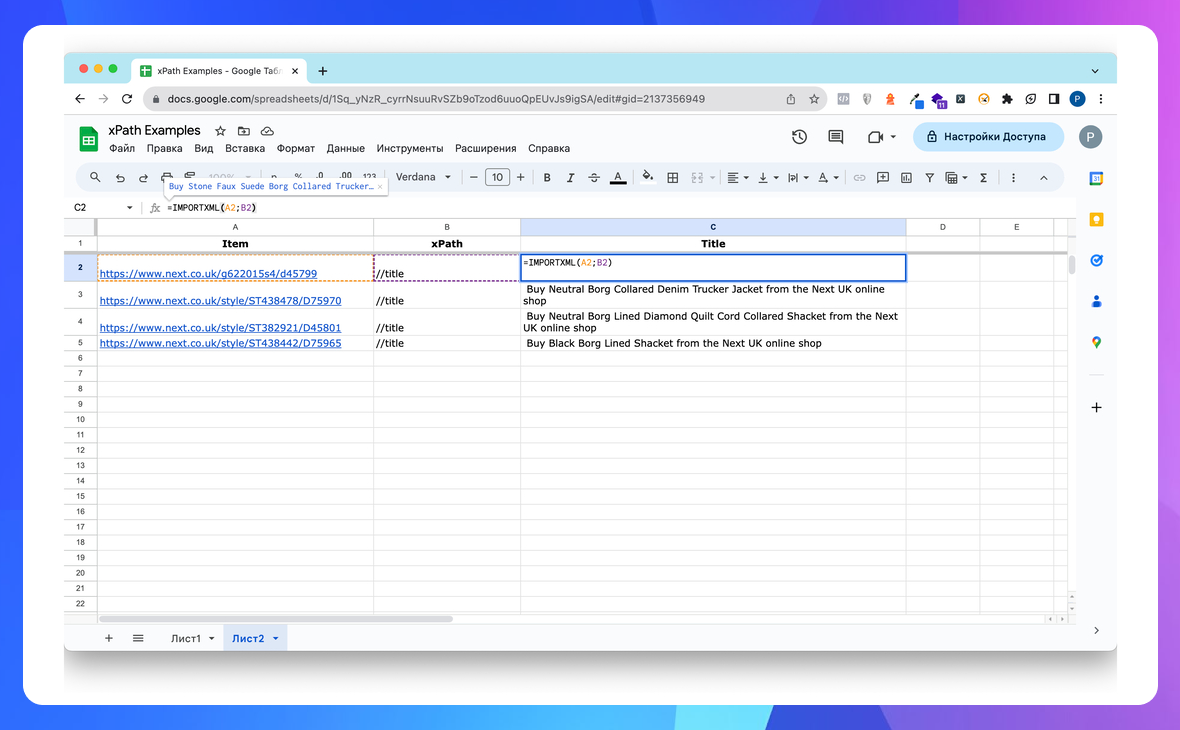 =IMPORTXML("https://site.com"; "//title") в Google Sheets
=IMPORTXML("https://site.com"; "//title") в Google Sheets
Майте на увазі, що використовувати Google Sheets як парсер — дуже крихка ідея, бо в багатьох випадках сайти блокують цю можливість.
Показати Description
//meta[@name='description']/@content
 =IMPORTXML("https://site.com"; "//meta[@name='description']/@content") в Google Sheets
=IMPORTXML("https://site.com"; "//meta[@name='description']/@content") в Google Sheets
Показати всі заголовки h1-h6 послідовно
//*[self::h1 or self::h2 or self::h3 or self::h4 or self::h5 or self::h6]
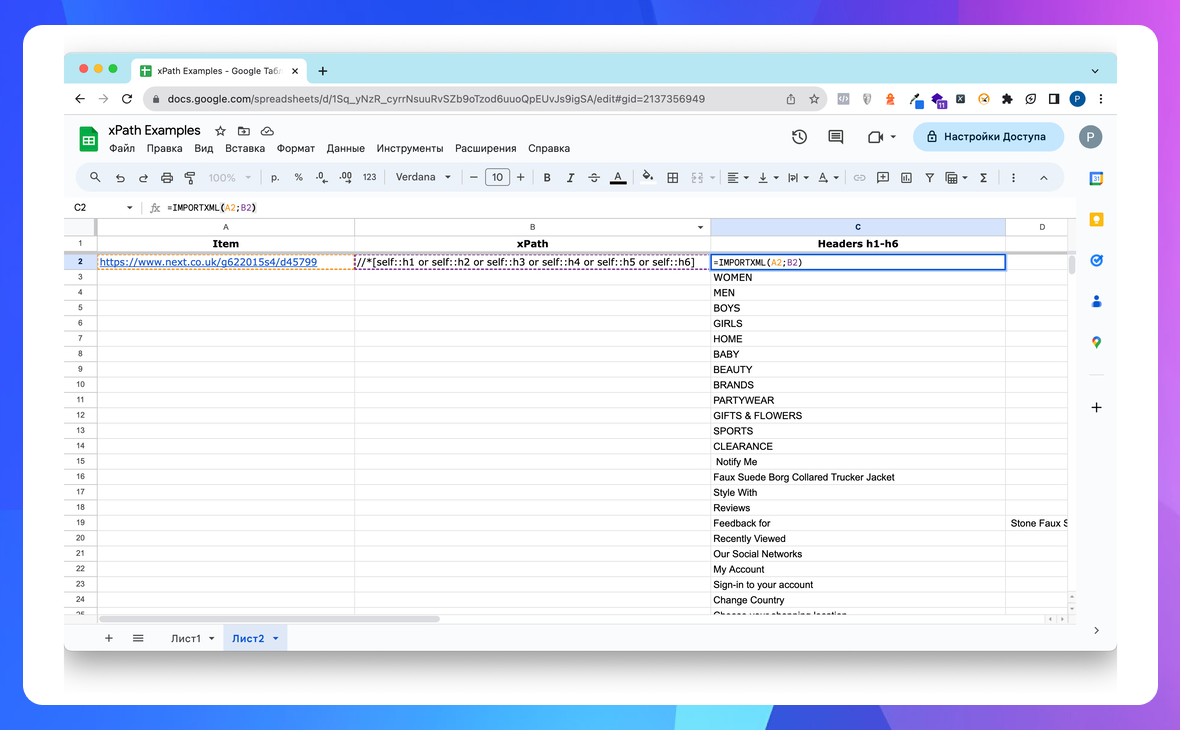 =IMPORTXML("https://site.com";"//*[self::h1 or self::h2 or self::h3 or self::h4 or self::h5 or self::h6]") в Google Sheets
=IMPORTXML("https://site.com";"//*[self::h1 or self::h2 or self::h3 or self::h4 or self::h5 or self::h6]") в Google Sheets
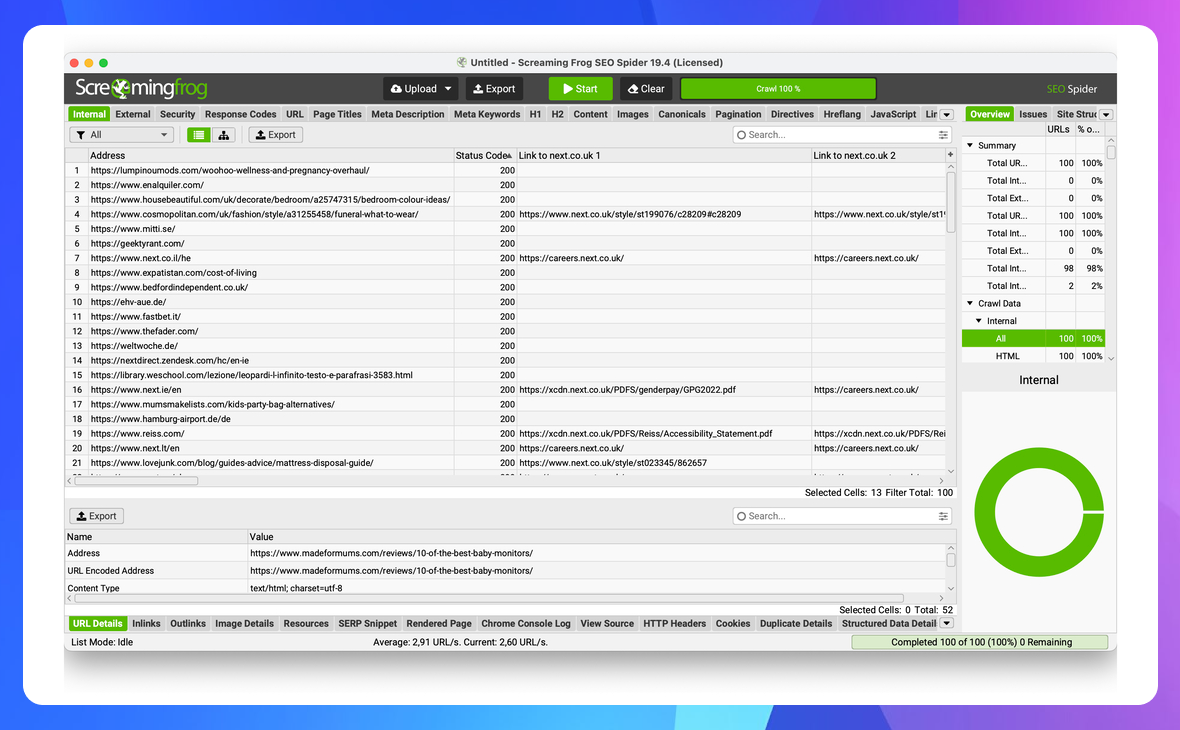
Показати зовнішні посилання на обраний сайт
Корисно при потребі пакетно перевірити, чи цілі посилання на ваш сайт, що були проставлені раніше.
