На Першій SEO-конференції Collaborator Сергій Безбородов, CTO в JetOctopus, говорив про технічні аспекти SEO для великих сайтів e-commerce. Це популярна ніша, яка зараз у ціні і широко заповнюється. При цьому не все у ній можна зробити посиланнями.
Сергій — програміст, при цьому був постійно пов'язаний із SEO, має досвід роботи над агрегаторами. З 2016 працює над розвитком краулера JetOctopus.
Далі — текст від імені Сергія👇
Ми перекраулили більше 30 тисяч сайтів, проаналізували 50-60 мільярдів логів. Все, про що я говоритиму, ми бачили: це робили наші клієнти.
Сьогодні в доповіді розберемо 5 основних частин, які стануть у нагоді в технічці будь-якого великого сайту. Мені б дуже хотілося розповісти про якісь фішки, які можна зробити однією кнопкою, але ми говоритимемо про банальні речі, які, найімовірніше, ви знаєте.
Ідея доповіді в тому, щоб, не переглядаючи відео, ви просто зберегли собі цю презентацію і коли треба змогли по ній пробігтися.
Кит 1. Аналіз ситуації та збір даних
Часто коли ми приходимо на великий проект, де мільйони сторінок, тонни трафіку, виникає нерозуміння. Ви дивитеся Google Search Console та Google Analytics, але як зрозуміти реальну картину? Тому що будь-який великий сайт – це сотні, а іноді й мільйони сторінок, і десь буде все гаразд, а десь погано.
Для моніторингу поточної ситуації рекомендую зробити одну табличку, куди потрібно зібрати дані з кількох джерел. На великих сайтах, за рідкісним винятком, у вас буде чітка структура по урлах. Ви берете розбивку по директоріям 1-го рівня і вважаєте, яка кількість сторінок, відсоток сторінок, відкритих до індексації тощо. У результаті виходить таблиця, дивлячись на яку ви з першого погляду можете зрозуміти стан сайту. Тобто які у вас є папки, категорії, бренди, продуктові сторінки або розділи.
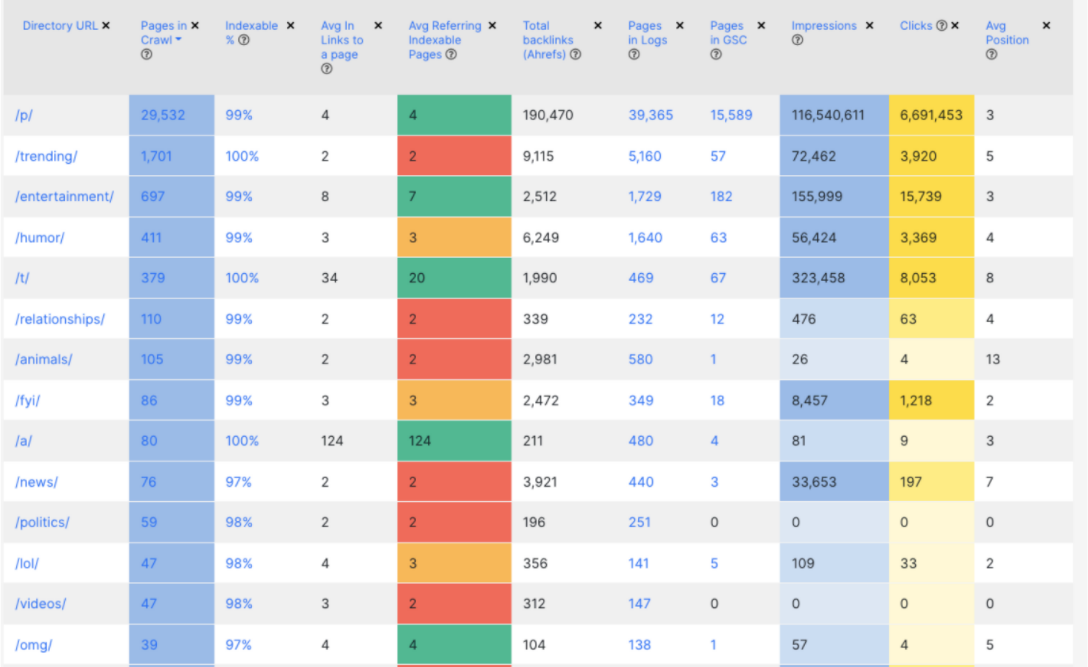
Ми таку ж таблицю робимо у JetOctopus. Це дуже зручно. У вас може бути мільйон сторінок, з яких до індексації буде відкрито 100 тисяч, а impression вони будуть приносити 10 тисяч. На мій досвід, ця таблиця — ваш перший крок до технічного SEO. З нею ви з першого погляду зможете зрозуміти, що у вас працює і реально приносить трафік, конверсії, продаж та гроші.
