
- Поняття та терміни semantic seo
- З чого почати роботу: semantic seo strategy
- Інтент: чого насправді хоче користувач
- Сутність в семантичному SEO: що це таке
- Тематичний авторитет
- Зв’язки контенту: як це все між собою пов’язано та що таке Linked Out Data
- Структура і розмітка
- Корисні посилання
- Питання — Відповідь
Семантичне SEO — частина технічного SEO. Саме технічного, бо з терміну можна зрозуміти, що йдеться про контент. Але ключове саме в цьому розділі оптимізації — інтент та контекст.
Олеся Коробка працює з графами знань і пов'язаними аспектами технічного SEO. Автор Telegram-каналу SEObox.
На вебінарі Сollaborator 25 травня 2022 вона розповіла про основи та властивості семантичного SEO для тих, хто переорієнтується з російських ринків на західні. Про те, як працює семантичний пошук, які є секрети оптимізації контенту і за допомогою яких інструментів їх можна втілити.
Основні питання, які обговорювалися в доповіді:
- Інтент (пошуковий намір) + контекст — search intent & context
- Сутності — entities
- Тема і тематичний авторитет — topic authority
- Зв’язки контенту і пов’язані дані (LOD)
- Структура і розмітка
Далі — текст доповіді від імені Олесі👇
Поняття та терміни semantic seo
Якщо ви хочете виглядати дійсно професійно серед колег в західному корпоративному сегменті SEO, то краще не використовувати терміни з цього слайду, бо в цьому середовищі вони вважаються некоректними.

В інших сегментах їх можуть використовувати дуже круті спеціалісти. Але особисто я їх використовувати не рекомендую. До того ж вони не мають ніякого відношення до семантичного SEO.
Приклади таких термінів:
- Семантичне ядро
- LSI
- TF*IDF
- Оптимізація під BERT
Семантичний — означає смисловий. І в цьому полягає основна відмінність від інших видів алгоритму.
Семантичний пошук з'явився дуже давно. Розвивався досить жваво, особливо останнім часом. На слайді відображено головні віхи.

Семантичне SEO – це дисципліна технічного SEO, яка зосереджується на визначенні намірів запиту та відповіді на всі запитання, які можуть виникнути у користувачів щодо цього запиту (Bill Slawski).
Тут акцент робиться на тому, що це саме частина технічної оптимізації. Бо багато вважає, що семантика — то лише про тексти.
Варто пам’ятати, що Google прагне ранжувати той ресурс або сторінку, які можуть коректно відповісти на максимальну кількість запитань користувача. Для оцінки всіх факторів, що впливають на ранжування використовується скорингова система.
З чого почати роботу: semantic seo strategy
Як було раніше і як це можливо робити і зараз, дещо оптимізувавши процес:
- Оптимізатори збирали ключові слова і за ними писали контент. Наприклад, за допомогою сервісів типу Keyword Chef або будь-яких інших, які вам подобаються..
- Потім вичищали зібраний список. Наприклад, за допомогою класифікатора в Open AI
- Кластеризували — об’єднували слова в групи. Безкоштовний, але не самий надійний інструмент SEJ - Semantic Clustering Tool

Читайте в Блозі матеріал на тему створення семантичного ядра під бурж vs рунет.
Описаний спосіб вважається в семантичному SEO довгим та дорогим. У ньому досить багато ручної праці.
Інший варіант початку
- Визначаємося з темою та підтемами.
- Будуємо структуру ресурсу і документів з урахуванням інтенту споживача.
- Складаємо словник або використовуємо той, що вже існує, або вибираємо потрібну онтологію.