//a[contains(@href,'site.com')]/@href
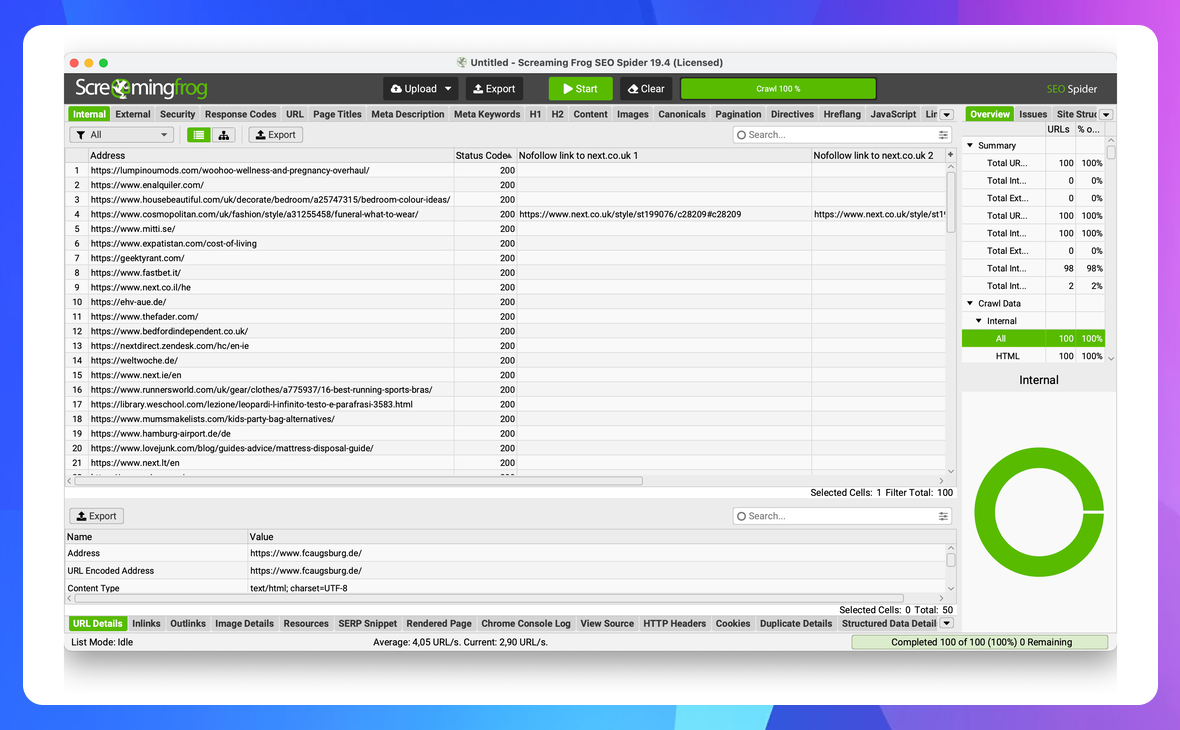
Показати зовнішні посилання на обраний сайт з атрибутом nofollow
//a[contains(@href,'site.com')][contains(@rel,'nofollow')]/@href
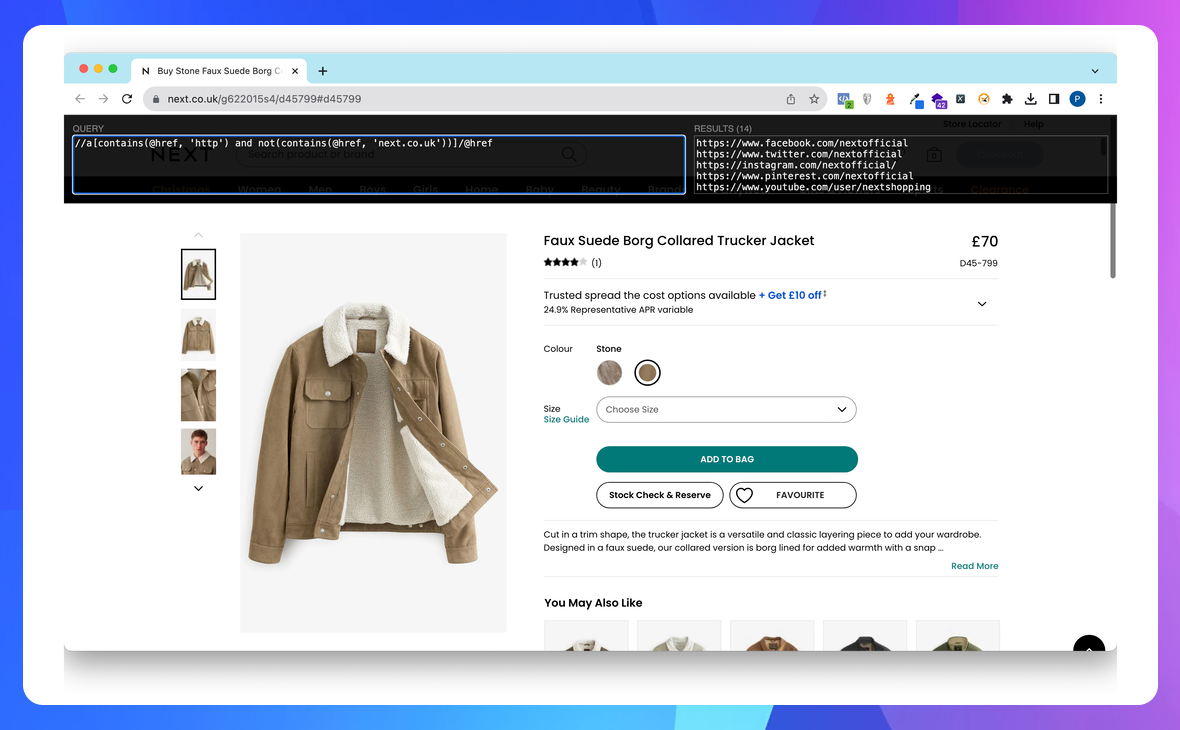
Показати всі зовнішні посилання на сторінці
//a[contains(@href, 'http') and not(contains(@href, 'mydomain.com'))]/@href
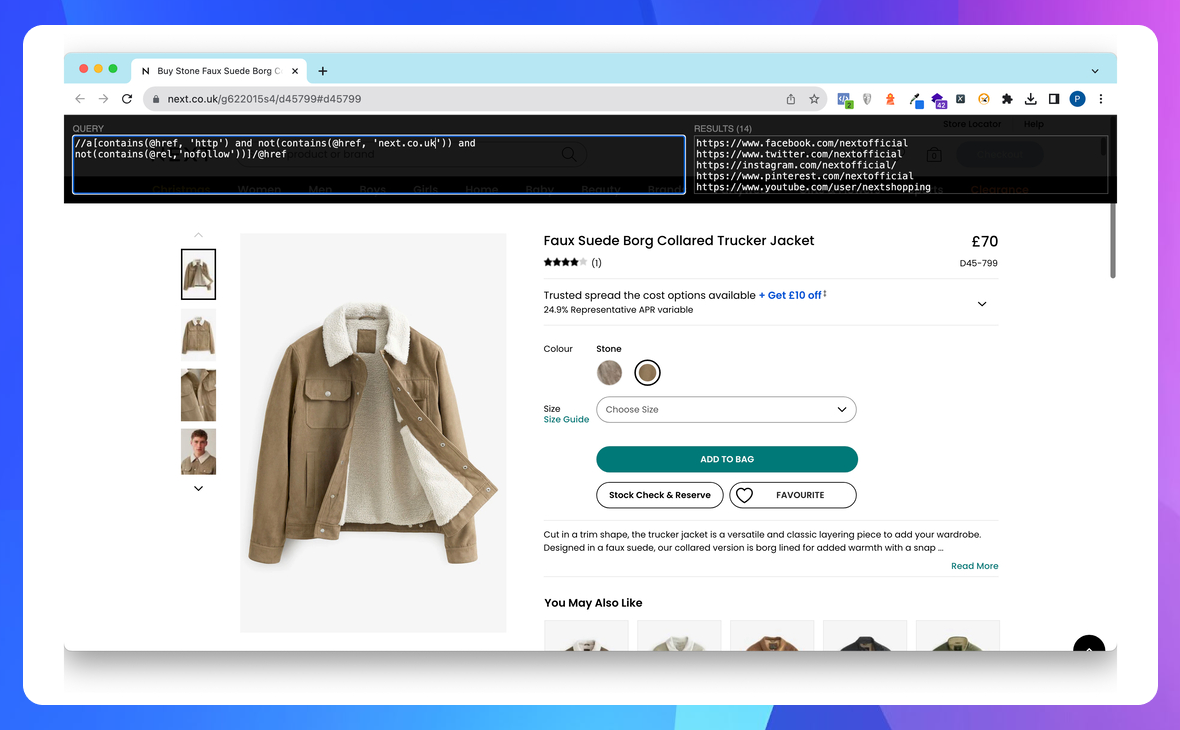
Показати всі зовнішні dofollow посилання
//a[contains(@href, 'http') and not(contains(@href, 'mydomain.com')) and not(contains(@rel,'nofollow'))]/@href
Показати канонічне посилання
//link[@rel='canonical']/@href