Кит 2. Технічне SEO
Наступний кит — це найбанальніша і проста техніка. Я її розбив на 2 частини:
- технічка с Javascript,
- технічка без нього.
Якщо у вас на сайті немає Javascript, я щиро вітаю вас. Вам дуже пощастило, і у вас поки що немає великого пласта проблем😉
Найперше, що ми починаємо дивитися в технічці — як ми управляємо індексацією:
- як саме закриваються сторінки meta, non canonical, robot.txt
- чи відповідає це вашим очікуванням
Приклад: ви прокраулили за допомогою Screaming Frog 100 тисяч сторінок. Більше у вас не вийшло та закриваєте сторінки noindex. Але коли ви починаєте заходити далі до якихось далеких категорій виявляється, що canonical поліз. Виходить, що це не відповідає вашим очікуванням. Тому, як ви керуєте індексацією, це стартовий етап.
Наступне — відстежуємо дублі title, meta-тегів. Це є в будь-якому списку аудитів, але це не скасовує їхньої важливості. Meta-опис є вторинним питанням, але дублі title — це критична проблема для відкритих до індексації сторінок. Їх потрібно фіксувати та розбирати. Є деякі SEO-фахівці, які думають, що дублюється та й гаразд, сторінка ранжується. Це одна з найпростіших речей, яку ви можете виправити, і яка принесе вам результат.
Тут важливо:
- який % title дублюється,
- чи приносять ці сторінки трафік;
- чи змінив Google в них тайтли;
- не можете зробити нормально опис — видаліть тег як експеримент і простежте, що вийде. Я не раз спілкувався з клієнтами, які це робили. У багатьох випадках це не погіршувало, а навпаки, покращувало CTR і навіть ранжування.
Третій момент — сторінки пагінації, які є на будь-якому каталожнику. Здається, що це просто пагінація: користувач туди ходить, боту туди ходити не треба. Але історично так склалося, що усі закривають сторінки пагінації від індексації. І тут у мене виникає таке питання: коли у вас з перелінковкою не все добре і товари знаходяться на другій, третій сторінці і так до десятої, то як боту знайти посилання на ці товари?
Завжди існує віра, що робот всесильний, і він все бачить. Але він не зможе знайти посилання на товари з другої, третьої, десятої сторінки навіть якщо туди ходить користувач. Коли у вас таких товарів будуть десятки і сотні тисяч, то вам апріорі потрібно зробити нормальні посилання.
Існують різні погляди на те, що робити зі сторінками пагінації. Я завжди раджу провести експеримент. Не треба робити на всьому сайті, зробіть на якихось вибіркових категоріях. Наприклад:
- є non-canonical, приберіть його,
- закриваєте від індексації – приберіть цей тег, спробуйте відкрити для індексації.
Одним із найбільш явних факторів того, що можливо це варто зробити: у вас сторінки закриті non-canonical, ви йдете в Google Search Console і бачите трафік на цих сторінках. Тобто Googlebot проігнорував ваш non-canonical, він вважає ці сторінки корисними. Якщо вони реально приносять трафік і відповідають на запит користувача з пошуку, це нормально. Просто подивіться на сторінки пагінації з іншого боку.
Технічка. Custom Extraction
Невеликий відступ, бо це знадобиться у наступному слайді. Ми стандартно краулимо сторінку, сам краулер витягує тайтл, мета, посилання і т.д.