Нижче наведено спрощений приклад для Face Recognition Technology
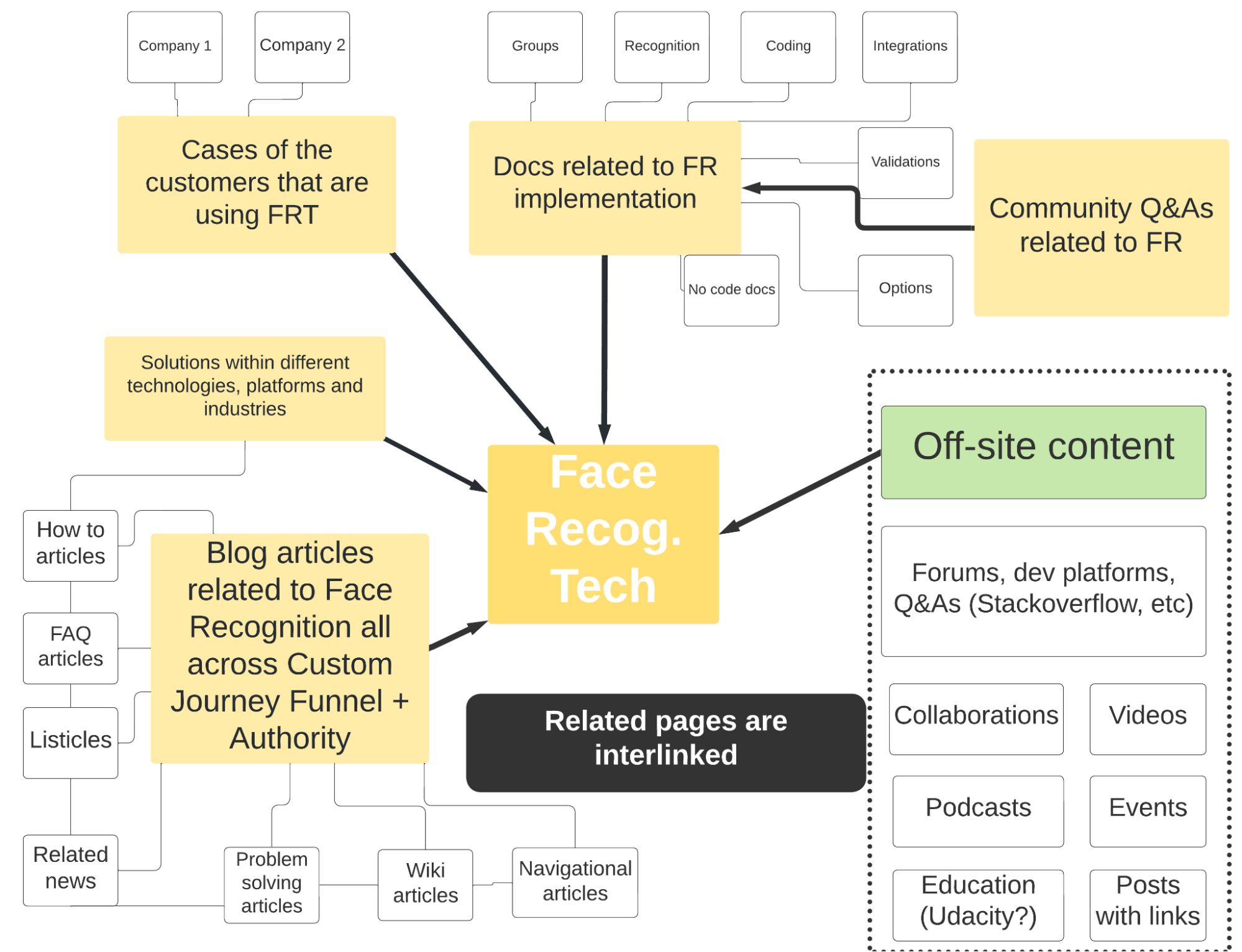
Інтент: чого насправді хоче користувач
Google вкладає багато ресурсів у вирішення питання, що шукає користувач та що він хоче побачити на сайті. У пошуковика склалася така система:
- Google на основі тієї бази данних, що вже є, та на основі предикативу переписує всі запити, аби ідентифікувати канонічний запит, що буде визначати всю групу схожих запитів.
- Якщо таких запитів декілька, намагається «вгадати», який найбільш вірогідний. Ймовірність у випадку неоднозначності визначається за скоринговою системою, тобто присвоюються на різні випадки різні бали і Google ще вибирає: або він дає відповіді на різні інтенти і присвоює бали для вибору, або він не показує варіанти з малою кількістю балів;
- Враховує до уваги контекст. Контекст завжди динамічний. На нього впливають: локальність, мова, попередні запити, сезонність, актуальність/новини/реальність.
- Ідентифікує сутності в запиті споживача. Та на їх основі може додавати інші функції видачі. І юзер бачить не лише посилання на сайти, а й галерею зображень, панель знань, мапу, PAA, Related, web stories тощо.
Читайте більше про технічне SEO:
Сутність в семантичному SEO: що це таке
В розумінні Google сутності — це спроба оцифрувати реальність. Все, що пошуковик знає про всесвіт у цифровому вигляді. Поняття, люди, івенти тощо — все це ідентифікується, йому присвоюється номер і Google намагається віднайти значення цього слова/поняття/концепту і його співвідношення з іншими словами/поняттями/концептами в базі даних.
Це дозволяє оперативно видавати результат. Адже для пошукової системи швидкість понад усе.
Завдяки прошаркам в графі знань Google може дуже швидко відповідати на комплексні запитання. Це виникло з RDF (формат представлення даних). Для нього характерні Трійки.

Це означає, що всі об’єкти та сутності пов’язані між собою. І це те, що їх між собою зв’язує.