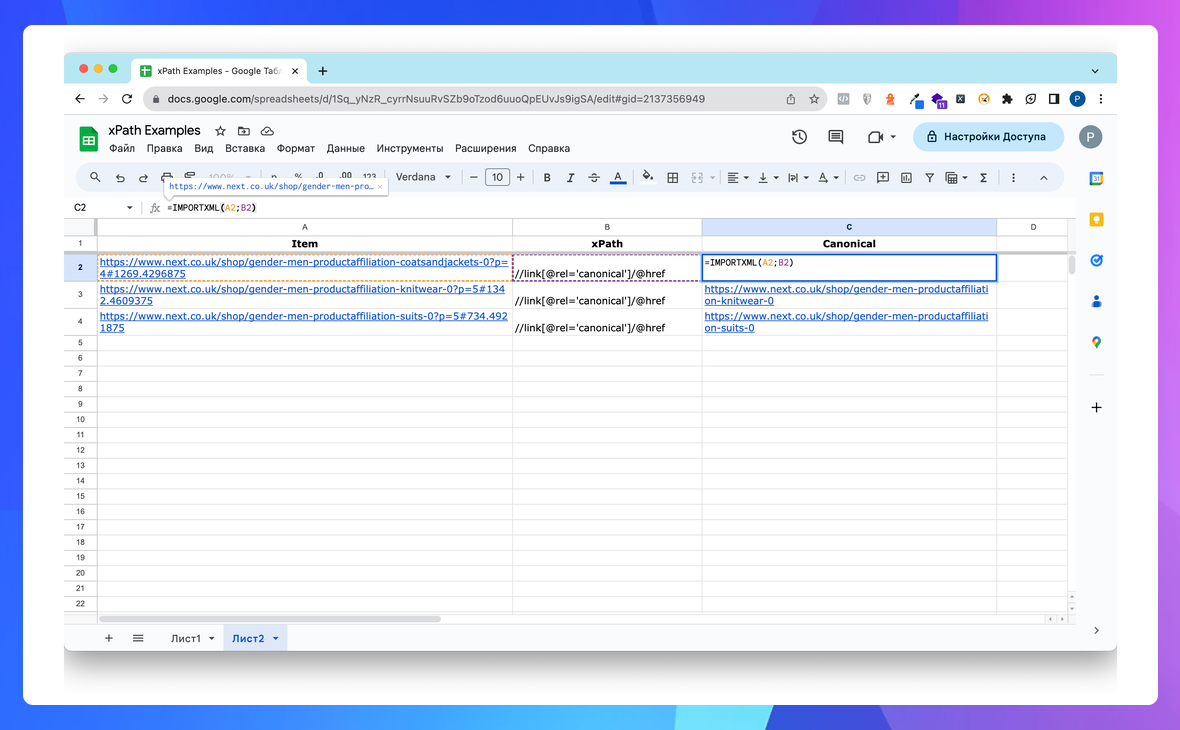 =IMPORTXML("https://site.com/";"//link[@rel='canonical']/@href") в Google Sheets
=IMPORTXML("https://site.com/";"//link[@rel='canonical']/@href") в Google Sheets
Показати значення тега robots (noindex, nofollow та таке інше)
//meta[@name='robots']/@content
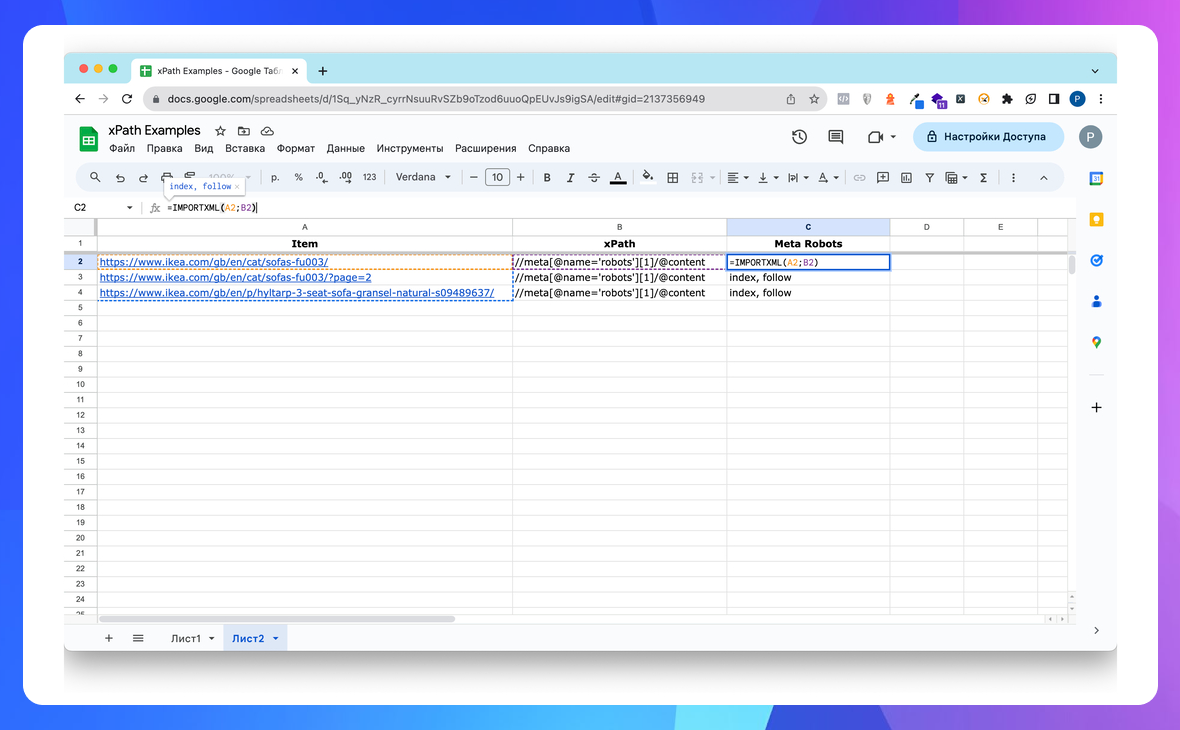 =IMPORTXML("https://site.com/";"//meta[@name='robots']/@content") в Google Sheets
=IMPORTXML("https://site.com/";"//meta[@name='robots']/@content") в Google Sheets
Показати, які є мовні версії сторінки
//link[@rel='alternate']/@hreflang