Custom Extraction – це неможливо крутий інструмент. Я вважаю, що кожен SEO-вець повинен мати його у своєму арсеналі. Його суть полягає в тому, що ви зі сторінки витягуєте якісь дані.
Припустимо, є сторінка каталогу. Що ми можемо взяти:
- кількість товарів,
- кількість фільтрів,
- наявність блоку перелінковки,
- розмір SEO-тексту, якщо він там є, кількість символів у ньому.
За допомогою цієї інформації ви надалі зможете ефективно очистити сміття, порожні сторінки та шлак. Рекомендую використовувати JetOctopus, Screaming Frog, Sitebulb.
Читайте детальний гайд по работі зі Screaming Frog Seo Spider.
Технічка — без JavaScript. Todo
Плавно переходимо до того, що ми можемо зробити з Custom Extraction:
- Знайти пусті сторінки каталогів. Зрозуміло, що сайти різні, логіка генерації сторінок у всіх теж різна. Але це не рідкість, коли у вас 30-40% каталогів пусті. Тобто, на них колись були айтомси, але зараз їх немає. Це нормально для агрегаторів, інтернет-магазинів. Дуже важливо розуміти їх обсяг, щоб надалі робити будь-які дії: або закривати, або намагатися наповнити. Можна нічого не робити, якщо ви спарсили і побачили, що порожніх каталогів у вас лише 5%. У цьому випадку краще зайнятися більш пріоритетними завданнями.
- Знайти товари без опису: визначити обсяг цієї проблеми та наскільки ви можете доопрацювати, покращити цей опис або його спарсити, згенерувати.
- Визначити блоки перелінковки та кількість посилань у них. Завжди живіть із думкою, що десь відвалився блок із перелінковкою. Ви повинні з цією думкою засинати та прокидатися. Я не просто лякаю, це досвід. Коли щось генерується за певними умовами, а формула зламалася. І у вас немає перелінкування. Це можна робити і потрібно робити за допомогою Custom Extraction. Просто моніторте, що у вас все на місці, є посилання в тій кількості, яку ви очікуєте.
Технічка — JavaScript
JavaScript – це велика проблема. Ключовий момент у тому, що у нас html сторінка – це документ, і браузер взаємодіє з ним як із документом, він його читає. Цей документ може не повністю завантажитися. HTML спочатку розроблявся з урахуванням того, що може працювати на повільному інтернеті. Тобто півсторінки провантажилося, але вона вже працює, і ви можете взаємодіяти з нею.
З JavaScript це, на жаль, не так. З JavaScript воно або працює, або ні. JavaScript у цьому плані бінарний. Тут немає якоїсь золотої середини. Тому в нас тепер додається ще одне завдання – стежити, щоб усе не «зламалося» саме з погляду SЕО. Наприклад, сторінка нормально не ранжується Googlebot, або він не бачить весь контент, який є на сторінці.
Я рекомендую всім почати заглиблюватись у JavaScript. На Заході про це дуже активно говорять уже років зо два. Тому відкрити самовчитель JavaScript варто хоча б для того, щоб розуміти, що там що означає, тому що ви з ним рано чи пізно зіткнетеся.
Технічка — JavaScript. Todo
Що робити:
- Перевірити наявність JS помилок: відкрити «сайт — developer tools» в Chrome чи Firefox и подивитися те, що позначено червоним. По ходу ви вже почнете розуміти, що одна справа, коли у вас там фейсбучний скрипт не підвантажився, інша справа — коли ви бачите там Fatal error та інше в такому стилі.
- Визначити наявність критичних JS помилок. Це вже трохи складніше. Треба походити по сайту, по основним сторінкам. Прогулятися з AdBlock і без. Або з якимись популярними плагінами, тому що вони теж можуть «ламати» ваш JS код.
Як зрозуміти — критична помилка чи ні? Якщо півсторінки не відображається, то все зрозуміло. Але вам потрібно розуміти природу цих помилок, щоб надалі простіше на це реагувати. Тому краще сходити до програмістів, щоб вони вам пояснили, що з цього критично, а що ні. - Промоніторити правильність рендерингу сторінки під різними User-Agent. Вже всі в курсі, що для великих веб-сайтів потрібний Server-Side Rendering. Це дуже нетривіальне технічне завдання плюс недешеве. Існують певні оптимізації, коли програмісти роблять так, що роботам ми віддаємо сторінку з SSR (вже відренжений html документ), а користувачам віддається на Client-Side Rendering. Так само відбувається, коли Googlebot приходить з реальних IP-адрес або ні. Усі роблять по-різному залежно від обставин. Ваше завдання також чітко знати ці умови і перевіряти їх. Тобто ходите з телефонів під різними User-Agent і перевіряєте, що він працює. Я впевнений, що у великому інтернет-магазині є ціла армія тестерів, але SEO – це ви, і потім з вас буде попит.
- Відстежити наявність базових тегів: title, meta, meta=robots у HTML. Вони мають бути у сирому HTML, до виконання JS. Навіть якщо у вас випадає Client-Side Rendering, навіть якщо не реалізовано SSR. Ви відкриваєте через View source, а не Developer Tools, тому що він відображає HTML як «будинок дерева» після виконання JavaScript. Ці теги мають бути у сирому HTML, що б вам там не говорили програмісти. Цей пункт навіть не обговорюється.
- Наявність необхідного контенту та посилань. В інтернет-магазинах сторінки дуже великі, завжди максимально швидко потрібно відобразити перший екран. І всі блоки перелінкування, які ви маєте, повинні бути після завантаження сторінки, навіть при Client-Side Rendering. Тут завжди з'являється нюанс, що є Client-Side Rendering. Цей блок провантажується лише після того, як користувач підкручується до нього. Важливий нюанс: Googlebot і в Desktop, і в Mobile рендерить сторінку з дуже великим по висоті екраном. Якщо я сиджу за монітором, у якого висота пікселів 800, Googlebot у Desktop версії буде близько 9 тисяч пікселів, а для Mobile – більше 12 тисяч пікселів. Уявіть, що сторінка відкривається на телефоні, висота якого дорівнює 10 iPhone. Ви це можете проемулювати. У нас у JetOctopus є режим емуляції. Або просто пограйтеся з налаштуваннями, щоб усі блоки, які перевантажуються в Lazy loading, коректно відпрацьовувалися у Viewport браузера. Це ключовий момент для того, щоб ваша перелінковка та контент сприймалися нормально.
- Зміна title, meta після виконання JavaScript. Це дуже поширений момент, коли в сирому HTML у нас тайтл буде «Collaborator.pro», а після виконання JavaScript — «Collaborator.pro Біржа прямої реклами». Google сприйматиме у вас нормальний тайтл і це в принципі не проблема. Але навіщо робити ненормально, коли одразу можна зробити нормально? Просто цей момент потрібно буде пофіксити, бо рано чи пізно це проявиться. У Octopus у нас є окремий звіт. Я спеціально переглядав його, і у великих сайтів, які з Client-Side Rendering воно може вивалюватися на 5-10% сторінок. Тому тут все не подивишся очима, краще використовувати інструменти, щоби це знайти. У Screaming Frog це також є.
Якщо ви щасливий власник Server-Side Rendering, то контент у SSR та JS версії має бути однаковим. Звіряйте його, так само дивіться інструментами.
Кит 3. Краулінговий бюджет
Я дуже радий, що краулінговий бюджет стає заїждженим словом. Всі вже знають, что що це таке та як його збільшити.
Що робити з краулінговим бюджетом, якщо у вас великий сайт?
Тут є один нюанс, який всі знають, але не всі хочуть у це вірити: Googlebot не краулить весь сайт.
Коли у вас сайт від 100 тисяч сторінок, він його не буде краулити весь. Googlebot не краулер, як Jet Octopus, якому ви платите гроші за те, щоб ми пройшли весь сайт. Googlebot хоче відповідати на запитання користувачів. Якщо тільки частина сторінок вашого сайту відповідає на запитання користувачів, а все інше сміття, то це сміття йому не потрібне. Тому у вас сайт апріорі не скраулено весь, і в деякому контексті це навіть нормально.
Єдиний нормальний спосіб працювати із краулінговим бюджетом – це логи. Google зробив чудовий інструмент Crawl Stats. Але краулінговий бюджет — це не лише візити бота, а й сторінки, які відвідує боти і те, як часто він ходить на них.
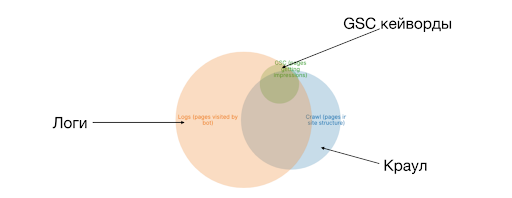
Один із способів графічної інтерпретації краулінгового бюджету — поєднати його з краулом. Це називається кола Еллера. У нас є три кола – логи, Crawl, GSC. Ви можете додати посилання з Ahrefs. На скрині вище ви бачите перетин логів (краулінгового бюджету) з краулом. Це те, як ефективно використовується ваш краулінговий бюджет. Ефективно у контексті того, що це у структурі сайту. Припустимо, ви знайшли каталоги, які пусті, тобто 20 тисяч сторінок, які вам не потрібні, і ви хочете їх видалити або закрити від індексації. Ви прибрали посилання: ні користувач, ні краулер не може знайти ці 20 тисяч сторінок. Але бот про них знає, пам'ятає і ходитиме по них. Область, що знаходиться поза краулом — по ній ходить бот. І ви не знаєте нормальні там сторінки чи ні.
Краулінговий бюджет. Todo
Ключові метрики під час роботи з краулінговим бюджетом:
- який % сайту у вас відвідується роботом. Саме відсоток сайту із структури. Якщо сайт 100 тисяч сторінок, а бот відвідує 200 тисяч. Ви думаєте, що це вогонь, подвоїли краулінговий бюджет у 7 разів, але не забувайте про структуру сайту. 100 тисяч — це ті сторінки, які ви створили, а 100 тисяч, що залишилися, — потрібно розбиратися, що це.
- які директорії та розділи відвідуються роботом. Є розділи, які більш важливі та грошові. Є те, що просто набивається контентом тощо.
- скільки сторінок бот краулить поза структурою. Розбивка за директоріями або вашими сутностями – це наступний етап для розуміння та розподілу краулінгового бюджету. І те, що бот краулить поза структурою, особливо на сайтах з історією (від 5 років і старше) — це дуже великий обсяг сторінок. Тому вам потрібно на них дивитися.
- % бюджету, що йде на «сміття», баги. Поєднали одні сторінки з іншими, вивантажили і просто переглядаєте: «сміття» це чи ні. Скоріше всього, там будуть якісь патерни, директорії. Якщо їх все одно залишається багато, наприклад, 70 тисяч незрозумілих сторінок, то ви берете ці сторінки, закидаєте в краулер, налаштовуєте Custom Extraction за кількістю товарів, наявністю контенту і т.д.
- % бюджету, який витрачається оптимально. Це буде одним із наших KPI: як ви оптимізуєте бюджет, що з ним відбувається взагалі.
Краулінговий бюджет — управління
Як керувати краулінговим бюджетом — основні тези:
- meta robots=noindex не допомагає для краулінгового бюджету. Адже щоб боту побачити meta-тег, йому потрібно скраулити сторінку. Боту потрібно періодично перевіряти сторінку, щоб розуміти, що ви його не прибрали.
- non-canonical сторінки вбивають краулінговий бюджет. На мій погляд, єдиний правильний спосіб використання canonical тега, це використовувати його як self-canonical. Це коли у вас простий канонічний url і тег canonical дорівнює цьому url. Це дозволяє захиститись від якихось трекінгових хвостів, які люблять ставити аналітики. Найгірше рішення: закрити сторінки фільтрів + сортування в non-canonical.
- robots.txt працює. Googlebot реально дотримується. Якщо це не так – перевірте все інструментами, а не очима.
Кит 4. Перелінковка
Усі про неї говорять, але ніхто не робить.
Простий постулат перелінковки свідчить: важливі сторінки сайту повинні мати більше внутрішніх посилань.
Звучить дуже просто. Але коли справа доходить до практичної реалізації, це дуже складно технічно.
Як робити внутрішню перелінковку на сайті, ми писали в матеріалі.
Як зрозуміти, що відбувається з перелінкуванням на сайті: за допомогою краулінгу. У вас є URL сторінки та кількість вхідних посилань на цю сторінку. Ви заганяєте ці дані в Excel (в Octopus для цього є вбудований інструмент) та групуєте:
- скільки сторінок взагалі не має посилань (вони тілько в Sitemaps),
- скільки мають 1 посилання,
- скільки від 1 до 10.
Таким чином, ви отримуєте групи сторінок.
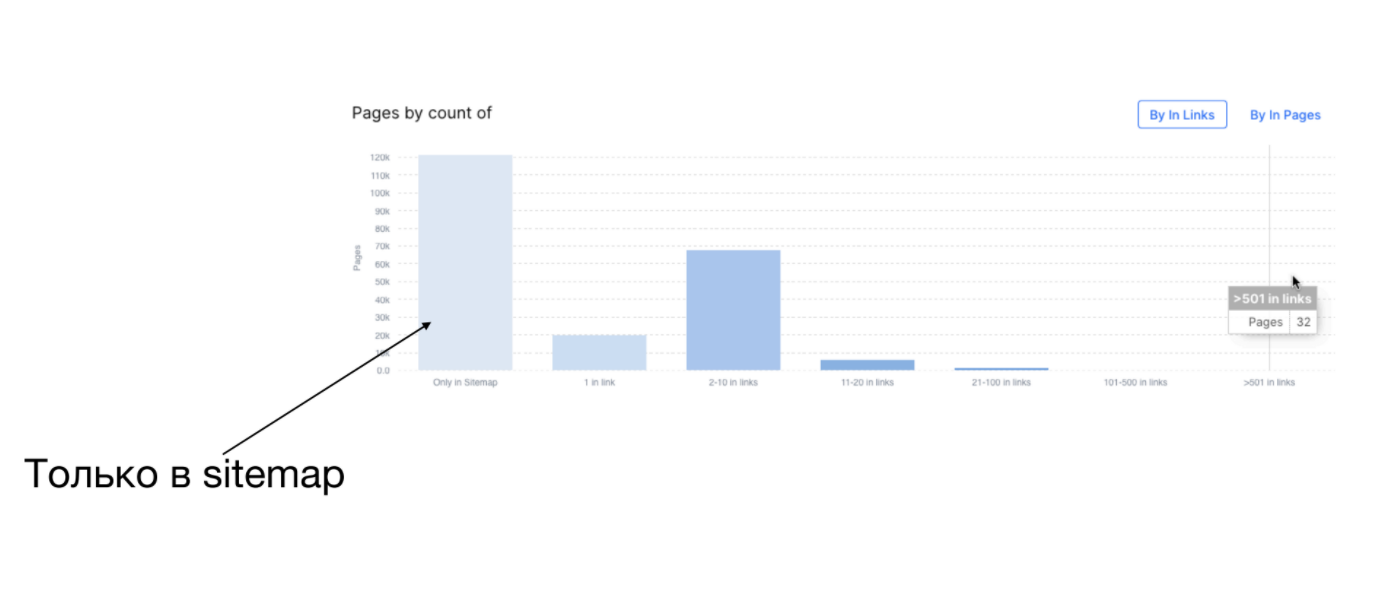
На скріншоті вище видно, що на великому сайті добре залінковано лише 32 сторінки, а решта мають від 1 до 10 посилань.
Перелінковка – це важливий чинник для краулінгового бюджету. Чим більше посилань веде на сторінку, тим вона вважається важливішою і зростає можливість того, що Googlebot прийде на неї.
Але це не єдиний чинник. Не думайте, що якщо ви наставите на сторінку купу лінків, то краулінговий бюджет одразу покращиться. Такий графік — це ваш стартовий етап для того, щоб зрозуміти, що у вас відбувається з перелінкуванням.
З таблиці видно, як у вас розподіляються внутрішні посилання та наскільки у вас є перекоси.
У 2019 році на Коллабораторі був вебінар з перелінковки, він актуальний, і я його рекомендую переглянути.
Ключовий момент у тому, що ви лінкуєте сторінки між собою не для роботів, а для людини. Поставте себе місце користувача. Перелінковка, яка реально працює, має бути видимою. Її має бачити користувач на основному екрані. Сірий текст унизу сторінки не працює.
Перелінковка. Todo
Чек-лист з перелінковки:
- Моніторити за допомогою Custom Extraction наявність блоків перелінковки на каталогах, товарних сторінках.
- Перевіряти наявність блоків перелінковки в raw HTML. Вона повинна бути в HTML відразу, не після прокручування сторінки, не після кліка у верхній лівий кут у непарну секунду😃
- Аналізувати перелінковку з погляду розділів/каталогів сайту. Адже будь-який великий сайт неоднорідний. І якщо все добре в одному каталозі, це не означає, що аналогічна ситуація в інших місцях.
- Перевіряйте min, max, median за кількістю внутрішніх посилань на каталоги. Це дозволить вам пріоритезувати дії. У вас можуть бути якісь погано залінковані розділи, але не можна все зробити ідеально.
Кит 5. Google Search Console Keywords
У Google Search Console є Keywords. Хоча GSC в цілому не найзручніший і найлегший інструмент, GSC Keywords – це дуже хороший тул з трьох причин:
- дає динаміку за часом. Ви можете робити вибірку по тижням чи дням.
- тут теплі дані. Це ваші дані, які реально ранжувалися. Були отримані impressions, кліки.
- за допомогою API ви можете легко працювати із цим.
Читайте відповіді на актуальні питання про роботу с Google Search Console в нашій Базі Знань.
GSC Keywords. Todo
В GSC дуже великий простір для оптимізації.
Що можна проаналізувати за допомогою GSC Keywords:
- Які сторінки мають impressions та clicks. Тому що у нас мільйон сторінок і завжди є внутрішнє відчуття, що половина з них має приносити трафік. Ви будете дуже здивовані, скільки реально сторінок вам приносить трафік.
- Який обсяг запитів канібалізований. Коли у вас за той самий Keyword конкурують різні сторінки. Це можуть бути дублі, якісь суміжні сторінки, які дуже схожі на інтент. На цю цифру слід дивитися з обережністю. У плані того, що ви маєте відсікати запити на регіональність. Тому що «купити iPhone у Києві» це одна сторінка, а у «купити iPhone в Одесі» — інша.
- Які кейворди миготливі – ранжуються не весь період часу. Тобто один місяць один, наступного – інший, і вони між собою починають миготіти. Це досить часта проблема, на яку варто звернути увагу.
- Які позиції дають вам трафік. Залежно від ніші трафік може бути або на 1 позиції або топ 3, або ви можете працювати до топ 10.
- Де PPC перебиває SEO. PPC це також класні хлопці, але можуть легко «вбити» вам CTR. Ви перебуваєте на топ 1, топ 3, а CTR у вас немає. Все тому, що є реклама. Це буває для низькочастотних запитів. Можливо, треба провести експеримент та просто їх відключити.
Бонус: Кого дивитися, читати, аби вчитися SEO: рекомендації Сергія Безбородова
Тут список чудових фахівців, з якими я дуже давно знайомий і рекомендую скрізь на них підписатися та читати:
- курси Игоря Баньковського (його доповідь про професійну внутрішню оптимізацію великих сайтів читайте у Блозі Колаборатора)
- Влад Моргун
- Стас Дашевський
- Гена Сивашов
У Блозі Коллаборатора раніше робити добірку книг для SEO-спеціаліста, а також зібрали базу SEO-шкіл, де можна вчитися оптимізації.
Висновки
Не обов'язково винаходити «ракету» або використовувати щось складне, починати краще завжди із простого.
SEO великих сайтів – це багато даних. Excel висне, CSV завжди велика. Тому якщо ви використовуєте Linux, то опануйте пару консольних команд. Це дуже допоможе у роботі.
Ефект на великих сайтах завжди відчутніший. Все, що ви робите на великих сайтах, буде помітнішим. Ефект від впроваджень у перелінковці, контенті на великому обсязі сторінок буде завжди відчутнішим. Або ви його взагалі не побачите.
Сесія Питання-відповідь
— Под 300 мільйонів, тому впорається.
— Це дослідження повинні ви зробити на своєму сайті. Багато наших клієнтів мали різні результати. У когось ставало краще, у когось гірше. Це не означає, що вам треба одразу щось відкривати чи закривати. Стас Пономар мав доповідь про те, як проводити експерименти. Є експериментальна група, контрольна. Берете кілька пачок схожих сторінок, на одній робите, на іншій ні, дивіться різницю. Ця різниця може виявитися в тому, як змінився краулінговий бюджет на цій групі сторінок. По GSC ви можете переглянути зміну impressions та clicks. І це буде замість тисячі слів. Просто спробуйте саме на своєму сайті.
— Раніше я любив Last-Modified, зараз не бачу від нього особливого ефекту. До того ж Last-Modified має працювати саме для HTML-сторінки. Там прописано як алгоритм, що Google приходить із окремим заголовком – Last-Modified дата, яка там була. Ідея в тому, що Google не розбиратиме сторінку, але з цим має сенс поекспериментувати, якщо у вас дуже великий сайт. Хоча б за 5 мільйонів сторінок. Якщо менше, то краще не морочитися.
— Насамперед треба йти до програмістів і запитувати, що вони робили. Вони, як завжди, скажуть нічого. Тому вам потрібно відкочувати зміни від цього нічого. Був прикольний кейс у одного з великих сайтів: адмін просто поміняв IP-адресу з тієї ж підмережі, внаслідок чого краулінговий бюджет обвалився з десятків мільйонів у нуль. У цьому кейсі допомогло те, що вони звернулися до Мюллера, який сказав, що напишіть звернення у форму на тій сторінці. Google у себе щось змінив, і краулінговий бюджет повернувся. Обвал крауліногового бюджету – це або потрапляння сайту під фільтри, або результат дій когось із команди, або щось «відвалилося». Тут теж потрібно розбиратися та шукати.
— Ніякий. Я стаю JS-ненависником, тому що він додав мені чимало сивого волосся 😃 Ми рік тому зробили JS-краулер. Усі зробили за мануалом, усе налаштували. Вихідного коду там було дуже мало. Після того як користувачі почали щось краулити, тепер у нас JS-коду та ще й з милицями море. Якщо ви все-таки хочете робити на JS-фреймворку, то найкращий JS-фреймворк — це той, для якого у вас є якісні програмісти. Не джуни, які не зможуть це нормально зробити. Як прокраулити JS-сайт? Будь-яким краулером.
— Тому що є нюанси реалізації Client-Side Rendering. У чому проблема JS-сайтів? Раніше було: завантажили сторінку і одразу ж з нею працюємо. Із JS-сайтами так не буває. Після того як завантажився базовий HTML, потрібно чекати, поки фреймворк завантажиться, поки ми зробимо кудись 10 запитів і т.д. А цей час, 10-20-30 секунд, ніхто не знає, скільки у Google тайм-аут стоїть. Ми прописали константу в 10 секунд. Я думав, що якщо за 10 секунд не завантажитись, то це дуже довго. У результаті тепер у нас цей час змінний. Деякі користувачі використовують навіть із 60 секунд, тобто, люди вважають, що коли стоінка вантажиться цілц хвилину, це нормально. У всіх різні погляди на індексацію сторінок, але що швидше, то краще. Можливо, через це ви не можете прокраулити у Screaming Frog.
— Ніяк. Не покладайте великих надій на Sitemaps. У Sitemaps добре додавати, коли у вас, наприклад, нові товари, які тільки залили. Sitemaps повинен бути маленьким і худеньким. Якщо ви хочете весь сайт загнати в Sitemaps, і думаєте, що все краулиться, то ні, так не буде. Використовуйте Sitemaps більше у плані – віддалені/оновлені сторінки, щоб їх бот швидше переобійшов. Тому що у Google дуже багато евристик щодо того, як їх перезавантажувати.
Інші відео доповідей з Першої SEO конференції дивіться в Академії Collaborator.