Наприклад, «Я пішов до школи». Тут «я» — одна сутність, «школа» — інша, «пішов» — той реляційний зв’язок, що між ними існує.
Оптимізація під сутності
Варіанти:
- Спільна поява сутностей і фраз в топ-10-30 конкурентів. Ви виявляєте ці фрази і розміщуєте собі на сторінку для кращого ранжування. Але важливо, що ці фрази мають бути закінченими в собі і бути релевантними саме для вас.
- Парсинг корпусу даних або графів, яким довіряє Google, в пошуках релевантних сутностей.
- Відповідь на всі запитання, які можуть виникнути у користувача за сутністю і інтентом.
Популярні інструменти для аналізу конкурентних фраз (п. 1):
- Ryte,
- SurferSEO,
- PageOptimizer Pro,
- Cora,
- Frase,
- Marketmuse,
- Clearscope,
- ContentHarmony,
- Thruuu,
- Outrank,
- Inlinks,
- UseTopic
Як естрактувати сутності (інструменти)
З тексту
- Inlinks
- Streamea by Charly Wagnier
- IBM Watson — Demo
- Google Cloud NL AI API
Із зображень
- Google Vision API — можливо навіть в Google Cloud SDK (бо не завжди граф знань віддає). Важливо: Vision API давно не використовується Google як внутрішній алгоритм, він повністю від’єднаний. Тому, якщо сильно покладатися на нього для оптимізації, то не завжди можна отримати очікуваний результат. При цьому екстрактувати сутності з ним дуже добре. Ще важливо: при екстракції сутностей враховується контекст, в якому зображення знаходиться. І на одному й тому самому зображенні можуть бути ідентифіковані різні сутності з web.
- Entity Explorer. Відображає сутності image tab — таба зображень в Google.
З Wikipedia
Лайфхак, щоб обігнати конкурентів — брати сутності з Wikipedia. Як це зробити: берете сторінку Вікіпедії з потрібним вам терміном/поняттям, екстрактуєте звідти сутності та використовуєте в своєму контенті.
Рекомендації та корисні посилання:
- переробіть під себе цей скрипт
- Missing Topics — відео. Адаптувати інформацію звідси.
Парсинг Wikidata
Більш складний спосіб, проте теж дієвий.
- Через API збираємо всі сутності, що можемо знайти
- Потім збираємо properties по цим сутностям. Вони допоможуть характеризувати сутності в тексті більш ефективно і виявити атрибути, що можуть бути притаманні цим сутностям.
- Доповнюємо парсингом по Wikipedia -> DBpedia
- Після цього можна формувати питання та відповіді на них, можете спарсити People Also Ask та генерувати вже інші питання під свої потреби тощо.
Застереження про сутності
Що часто роблять некоректно, коли займаються сутностями:
- скоріше за все, нам не потрібно створювати другу Wikipedia;
- сутностей може бути забагато — отримуємо зворотній ефект. Контенту багато, а розмітка надмірно детально описує всі сутності;
- обираються не ті сутності, не там, не так;
- невалідний код — Google не читає;
- некоректна структура — Google не розуміє.
Тематичний авторитет
Про тематику і мапу теми вже говорили вище. Якщо ви запустили ресурс і він вже був вперше перевірений Google, а в умовну топ-1000 ресурсів з цієї теми ви НЕ потрапили, то зробити щось з таким ресурсом далі буде дуже важко. Google може не перераховувати бали по ньому дуже довго і навіть не робити це в core update. Тому важливо одразу робити все добре, і тільки потім показувати пошуковій системі.
Як потрапити в умовні топ-1000 ресурсів своєї тематики:
- використовуйте різні типи, формати, інтенти. Бажано не зосереджуватись тільки на одному інтенті й форматі. Адже більш різноманітний контент більше задовольняє запит споживача;
- сприймайте все як сутність: сторінки, авторів, веб-сайт, бренд.
Зв’язки контенту: як це все між собою пов’язано та що таке Linked Out Data
На сайті вкрай важлива перелінковка.
Буває:
- контекстна (найбільш корисна);
- загальна;
- Linked Out Data (LOD) — пов’язані дані. Це ідентифікація даних на вашій сторінці за допомогою різних ідентификаторів.
Що важливо в Linked Out Data:
- Ідентифікуйте через URI.
- Не потрібно створювати фізичні посилання в тексті, але анотувати можна, це теж пов’язані дані (треба тестувати для свого проекту).
- DBpedia — це теж LOD.
- Ви теж можете додавати дані до Linked Open Data Cloud, наприклад, через датасети.
Читайте також наш материіал про те, як правильно робити внутрішню перелінковку на сайті.
Структура і розмітка
Найголовніше — валідний код, такий, який може сканувати і коректно розуміти googlebot і інші боти. Популярний валідатор — validator.w3.org. Дещо застарілий, проте підходить для простих речей.