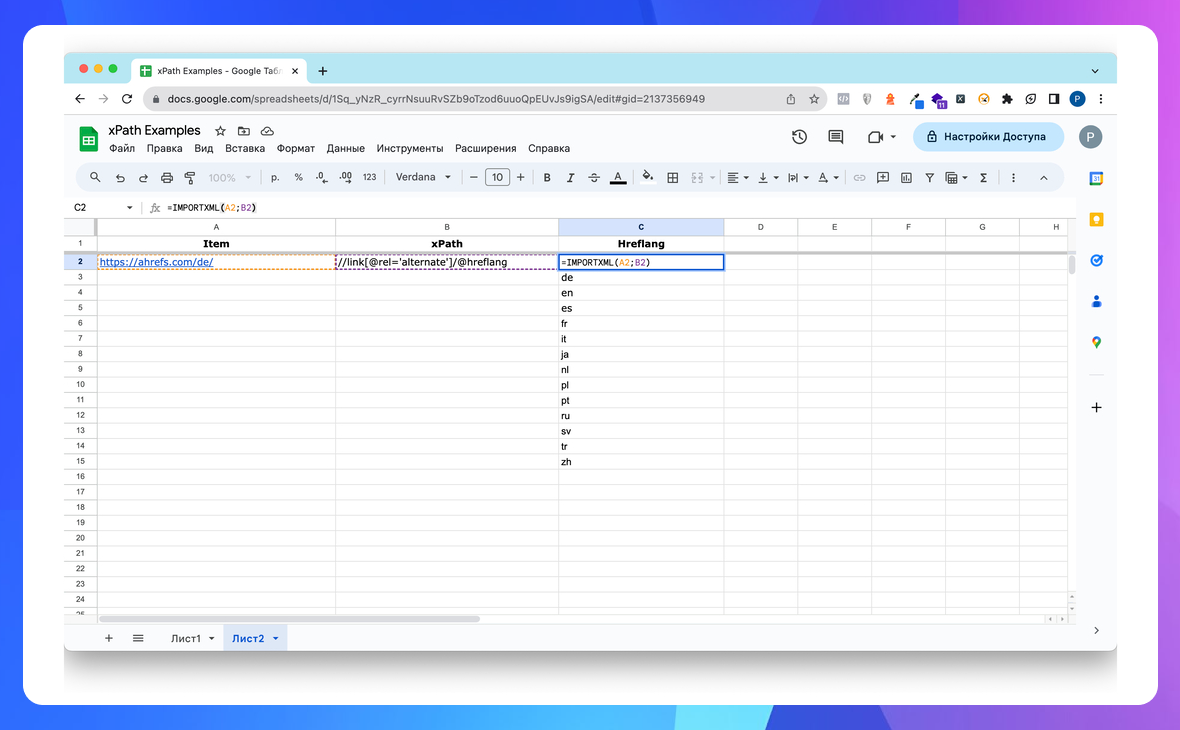 =IMPORTXML("https://site.com/";"//link[@rel='alternate']/@hreflang") в Google Sheets
=IMPORTXML("https://site.com/";"//link[@rel='alternate']/@hreflang") в Google Sheets
Показати мікророзмітку в форматі JSON-LD
//script[@type='application/ld+json']
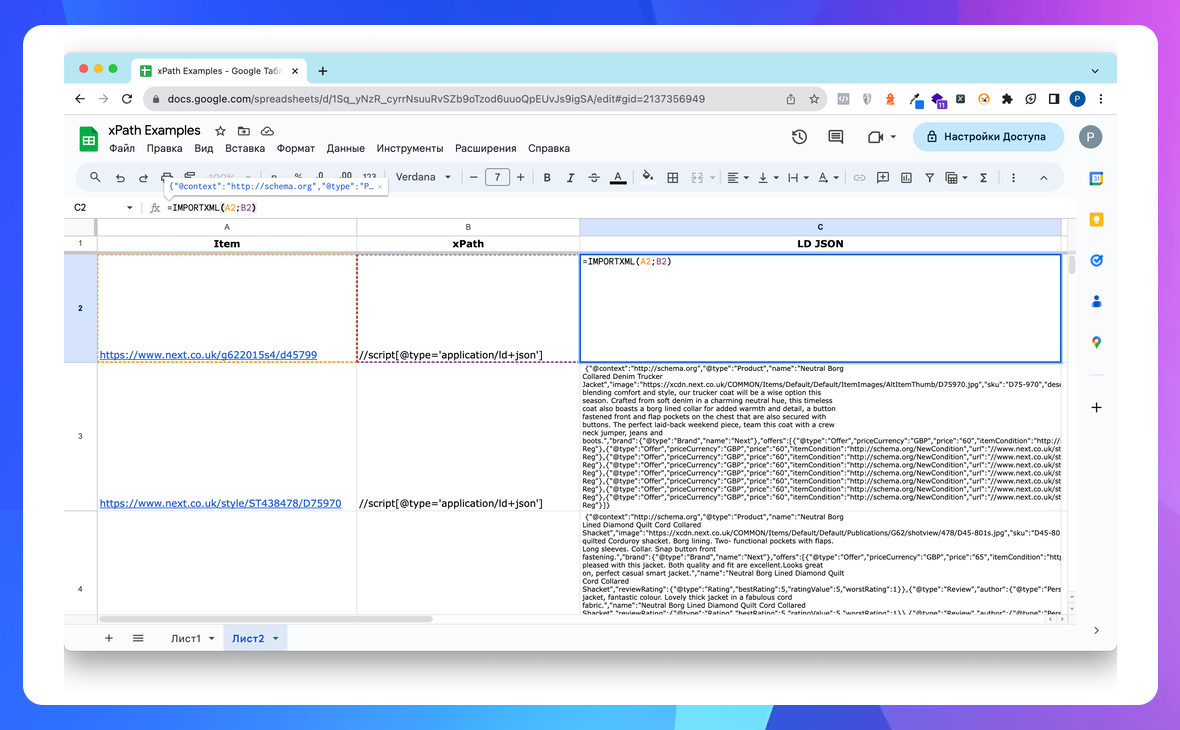 =IMPORTXML("https://site.com/";"//script[@type='application/ld+json']") в Google Sheets
=IMPORTXML("https://site.com/";"//script[@type='application/ld+json']") в Google Sheets
Як отримати xPath до потрібного елементу
Абсолютний xPath
Наприклад, ви хочете спарсити дані ціни, артикула товару та рейтингу.
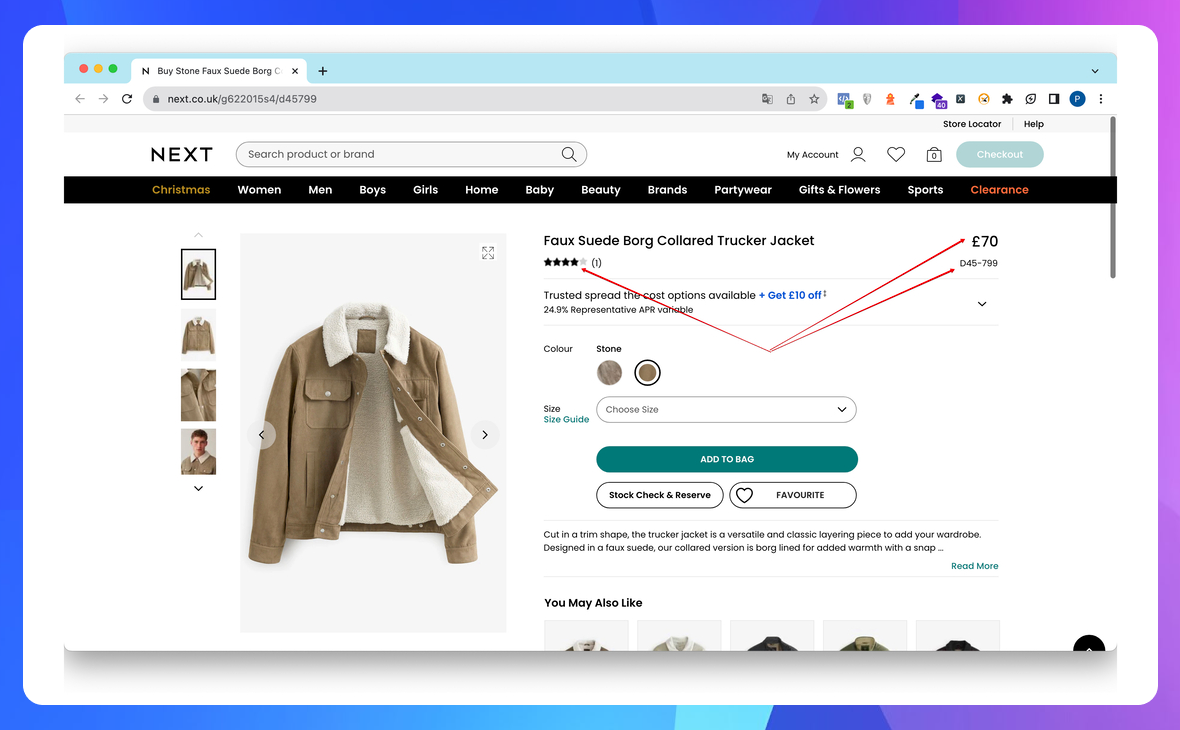
В Chrome абсолютний xPath можна отримати наступним чином:
Клік правою кнопкою на потрібному елементі → Клік правою кнопкою на обраному вузлі в DOM → Copy → Copy xPath (чи Copy Full xPath)
Це виглядає наче просто, але є критичні нюанси: отриманий вираз має дуже складну структуру.
У випадку Full xPath взагалі будується весь шлях тегів. Приклад для ціни:
/html/body/section[1]/section[1]/div[1]/div[2]/div[2]/div/section[2]/article/
section/div[1]/div[2]/span
На практиці DOM може мати складну ієрархію, де виводяться різні елементи для різних юзер-агентів, пристроїв, розширень екрана, тому скопійований xPath може віддати результат у вашому браузері, а через Google Sheets, Screaming Frog SEO Spider або інший парсер — ні.
Щоб отримати коректні дані, все одно потрібно провести деякі маніпуляції, тому бажано зрозуміти основи синтаксису.
Відносний xPath: базові принципи
Правильно побудований відносний xPath дозволяє зробити найбільш точний запит. Для цього важливо розуміти основні принципи.
В першу чергу треба обрати кінцевий тег, де знаходиться інформація, яку потрібно спарсити — <div>, <span>, <a> або будь-який інший. Далі треба, щоб цей тег мав унікальний локатор (селектор), за яким цей елемент можна знайти. Якщо унікального локатора в тезі немає, то треба піднятися вище до того тегу, де він є.
Приклад:

У цьому випадку, щоб отримати “Example Text 2”, треба обрати тег <div class=”class_1”>, бо в нього є локатор class=”class_1”, а у вкладеного тега — ні. Щоб звернутися до тега по селектору, треба використати функцію contains.
Починаємо будувати вираз:
//div[contains(@class, 'class_1')]
Може бути і такий альтернативний вираз, де ми чітко обираємо клас:
//div[@class='class_1']
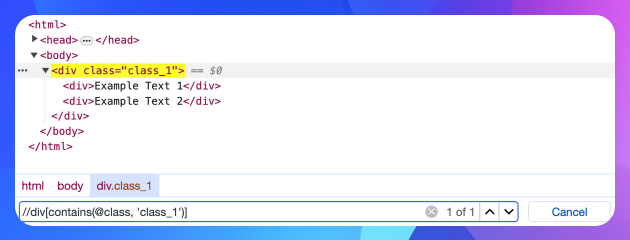
Як ідентифікатор шляхів ми обрали вузол на будь-якому рівні за допомогою двох слешів “//”. В першому випадку ми використали функцію “contains”, у другому — оператор “=”.
Від обраного тега з локатором треба йти далі до потрібного елемента.
//div[contains(@class, 'class_1')]/div
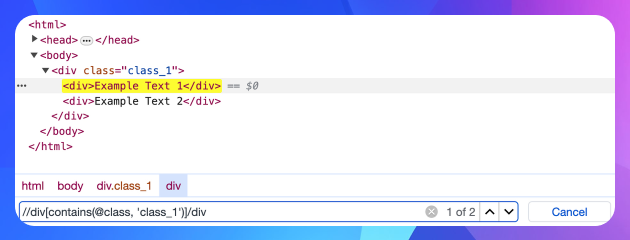
Як видно на скриншоті, цей вираз дозволив знайти два тега <div>: обидва знаходяться всередині <div class="class_1">.
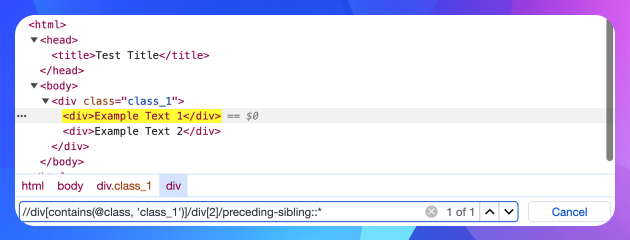
Щоб вибрати другий елемент, треба вказати його предікат (індекс):
//div[contains(@class, 'class_1')]/div[2]
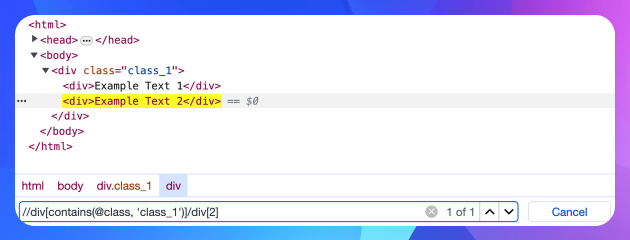
XPath також дозволяє вказати вісь, щоб визначити взаємовідносини між вузлами. Так, наприклад, знаючи шлях до другого елемента, можна знайти елементи, що знаходяться до нього:
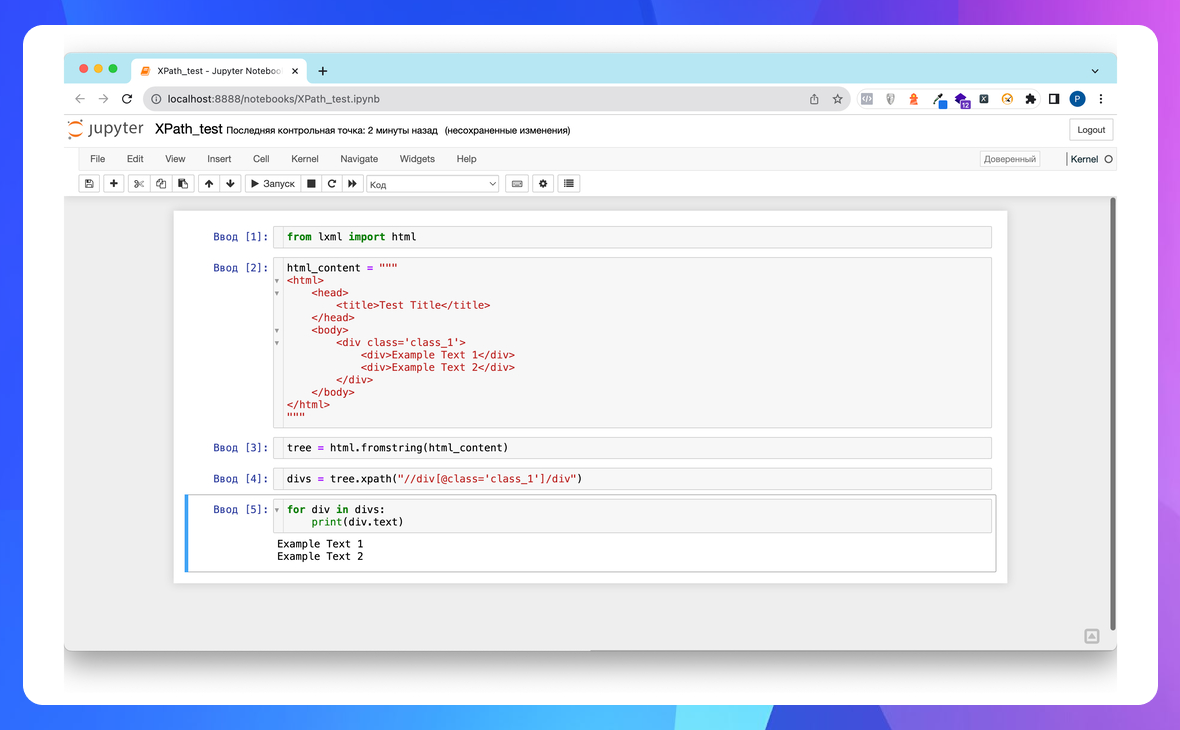
В реальних задачах часто доводиться парсити елементи почергово та зберігати в структури даних, файли або базі даних. Для цього треба використати мову програмування та обробити ці елементи циклом.