Неструктуровані дані
- Google вже добре екстрактує;
- структурує сам;
- відображає сніпети;
- великі сайти мають навчені парсери від Google.
Напівструктуровані дані і, які ми для спрощення називаємо структуровані :)
- Розмітка.
- XML
- JSON, etc.
Розмітка має бути коректна, незаспамлена, одного формату. Краще розмічати менше, ніж багато та некоректно. Або розмічати все. Пріоритет — красивим сніпетам і функціям видачі. Ієрархічно.
Детальніше про розмітку Як зробити мікророзмітку FAQ на сайті
Деякі приклади, що краще розмітити:
- Breadcrumbs;
- Website — на головній + searchAction, якщо актуально;
- Corporation/Organization на About Us;
- Авторів, якщо є блог або форум;
- Продукти і сервіси (сервіс може теж бути продуктом).
Корисні посилання
Корисні посилання, що рекомендувала Олеся до та під час вебінару. Всі основні посилання по семантичній павутині (просто щоб були, всі читати не потрібно 🙃)
- GitHub - semantalytics/awesome-semantic-web: A curated list of various semantic web and linked data resources.
- Що таке semantic SEO
- Як працює ранжування в Google
- Ключові слова і автозаповнення
- Класифікація запитів
- Кластеризатор
- Про переписування запитів №1
- Про переписування запитів №2
- Приклад теми
- Semantic-web для початківців
- Що таке семантичний пошук
- Семантичний пошук (Біл Славскі)
- Скорингова система ранжування в Google
- Про Topic Layer в графі знань
- Коротесенький гайд з онтології
- SERP features — функції видачі
- Один з прикладів аналізу сутностей
- Зареєструйте акк в Open AI - Personal, якщо ще не маєте. Вони дають тріалку 18 $ на перший час
- Генерація питань
Питання — Відповідь
— Мені здається, найкращий спосіб — через друзів, знайомих, партнерів. Нетворкінг. У багатьох моїх знайомих SEO-спеціалістів навіть немає сайту власного. Я не шукаю останнім часом клієнтів. Але якби шукала, то пішла би до друзів і сказала: «Мені потрібні клієнти», і вони б мені щось накидали:) Або через LinkedIn.
Дивіться конспект вебінару про пошук клієнтів в LinkedIn з Юлією Венцковською.
Ще варіант — відвідувати профільні конференції. Обрати нішу та в неї занурюватися.
— Це може бути API Wikidata. Деякі графи закриті, ви не зможете отримати API для їх парсингу.
Google, наприклад, не дає парсити свій граф. Дуже лімітовано його відкриває. У нього є Knowledge graph API, який не віддає все (парсити дає тільки основний граф). Пошуковик зашифровує інформацію про свій граф, бо це має прямий вплив на його результати видачі.
— Я цього не роблю, тому я не знаю досконально. Проте є методики, які орієнтуються на ці дані. І досить успішні.
— Я дуже хочу кодити на Python, але не вистачає часу на це. Проте це чудово, якщо ви можете це робити. Можна швидко написати самому, що вам потрібно, і швидко це використовувати. Будь-яке API, будь-який інструмент, який ви використовуєте. Якщо ви працюєте з семантичним SEO, я вважаю, що елементарне розуміння кодингу краще мати. У таких спеціалістів і зарплатня більша. Знову ж таки, якщо ви добре володієте кодингом, то не знаю, що ви робите в SEO, адже можете заробляти більше як програміст.
— Семантичне SEO — це технічне SEO. І насичувати сутностями більш складно, якщо мова йде про текст. Але деякі теги ви можете змінювати в templates, якщо в вас є.
Щодо прикладів — треба подумати. Проте є великі сайти, які поступово втілюють рекомендації з семантичного SEO. Зможемо потім подивитися, які результати вони отримують.
— Я не намагаюся охопити на одній сторінці декілька інтентів. Є таке поняття канібалізація, в яке я не вірю, тому що в мене, якщо брати ключове слово, може бути 5 сторінок, які оптимізовані класичним методом під це слово. Проте вони не заважають одна одній, бо в них різні інтенти. Я вважаю це правильним — створювати під різні інтенти різні сторінки, і зв’язувати їх посиланнями одна на одну. Наприклад: сторінка про продукт, про його характеристики, про рецепти, що можна робити з його допомогою, порівняння з конкурентами тощо. З іншими сутностями пов’язую в розмітці.
Від всієї команди Collaborator та слухачів вебінару дякуємо Олесі за змістовний та дуууже технічний вебінар🦾 Успіхів у подальших освітніх та SEO-проектах.






{kind=link}