Приклад на Python:
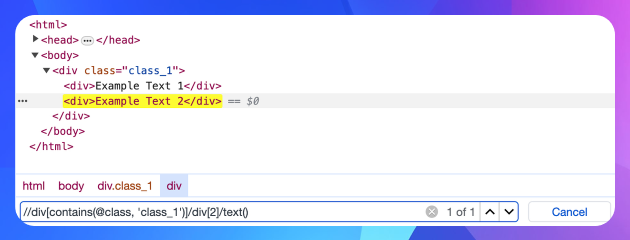
Повернемось до другого елемента. Результатом виразу буде не текст, який знаходиться всередині, а тег в цілому:
<div>Example Text 2</div>
Щоб отримати строкове значення, треба використати функцію text() з атрибутом '@class' та строковим літералом 'class_1':
//div[contains(@class, 'class_1')]/div[1]/text()
Отже, на маленькому прикладі ми розібрали основні елементи XPath:
- Вирази
- Функції
- Вісі
- Вузли
- Предікати
- Літерали
- Локатори
- Ідентифікатори шляхів
- Оператори
Реальний кейс
Повернемося до розв'язання задачі з парсингу ціни, артикулу та рейтингу.
Для парсингу ціни ми зачепимось за тег <div> з локатором class='nowPrice branded-markdown' та деталізуємо запит вкладеним тегом <span>.
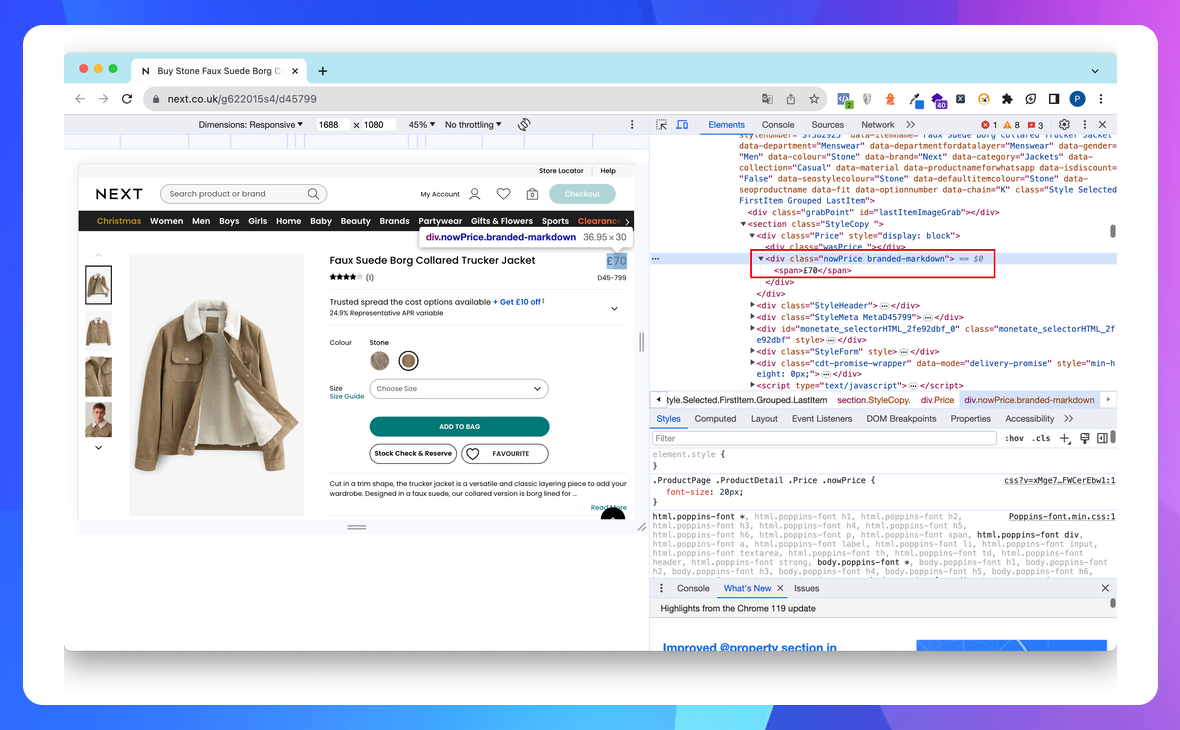
//div[@class='nowPrice branded-markdown']/span
Ми отримали один результат, отже, не має потреби робити запит з більш точною деталізацією.
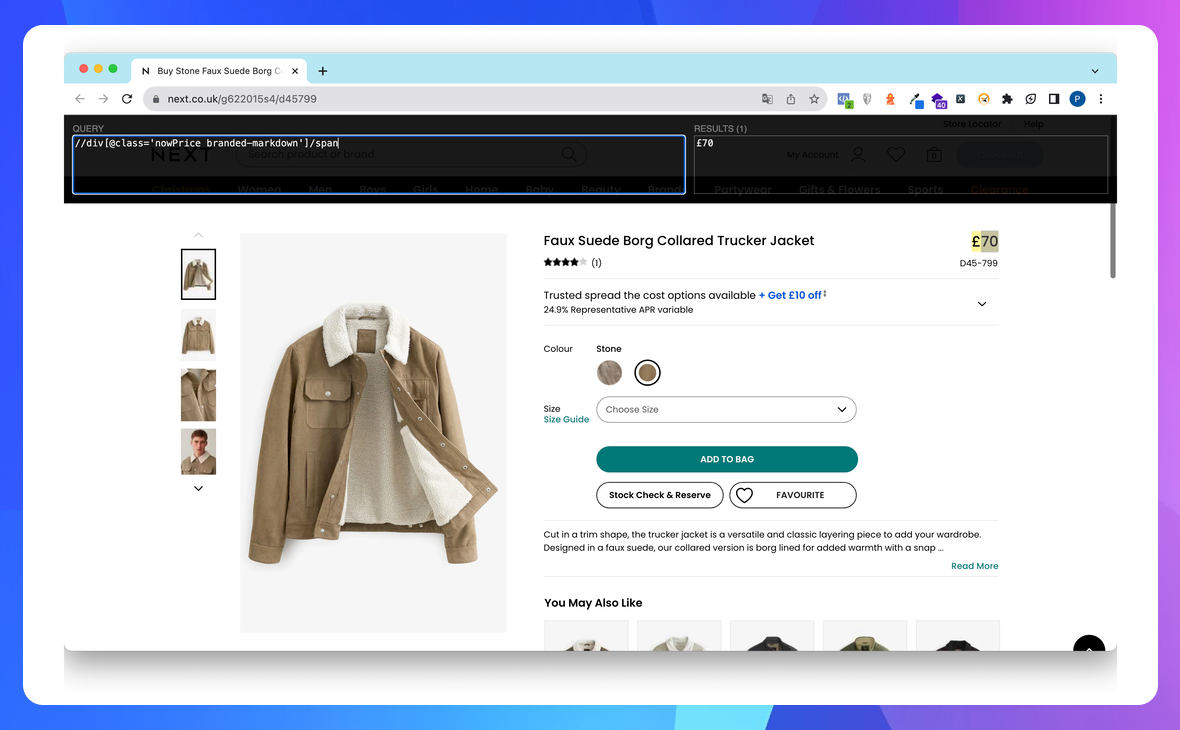
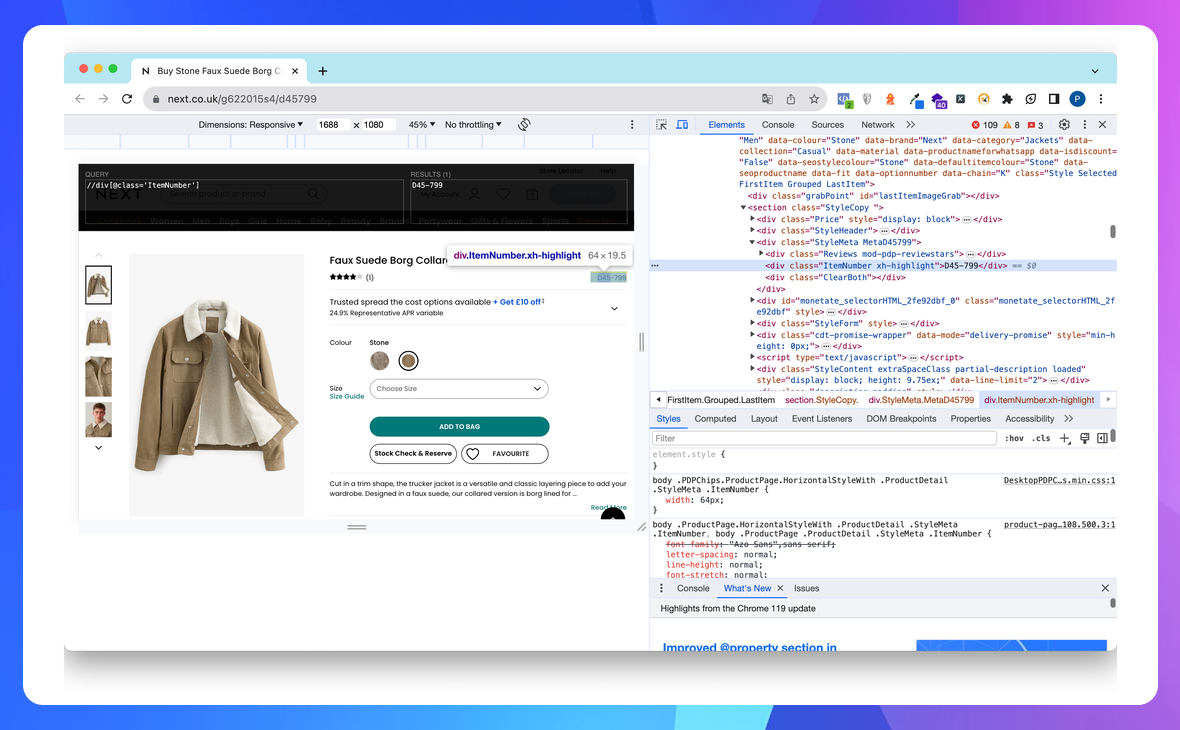
Аналогічним чином підбираємо XPath для артикула:
//div[@class='ItemNumber']
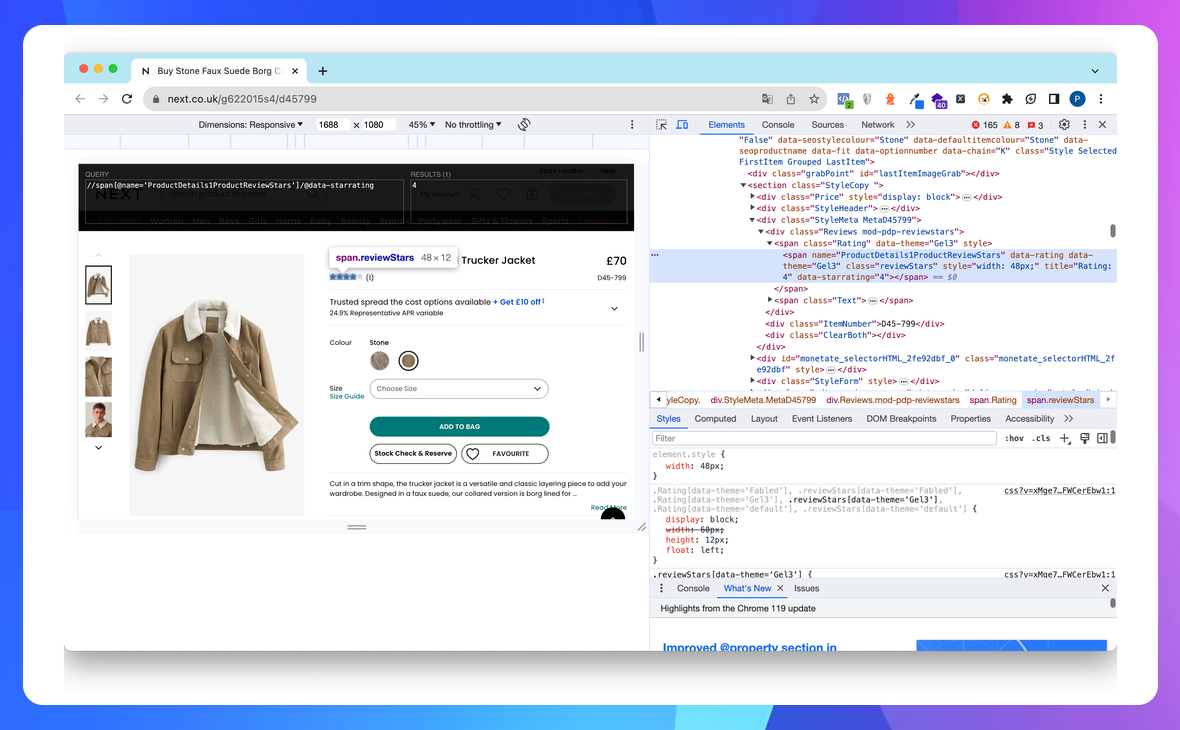
Для парсингу рейтингу обираємо тег <span> з локатором name=‘ProductDetails1ProductReviewStars’ та звертаємось до атрибута ‘data-starrating’:
//span[@name='ProductDetails1ProductReviewStars']/@data-starrating
Спробуємо спарсити дані за допомогою функції IMPORTXML в Google Sheets. Як видно на скриншоті, не вдалося отримати дані Rating.
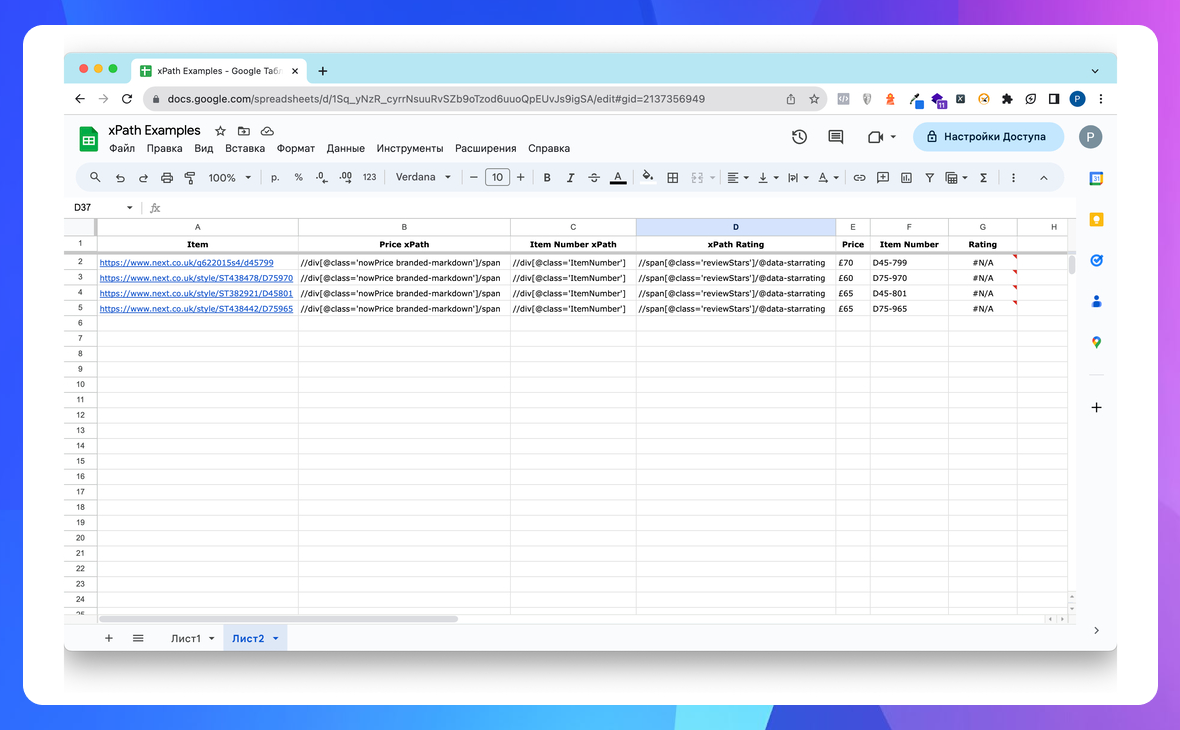
Це пов’язано з тим, що дані частково завантажуються за допомогою JavaScript, який функція IMPORTXML не опрацьовує. Якщо подивитись source code документа, то в обраному вузлі необхідний атрибут 'data-starrating' відсутній.
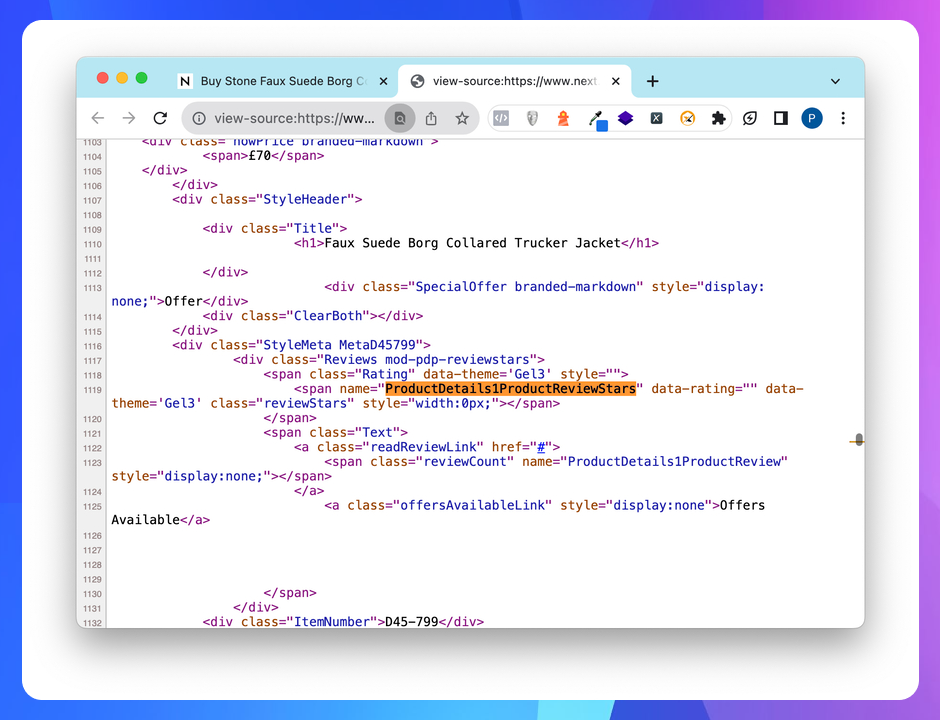
Отже, отримати ці дані ми можемо лише з опрацюванням JavaScript. Для цього використаємо Screaming Frog SEO Spider в режимі рендерингу JavaScript.
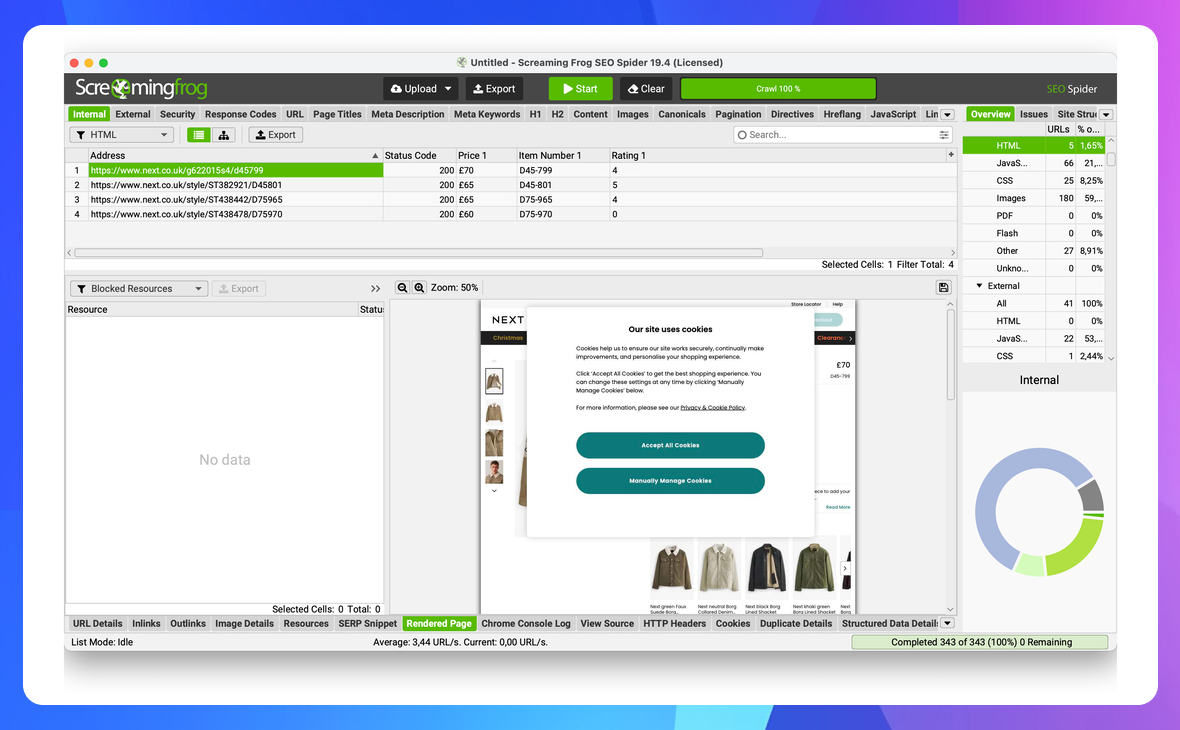
Всі дані отримані, задача виконана.
Матеріали для вивчення можливостей XPath
Вище я показав базові принципи для розуміння роботи з XPath, але при розв'язанні реальних задач завжди трапляються складнощі, тому рекомендую ознайомитись більш детально з синтаксисом і можливостями за цими посиланнями: