SEO-специалист Владислав Моргун на вебинаре рассказал о решении 10 главных задач технической оптимизации сайта.

Философия
Чтобы мы с вами настроились на один лад, начнем доклад с философского отступления. Не секрет, что заголовок является достаточно байтовым.
По факту, нет 10 главных задач или 10 решений этих задач, которые можно выполнить в техничке, и все станет сразу хорошо. Да, есть различные CMS, например, WordPress, Битрикс и т.п. Они все достаточно похожи и имеют одни и те же недостатки. В то же время у каждого в команде есть свой разработчик.
Каждый разработчик – это творец. И то, что он может сделать или случайно пропустить, всегда является уникальным действием, потому и нет этих 10 главных решений.
Мы поговорим о сканировании, индексации, немного затронем скорость. Я поделюсь нашим опытом: как мы с этим работаем, за чем следим и т.д. Также я хочу поговорить немного на тему "Knowledge Graph и его разметка" – тема не совсем популярная у нас, но популярная на западе. Здесь я покажу основные вещи и проблемы, с которыми вы, возможно, будете сталкиваться.
Держите в голове мысль, что Google тоже хочет заработать. Как нам нужно кормить своих детей, так и Сергею Брину, Ларри Пейджу и тысячам гуглоидов как-то нужно зарабатывать. Поэтому многие вещи у них направлены конкретно на это. И чем вы лучше помогаете Google заработать, тем он больше поможет вам в вашем SEO.
Мы с вами будем обсуждать три модуля: сканирование, индексация, рендеринг
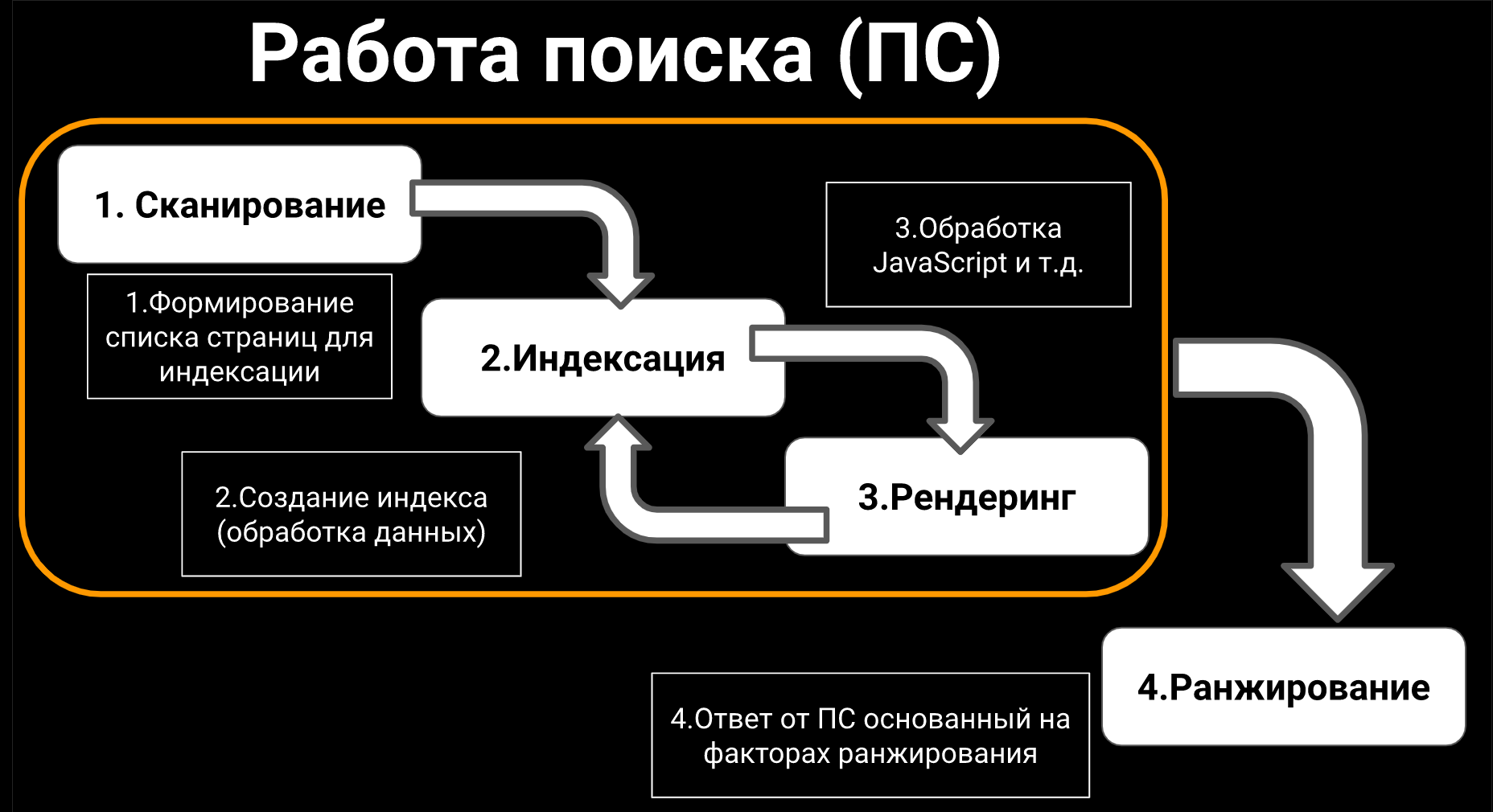
Многие сеошники, даже которые имеют внушительный опыт работы, могут путать сканирование и индексацию.
Сканирование – это формирование списка страниц для последующей индексации.
Индексация – это создание базы и обработка данных внутри этой базы.
Сохраняем html, разбираем, что там написано, какие есть теги, как их учитывать и т.д. Если у вас сайт работает на JavaScript-фреймворке либо есть элементы, которые добавляют контента, то вступает в дело еще и WRS (web rendering service), который помогает Google достать какой-то дополнительный контент.
Краулинговый бюджет, robot.txt, etc
Краулинговый бюджет
Все технические seo-специалисты разговаривают только о краулинговом бюджете сайта и о том, как его сохранить.
Crawl volume (краулинговый бюджет) – это количество запросов, которое было произведено Google по вашим документам. Когда речь идет о документах, это могут быть и страницы сайта, и pdf, и js и т.д.
За 10 минут до начала вебинара, когда я писал пост в Facebook, я почему-то вспомнил блоговый пост Google Developer от 2008 года. Он назывался "Свидание с Google Bot". Тогда Google еще был маленькой компанией, которая не боялась экспериментировать с формами, поэтому они выпустили такой пост в стиле диалога.
Здесь был один интересный момент. Если назвать свой файл как угодно, например, "page.lol", а не ".html", что Google будет с этим делать? Будет ли он сканировать такую страницу либо нет? На что Google ответил: "Да, конечно. Я попытаюсь проверить контент type. Если я увижу в исходном коде html, то закрою на это глаза".
И таких моментов в этом посту достаточно много, поэтому советую читать в блоге не только свежеопубликованный материал, но и вышедший, например, 10 лет назад. Кстати, советую читать на английском языке, потому что Google любит переводить довольно свободно (например, "дополнительная ценность" как "уникальность"). Он не нанимает для перевода людей, которые пытаются подобрать термины, плюс старые блог-посты никогда не переводились на русский язык.
Настройки Crawl Stats
Как вы можете проверить краулинговый бюджет, начиная с самых простых шагов? Самый элементарный способ – это посмотреть новый отчет в настройках, которые называются Crawl Stats в Google Search Console.
Большинство сео-специалистов смотрит на него так: заходим в Crawl Stats, смотрим на нашу динамику (мы выкатили новые страницы, стало больше Crawl; сайт у нас полежал, стало меньше Crawl).
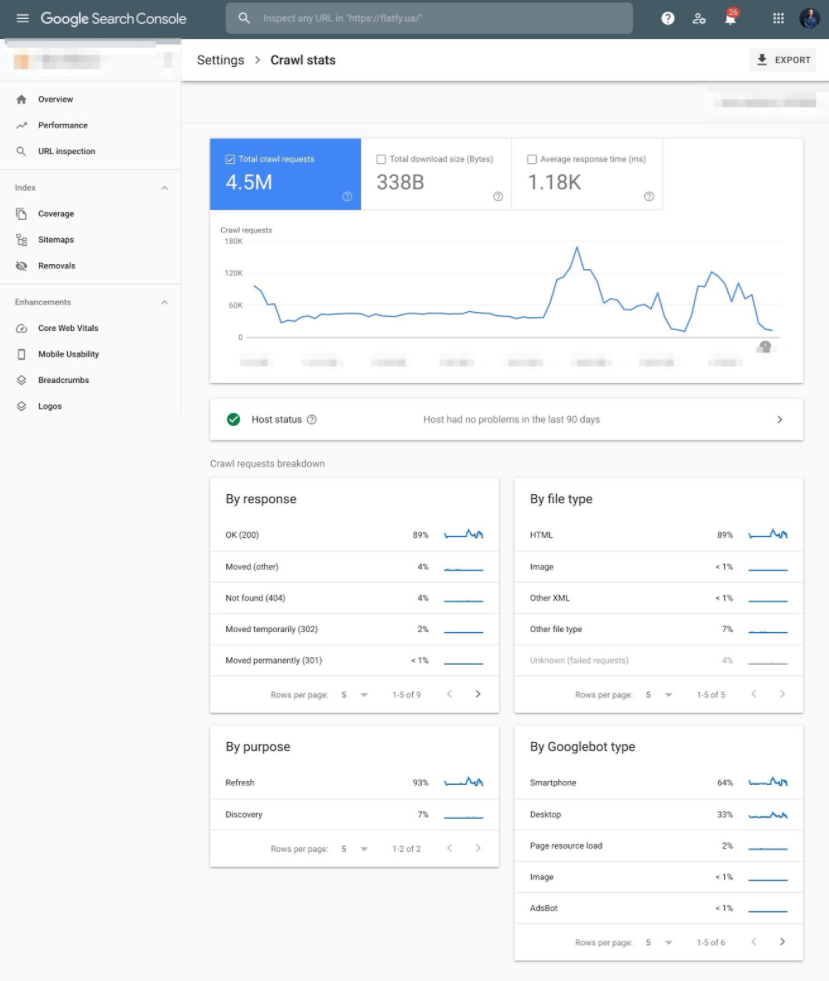
Но по факту, кроме динамики есть два очень важных поинта, на которые нужно смотреть.
Первый поинт, это опуститься пониже и посмотреть на различные break down. Существуют break down по типам google-ботов (заходил ли googlebot, чтобы обновить либо найти новые данные), а также по типам ответов (по ответам веб-сервера) и типам файлов (HTML, JS, JSON ит.д.). По моим наблюдениям многие просто смотрят 1-10%.
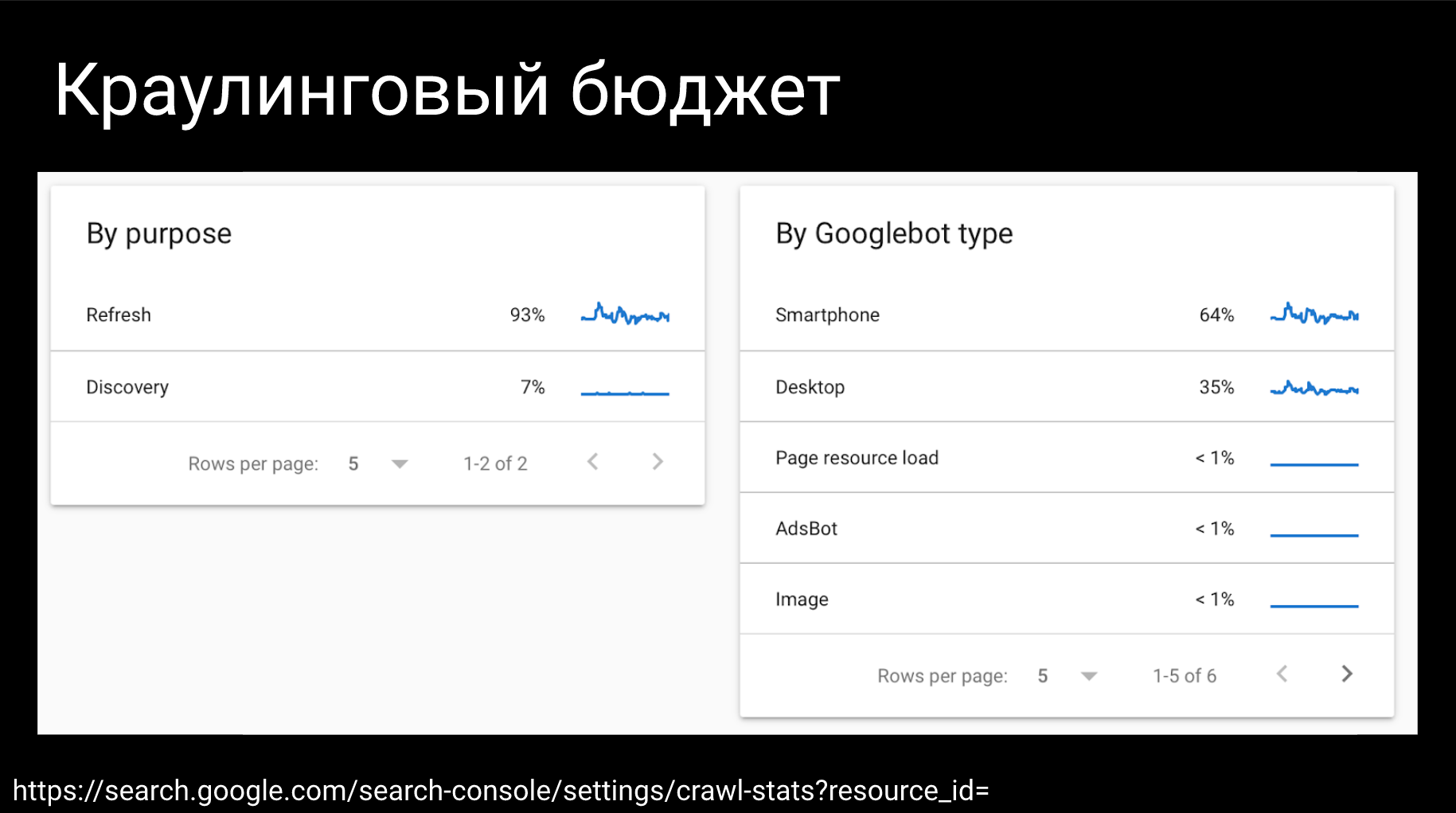
Мой совет: не пытайтесь использовать фильтры, опускайтесь внутрь этих категорий, например, по тем же типам файлов или по типам ответов. Когда у вас нет доступа к логам серверов, очень часто Google Search Console может вас спасти и показать те ошибки, которые вы могли не найти.
Например, недавно у нас было два кейса.
Первый кейс был с пагинацией: Google определенным образом перешел на внутреннюю страницу (страницу пагинации), а потом смог добавить get параметр пагинации к главной странице и погнал перебирать domain.com, page 1, 2, 3 и так до бесконечности. Без логов я никогда бы этого не нашел, но Google Search Console здесь здорово помогла.
Второй кейс: сайт переезжал с одного домена на другой. Старый сайт был не лучшим образом засеошен, и вместо ЧПУ страниц у него было много get параметров.
При переезде все сделали красиво, сделали редиректы, но Google вспомнил старые страницы. Начал перебирать все эти параметры и заходить по ним на новый сайт. Новый сайт, к сожалению, к этим параметрам не был готов. То есть вместо того чтобы на неизвестный параметр выдать 301 redirect на известную страницу или хотя бы 404, здесь начали генериться двухсотые страницы.
Именно такие вещи можно заметить даже в отчете Crawl Stats. Советую пробовать фильтровать по каким-то небольшим категориям, потому что у вас есть лимит в 1000 строк.
Парсинг данных
Если у вас достаточно большой сайт, но при этом нет доступа к логам и, при этом есть доступ к Google Search Console, вы можете это даже автоматизировать. Поскольку в этой части Search Console нет API, самый простой вариант – взять Selenium.
Selenium – это библиотека для тестировщиков и, в то же время Extension для Google Chrome, в котором можно записать свои действия. Записать нажатие на фильтр, вписать туда определенную категорию и нажать кнопку сохранить файл csv.
Вот так можно Селениумом прогонять эти автоматические скачки, например, раз в неделю.
Можно поступить и более круто. Взять библиотеку "Watir" или руки Junior специалиста, который иногда будет выгружать вам эти ошибки и отдавать просто файлы. Посадить джуниора на полчаса потыкать кнопки – это самый простой и дешевый вариант.
Когда у вас соберется достаточно много данных, вы даже без логов по ним сможете найти какие-то большие ошибки по типу тех кейсов, о которых я рассказал.
Особенности отчета Crawl Stats
Если вы используйте домен property или url property, то у Crawl Stats имеется небольшая особенность. Когда вы используете url property, который еще называется url-префикс (на первой пишите "http///domain.com"), то в отчете Host Status вы получите только маски url и больше ничего. Если же вы добавляете домен property, то вам покажутся все хосты, какие только могут быть.
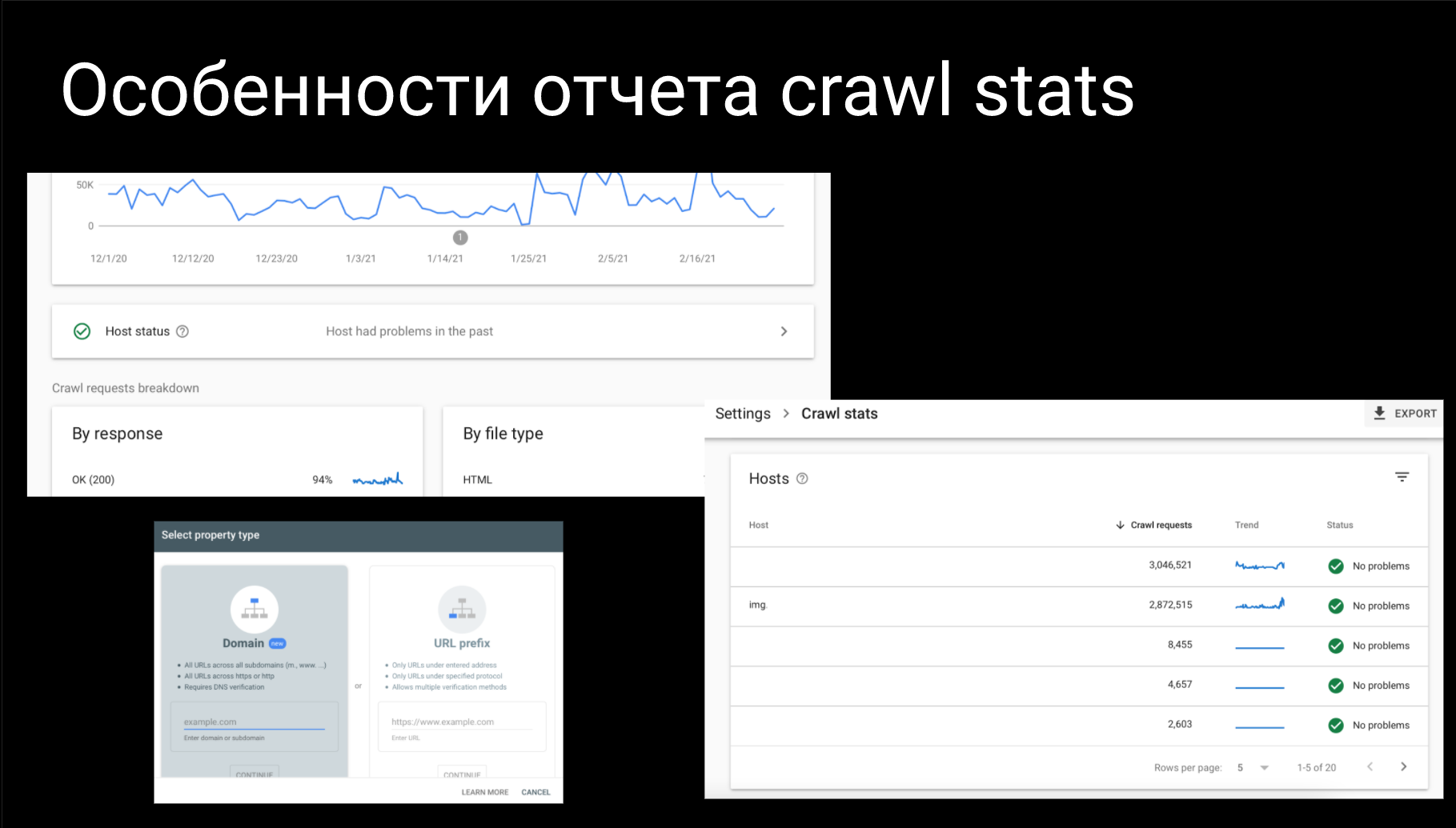
К сожалению, я не смог показать на скриншоте домены, поэтому здесь много белых пробелов. Идейно там много субдоменов, точнее 20 штук, по которым показываются данные.
В чем суть? Суть в том, что вы не всегда можете знать, какие у вас есть субдомены либо как Google с ними работает. Например, на данном сайте кроме основного домена есть еще отдельный субдомен под картинки. Как оказалось Google их активно качает. На небольшом графике (во второй строчке около 2 млн. запросов) видно большой пик в конце.
По таким графикам можно распознать изменения в продукте, которые вы установили.
Например, вы поменяли дизайн и решили сделать картинки товаров меньше, то есть вы их физически сделали меньше. Что должна сделать в данном случае поисковая система? Поисковик начнет перекачивать все эти картинки, в результате чего заберет на это весь краулинговый бюджет.
Тем, кто с таким не сталкивался, советую посмотреть крутой кейс Pinterest. Они в своем блоге рассказывали о том, как в свое время они поменяли дизайн, перегенерили сотни миллионов картинок. В результате чего потеряли массу трафика, вылетели с выдачи, потому что Google отреагировал на новые картинки проверкой на соответствие. В конечном итоге Google их очень долго перепроверял, пока Pinterest не вернул известные поисковику картинки назад.
Аналогичная ситуация может быть и с техническими проблемами. Например, у вас отклеился redirect 3W. Если сайт очень старый, и он начал по какой-то причине индексироваться, вы как раз увидите это в отчете Crawl Stats.
Либо к вам мог кто-то подселиться, я встречал такие кейсы. Вы заходите в домен property и видите, что у вас появился субдомен блога. Начинаете проверять и выявляете, что к вам подселился какой-то сайт-казино со своим WordPress.
Такие вещи очень хорошо отслеживаются в Crawl Stats. Плюс, если вы видите отчеты по всем субдоменам, то можете по хостам посмотреть отчеты по доступности Robots, DNS и серверов.
Важные отчеты
Если вы работаете в нишах "your money or your life" и происходит ситуация аналогичная показанной на скриншоте (кейсы из медицины), есть вероятность того, что вы улетите из топа как минимум на неделю.
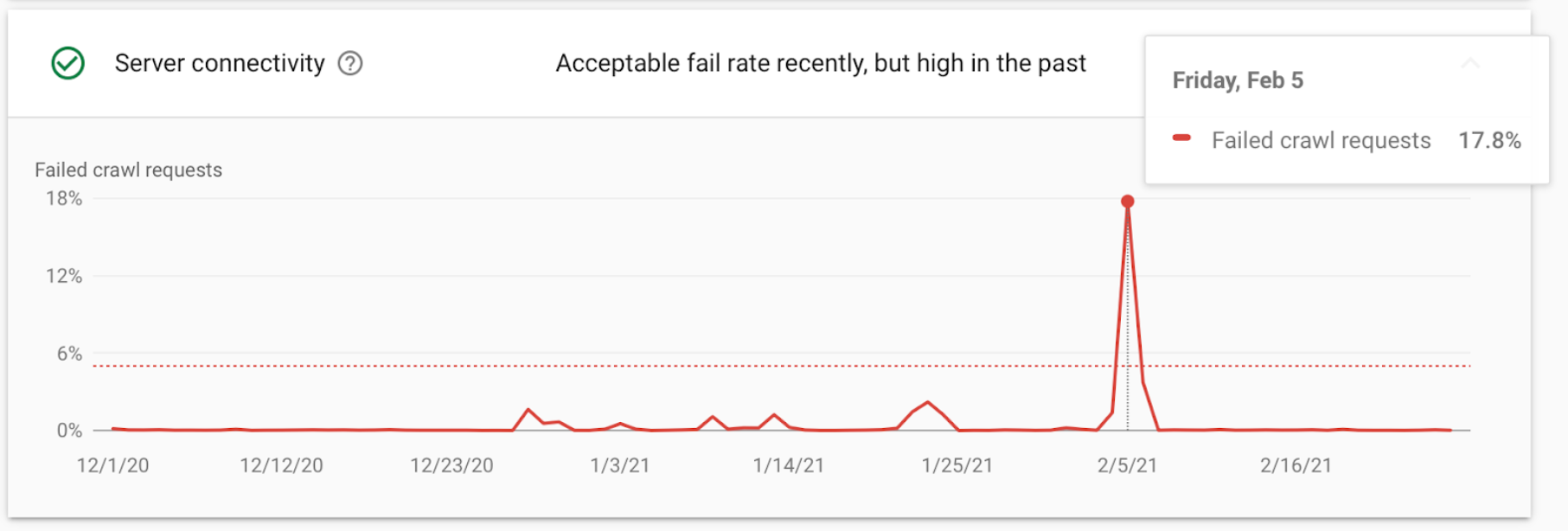
Почему? Потому что если человеку нужно срочно узнать о болезнях или найти врача, то Google ему будет показывать сайты, которые действительно работают и работают в данный момент. Если же сайт по какой-то причине отдает "пятисотки", то Google его не будет учитывать до тех пор, пока сайт все не поправит.
Многие могут сказать, что такое происходит с каждым сайтом, но это не совсем так. По моему опыту, например в тематике "туризм", я немного "завтыкал" со своим блогом. Сайт отдавал "пятисотки" несколько дней, но из топа не выпал. Почему Google так решил непонятно, но видимо тематика "туризм" для него не такая важная. Хотя там 100% была "пятисотка" и, он все эти ошибки видел.
Uptime
Если вы работаете со своим продуктом, будьте активными сеошниками и пытайтесь проверять все, даже если у вас классная команда разработки и они все за вас делают. Воспользуйтесь хотя бы бесплатной версией Uptime робота, который вам покажет по какой причине у вас отвалилась главная и т.д.
Зачем это нужно делать? Да, разработчики следят, они все увидят, но они могут элементарно вам об этом не сказать.
Например, если шатало сервер, кто-то его перезагружал, обновлял или проводил технические работы, а вы об этом не узнали. Как результат на следующий день, трафик провалился. Тогда вы начинаете смотреть ссылки, кэш Google и т.д., а причина была на поверхности и, просто нужно подождать пока Google потянет сайт обратно. Чтобы не терять время, пытайтесь это проверять даже простыми методами.
Логи сервера
Если вы уже продвинутый сео-специалист и у вас есть доступ к логам сервера, то становится все немного повеселее. Несмотря на то, что обновление Search Console – лучшее, что происходило за последнее время с Вебмастерами (Вебмастером Яндекса, Google, Bing суммарно), данных там может все-таки не хватать. Я до сих пор страдаю за некоторыми отчетами, например, по типу дублированных Title. Я понимаю, почему это сделано, но все же.
Если вы уже перешли от анализа Search Console или других простых инструментов к логам, то давайте рассмотрим эти кейсы.
Лог сервера – это файл, в котором есть системная информация о работе сервера и действиях различных пользователей о запросах к этим серверам. Проще говоря, это файл с записями о запросах (hit'ax), которые получил сервер.
Если вы работали с Google Analytics, то принцип действия очень похож. То есть каждый раз, когда у вас выполняется код Google Analytics, то входит так называемый хит. Здесь все аналогично: кто-то запрашивает документ с вашего сервера, идет запись в лог сервера об этом хите.

Например, этот хит может выглядеть как на скриншоте: идет ip, с которого был сделан запрос, затем идет Times Temp (дата + время + часовой пояс), дальше – тип запроса (гет, пост, получить, отправить, head, deleted и т.д.).
После этого идет документ, к которому был запрос (это может быть страница, pdf), потом может идти тип запроса http1, http2, затем ответ веб-сервера (200, 500, 404). В конце идет user agent – строка, которая описывает, кто сделал запрос (например, Mozila Firefox c Linux либо googlebot).
На этих достаточно простых данных можно находить больше количество различных ошибок, о которых мы поговорим ниже.
Софт
Перед тем как говорить об ошибках, их нужно каким-то способом найти. Если у вас небольшой сайт и немного логов (до 100-120 тысяч строк), то в принципе вы можете использовать даже простой Excel. То есть вам разработчик отдает текстовый файл, вы вставляете его в Excel, нажимаете на "данные разделить по столбцам" и дальше работаете со сводными таблицами. Но для 100 тысяч нужно иметь достаточно маленький сайт.
Вы должны помнить, что как только пользователь запрашивает страницу, сразу запрашивается несколько JS и CSS, количество записей растет достаточно быстро, поэтому здесь нужно использовать какой-то специализированный софт.
Cофт, которым я пользовался в случайном порядке:
- ELK
- Splunk
- Screaming Frog SEO Log Fail Analyser
- Sumo Logic
- Botify
- OnCrawl
- Dataiku
- SemRush
- JetOctopus
Если расположить данный софт не в случайном порядке, а по мере того, что мне больше нравится и чаще мной используется, то на первом месте я оставил бы ELK.
Из покупного на одном уровне находятся JetOctopus и Botify. У JetOctopus небольшое преимущество – цена-качество. Botify классный, но слишком дорогой. Здесь французы из Botify немного перегибают.
Дальше, по моему мнению, их догоняют OnCrawl (недорогой, но свои задачи выполняет), SemRush.
Затем Screaming Frog SEO Log Fail Analyser – это самые дешевые аналайзеры, они показывают простые данные. Сложные сегменты оттуда достать нельзя, но с них вполне можно начинать работать.
На последнее место я поставлю Sumo Logic и Dataiku по той причине, что в СНГ разработчики их используют гораздо реже, чем остальные. Плюс фишки в стиле искусственного интеллекта, которые они рассказывают, в SEO никак не помогают.
ELK stack
ELK (Elasticsearch Logstash Kibana) – это open source движок, который состоит из трех частей.
Logstash – это махина, которая с помощью битсов собирает ваши логи из разных сайтов, серверов в одно место, формирует и нормализирует их. У вас могут быть разные веб-сервера с разными форматами, Logstash пытается привести их к какому-то одному виду.
Дальше все эти данные ложатся в поисковую систему, которая называется Elasticsearch и уже на основании этой поисковой системы работает Kibana. То есть это интерфейс с визуализацией, через который вы можете сделать различные запросы. На скриншоте показано, как это выглядит.
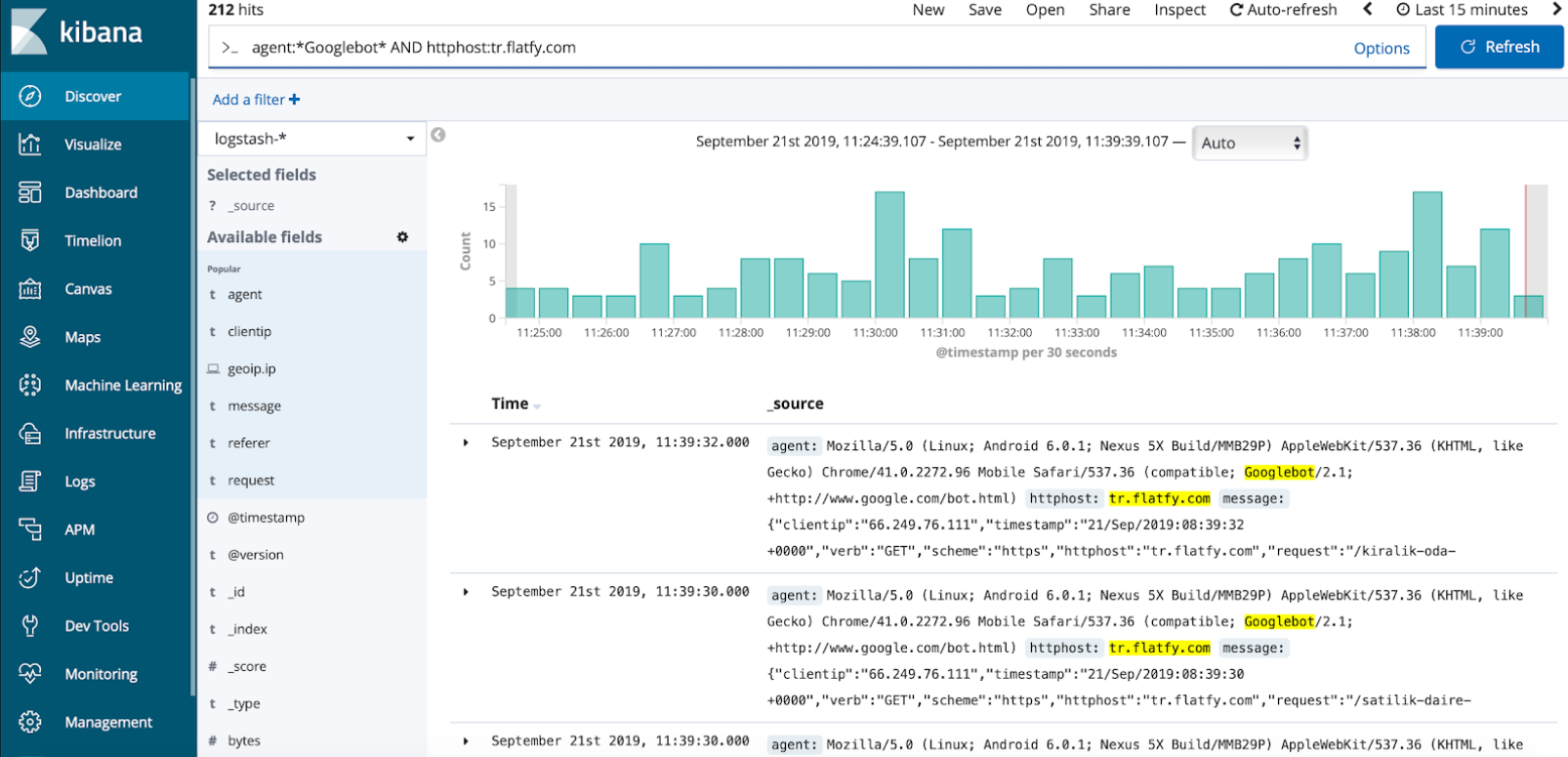
Есть Google поисковик, в который вы через различных операторов делаете запросы, дальше вы можете все это отфильтровать и посмотреть, что запрашивал Google, какие страницы и т.д.
Локализация проблемы
Теперь разберем, как с этим работать. Когда вы не знаете, что искать и с чего начинать, то вам нужно локализовать проблему.
Допустим, вы решили написать сайт: lun.ua. Написали и видите число в 3 миллиона, а вчера было 150 тысяч. Откуда взялось больше 2 миллионов, притом, что вы не создавали новых страниц? Начинаете разбираться и обнаруживаете, что аналитики решили создать "хитрые" гет параметры, с помощью которых будет отслеживаться Аналитика. Это, кстати, реальный кейс трехлетней давности. Поэтому если у вас такая ситуация, то здесь локализировать проблему не нужно.
В случае, когда вам надо локализировать проблему, берем все url и пытаемся придумать сегменты.
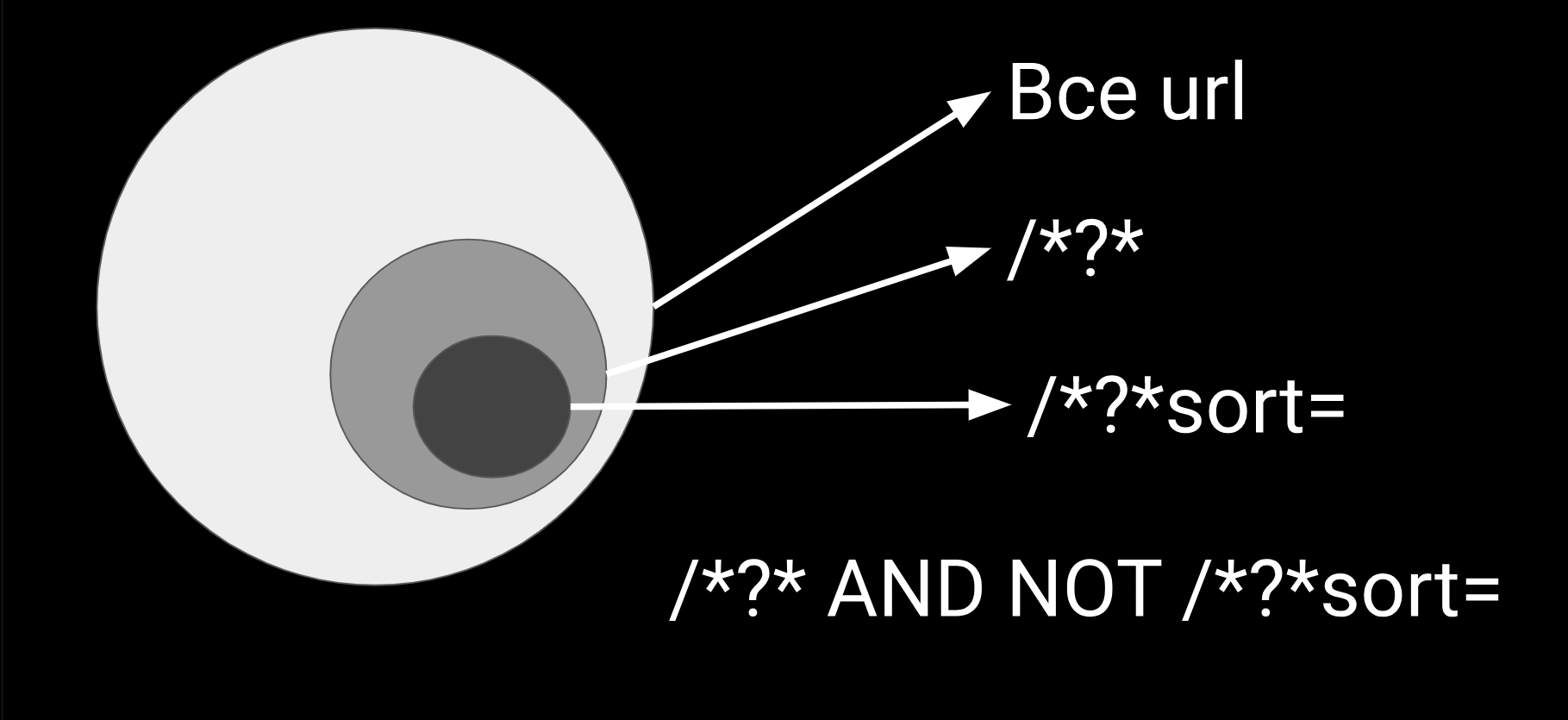
Например, самый частый сегмент, по которому бывают ошибки, это get параметры. Используя JetOctopus, ELK или даже поиск по Excel, можно найти все url, в которых есть get параметры. Get параметры идут через знак "?" с "and". Дальше мы берем один из get параметров и рассматриваем запросы, которые по нему делал googlebot. Разбираемся, как он его использует, куда он ходит и вообще должен ли он его запрашивать.
Из недавних кейсов: клиент написал сложный JavaScript, который googlebot, вроде, не должен прочитать. В итоге googlebot каким-то образом генерирует страницы и постоянно ходит по ним. Начали смотреть логи, действительно есть параметр, назовем его sort, по которому googlebot ходит. Начали разбираться в коде, оказалось там все закрыто так, что даже не понятно, как это сделано.
Проблема оказалась в том, что параметр был настолько популярен, что пользователи стали ставить внешние ссылки. Поэтому как ни закрывай этот гет параметр, как ты с ним ни работай, все равно будут внешние ссылки. Просто он очень полезный.
Ваша задача – посмотреть, на что заходит googlebot, и попытаться разобраться случайно это или нет. Если вы с этим разобрались, то исключаете этот сегмент из дальнейшего анализа и продолжаете копать все глубже, пока не останется ни одного гет параметра.
Дальше вы идете в JS и смотрите, какие JS запрашивает поисковый бот. Как только вы разобрались с этим сегментом, переходите на следующий и так до тех пор, пока не останется сегментов.
Из JS также есть интересный кейс. На сайте на WordPress стоял плагин. Не помню его названия, но идея была в том, что при каждой сессии, при каждом запросе он генерировал свой кэшированный JS и CSS.
В результате Google заходил как новый пользователь, каждый раз получал новый JS и начинал постоянно его запрашивать, хотя это один и тот же файл, который поисковик мог не дергать так часто. Поэтому пытайтесь делить свой сайт, свои урлы и локализировать проблемы.
Парсинг Google выдачи
Если вы локализировали проблему с точки зрения сканирования, вспоминаем, что сканирование это не всегда индексация. Если Google увидел страничку, не значит, что он ее сохранил к себе. Поэтому желательно проверять, есть ли эти странички в Index.
Можно проверять через ту же самую Google Search Console или операторы "сайт" и "inurl". Если через этих операторов вы нашли ошибки, то можете попытаться спарсить какое-то количество примеров этих страниц. Например, через плагин для Google Chrome, который называется Web Scraper. И дальше анализировать эти страницы: почему на них Google попал и забрал их в Index.
Почему сканирование и индексация лишних страниц это плохо? Первое, мы тратим деньги Google. Это, конечно, для кого-то спорный вопрос.
Второй минус, когда мы тратим деньги Google, мы тратим краулинговый бюджет. Google не любит тратить деньги на ненужные страницы. Вспомните, лет десять назад, когда Google начинал историю с Nofollow и прочими тегами.
Зачем они были сделаны? Для того чтобы отсекать некачественную часть интернета и выделять ресурсы на более качественные страницы. Это уже в 2019 году Google перестал отсекать Nofollow, заявив, что все новостники его ставят, поэтому он так может пол интернета отсечь. Но 10 лет назад поисковик использовал Nofollow именно для того чтобы экономить.
Вывод: попытайтесь помочь Google сэкономить и, тогда он будет сканировать, и доставать чаще нужные для вас страницы, которые могут принести не просто трафик, а продажи или выполнение ваших целей (подписчиков и т.д.).
Кейсы потери Crawl бюджета
Интересные кейсы, с которыми я сталкивался в последнее время.
Счетчик просмотров
Представьте стандартный сайт с блогом, на котором есть счетчик, фиксирующий количество прочтения статей. Google решил, что это очень важный контент, и просто "долбил" одни и те же страницы, потому что этот показатель менялся. Он считал, что это основная зона контента, и постоянно эти страницы пересматривал, хотя смысла в этом не было. При этом новые страницы он подтягивал намного хуже, чем старые, на которых типа что-то менялось.
Как мы это нашли? Это было хорошо видно в логах: Google запрашивает страницу плюс JS, который этот счетчик увеличивает. Еще нам повезло, что JS был по отдельному url, а не внутри самой страницы, написанной inline.
Редирект с удаленной страницы на get параметр
Как мы привыкли работать? Если удаляется страница, нужно отдать 404, 410 или сделать 301 редирект на ближайшую по теме страницу. В данном случае был редирект на страницу "данного товара не существует" и эта страница была не 404. Google начал эти страницы в большом количестве сканировать и индексировать.
Грубо говоря, был iPhone красный. Он удаляется и к нему добавляется параметр "iphone красный?deleted=1". Никогда бы не додумался, что так можно сделать, но с помощью Search Console и логов, такое удалось увидеть.
Пиксель своей аналитики
Если у вас большой сайт, то вы уже не влазите в Google Analytics, у вас постоянно висит красный значок лимитов, ивентов сессии и т.д. Поэтому вам приходится переходить на собственную Аналитику.
Большинство делают по примеру и подобию Facebook Pixel: добавляют однопиксельную, прозрачную картинку на страницу и каждый раз, когда идет запрос, в параметрах записывается, с какой страницы была запрошена эта картинка. Суть в том, что если JS-код не закрыть от поисковой системы, то существует большая вероятность того, что Google подумает, что это картинка.
У меня был кейс, когда десятки тысяч запросов краулингового бюджета тратились на этот маленький пиксель. Еще и заходил googlebot Image, то есть он действительно считал, что данная картинка может влиять на контент.
Про массовую генерацию я уже немного говорил выше: если вы переделываете на сайте все картинки, например, перерезаете их под новый дизайн, то готовьтесь к тому, что Google может очень долго качать эти картинки, и вы потеряете на какое-то время картиночный трафик.
Robot.txt и Regex
Ошибки в robots.txt. Большая проблема сеошников в том, что они пытаются копать глубоко, при этом забывая об основных моментах и, из-за этого делают ошибки.
Напоминаю, Disallow начинается с url. Если расшифровать запись Disallow: ^/login, то это будет сначала url, логин и потом все что угодно. Если вы живете в Украине и добавляете украинскую версию из-за "мовного" закона, то не забывайте ставить "*" перед слэшом или добавить еще одну запись Disallow. Иначе вы для себя страницу с русской версией закроите, а с украинской – нет.
Проверяйте всегда url, которые вы хотите закрыть через robots.txt. Он не всегда может дать правильную подсказку, но все-таки гуглоиды стараются свои инструменты для чекинга делать адекватными.
Также не забывайте проверять Справку. Например, когда я веду свои курсы, мне буквально накануне приходится проверять все Справки. Потому что не раз сталкивался с тем, что вечером просматриваю ее – все нормально, а уже на утро нахожу там какую-то измененную фразу или исключение.
Или, например, проблема с Crawl: Google жестко дергал сайт, поставили Crawl-delay, но ничего не поменялось. Как оказалось Мюллер еще в 2017 году заявил, что они больше не поддерживают Crawl-delay. У Google появился собственный инструмент, в котором можно изменить скорость краулинга. Таких нюансов достаточно много, поэтому перепроверяйте Справку, чтобы не пропустить важные изменения.
Еще один небольшой кейс, который мне показал Геннадий Севашов. Можно страницы Справки качать в GitHub, в котором у вас будут показываться новые страницы как коммиты. Так вы сможете смотреть и сравнивать, что изменилось за последнее время.
Скорость сканирования
Два слова о скорости сканирования. Недавно я писал кейс: если у вас сайт жестко "пролежал", Google краулинговый бюджет снизил до нуля, так как он понимает, что если сайт лежит, то лучше его не напрягать. В этом случае можете воспользоваться Crawl Reit и подергать ползунок на высокий уровень. Этим вы дадите понять Google, что все хорошо и вас нужно подкачать.
Google Bot: особенности
Особенности googlebot, которые стоит отметить. Первое, googlebot зачастую не сохраняет cache и cookies. Это вы можете проверить сами.
Единственное, что проверяйте всегда передачу. Когда-то читал посты о том, что googlebot читает cookie. Здесь есть один момент: он их принимает или сохраняет? Проблема в сохранении: googlebot не сохраняет между сессиями cache и cookies. Таким образом, он может получить тот контент, который другой пользователь не получит.
Проще говоря, вы сделали корзину с товарами и поделились этой ссылкой с другом. Google Bot зашел по этой ссылке, случайным образом понажимал на какие-то товары, собрал себе cookies с любимыми товарами и индексировал эту страницу. Это, конечно, не дело, поэтому cache и cookies между сессиями не сохраняются.
Кейсы cookie\ip
В этом есть множество нюансов, например, как работать с теми же языковыми версиями. Частая ошибка: допустим, пользователь приходит из США, значит, мы решаем перенаправить его на англоязычную версию.
Во-первых, вы не всегда знаете с какого ip придет Google. По моему опыту, он чаще всего ходит с айпишников США. В Google Справке говорится, что он может прийти с любого ip, поэтому куда вы перенаправите Google не понятно.
Часто сталкиваюсь с тем, что ребята выкатили новую языковую версию, но кроме английского варианта у них ничего не ранжируется. В этом случае просто проверьте свой пэнкл (вдруг вы редиректите по ip и GoogleBot просто не понимает, куда ему идти) или смотрите это по логам сервера.
Основное правило, которое нужно взять себе на заметку, это вести себя с GoogleBot как с новым пользователем, с которым вы никогда не встречались. Например, если он запрашивает русскоязычную страницу, значит, показываем ему именно эту версию. Если он поменял язык, проставили ему cookie и начинаем его редеректить. Поскольку Google зайдет по другой сессии без cookie, то он не будет редиректиться и получать ненужные версии.
Скорость загрузки, рендеринг
Особенности рендеринга
Я хочу напомнить особенности работы гугловского WRS (Web Rendering Service). В Справке напрямую написано о том, что у Google есть определенный модуль, который пытается распознать, может ли данный код добавить что-то в контент либо это просто аналитика и т.п. Логично, что свои домены и JS он не дергает.
Но если у вас есть какие-то свои особенности (например, как было сказано выше про добавление единичек в просмотры, внутреннюю аналитику), то Google может не разобраться, надо ли выполнять эти JS-коды или нет. Поэтому среди сео-специалистов, которые работают с React, Angular или Vue.js, есть негласное правило об использовании Server-side rendering (SSR).
Single Page Application
Напомню, что при SSR страница рендерится веб-сервером как часть цикла запрос-ответ. В данном случае у вас на Client приходит не просто какой-то JS, который нужно выполнить, а конкретная html с готовой дом-структурой, которую можно просмотреть и прочитать без JS. Дальше поверх этой дом-структуры при нажатии на кнопки, начинают добавляться новые данные.
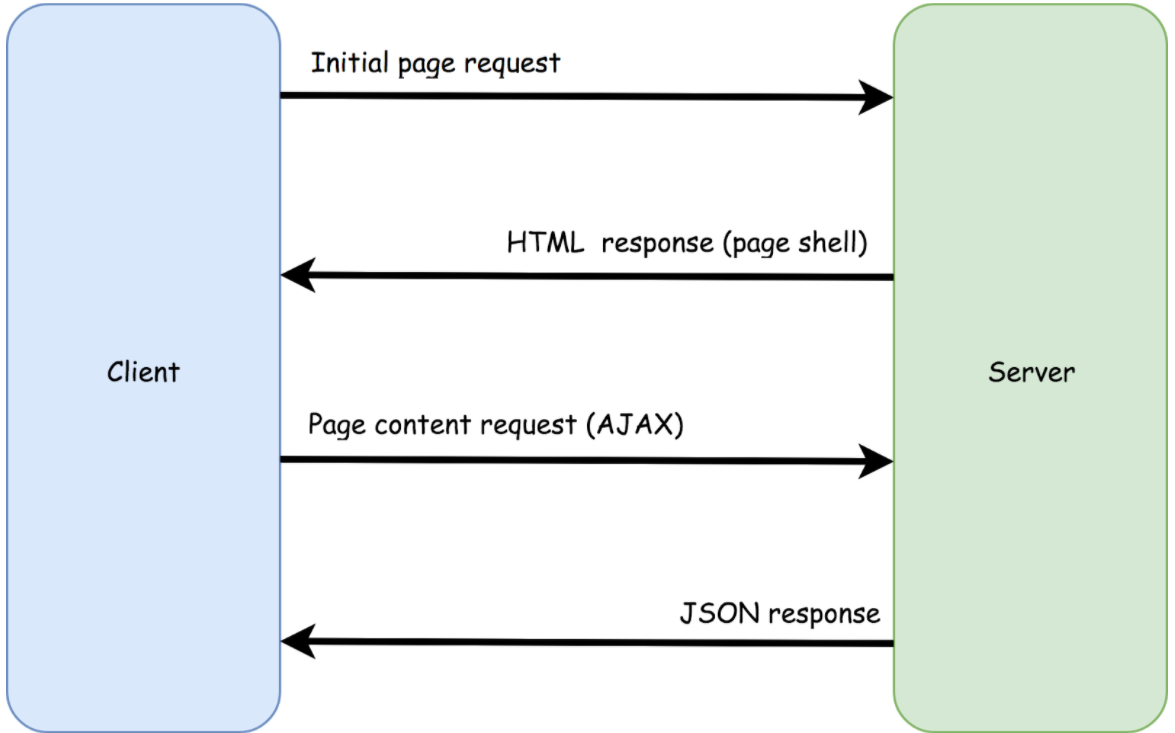
В принципе вы можете посмотреть на любой manual о том, как работает Single Page Application. Здесь все это будет. В SPA у вас есть запрос к серверу, ответ с Page Shell (с каким-то html, домом) и дальше в зависимости от того, что вы запрашиваете, вам будут приходить JSON-ответы с контентом, который нужно поменять в этой дом-структуре.
Когда сайт без SSR
Можно ли работать без SSR? Да, можно. Можно работать на "голом" React без SSR. Картина будет примерно, такая как на скриншоте.
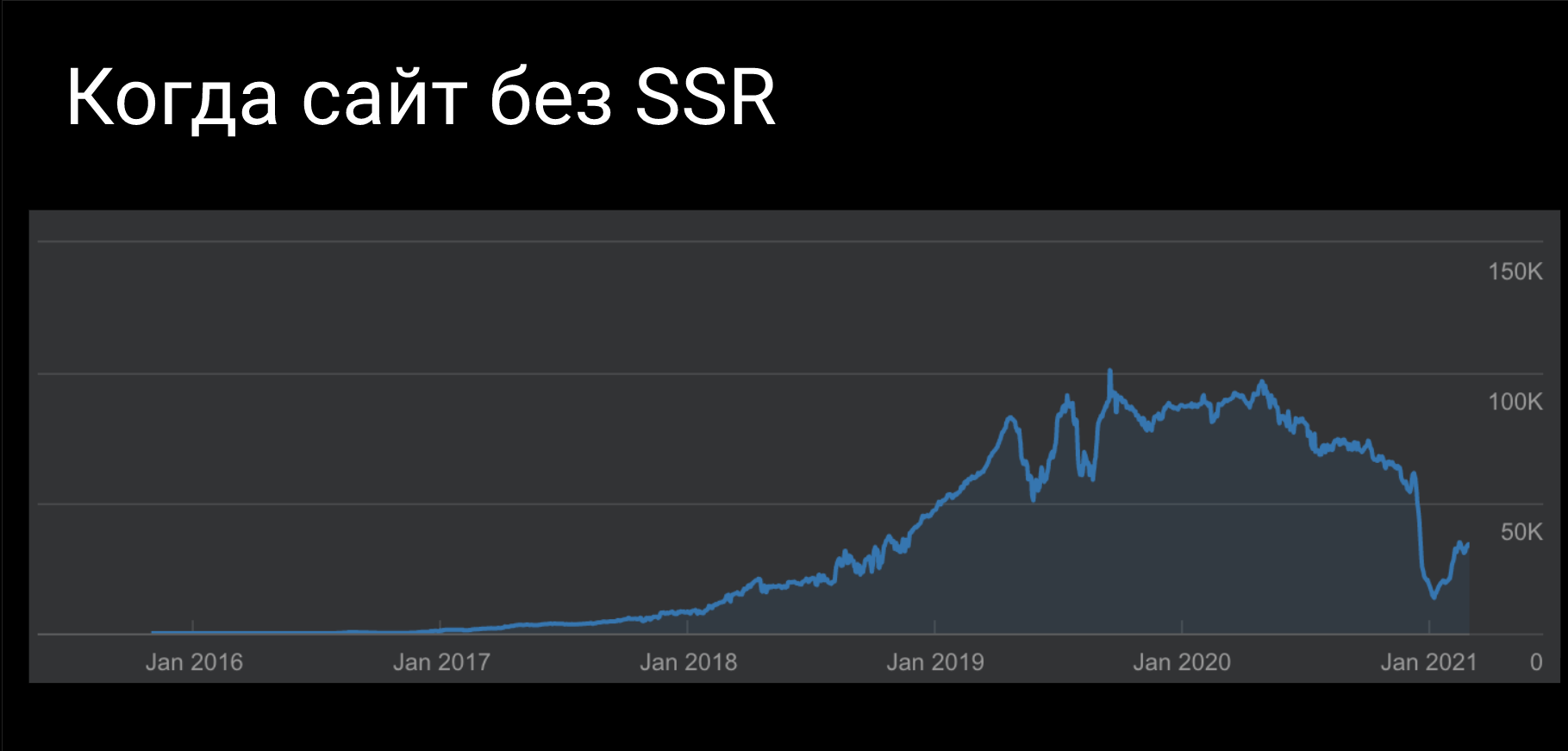
Здесь понятно, когда сайт перешел с WordPress на React. Как вы видите, все же он упал не до нуля, то есть Google смог прочитать контент и что-то из него извлечь. Единственное, что не совсем понятно, видел ли он весь контент. В данной ситуации проблема была не столько в SSR, сколько в том, что не генерировались Title и другие метатеги. Они везде были одинаковые. Поэтому причина может быть в этом, но, в принципе, сайт может жить и без SSR.
Как это все можно проверять, не имея специальных разработческих знаний? Как минимум отключите JS в своем браузере и посмотрите, какой контент получит Googlebot (или любой другой бот) без JS.
Другой вариант, зайти в cache и посмотреть текстовую версию либо исходный код. Почему я никогда не советую смотреть полную версию? Потому что Google пытается отрендерить страницу через ваш браузер.
Например, если вы зайдете на любую страничку Flat File, то, скорее всего, увидите ошибку. Почему? Потому что страница проиндексировалась последний раз вчера-позавчера, а у нас был новый релиз и JS уже называется по-другому. Поэтому у браузера нет доступа к этому JS и он не может выполниться. Но это не значит, что Google увидел наш сайт как-то криво.
Отображение через якоря
Поговорим о лайфхаках по проверке вашего отображения. Не все знают, что по странице или сайту можно раскидать анкорные ссылки (ссылки, которые отправляют к конкретному айдишнику html элемента) и, таким образом смотреть скриншоты в Google Search Console.
Например, если вы вводите просто "domain.com/page", то видите первый экран вашей страницы. Если вы хотите посмотреть на отрендеринную среднюю часть, вставляете анкор посредине и смотрите ее через этот анкор.
Speed Update
Буквально по три слова о скорости и разметке. За последние два-три месяца было достаточно рассказано о скорости, поэтому единственное, на чем стоит здесь остановиться – Web Vitals.
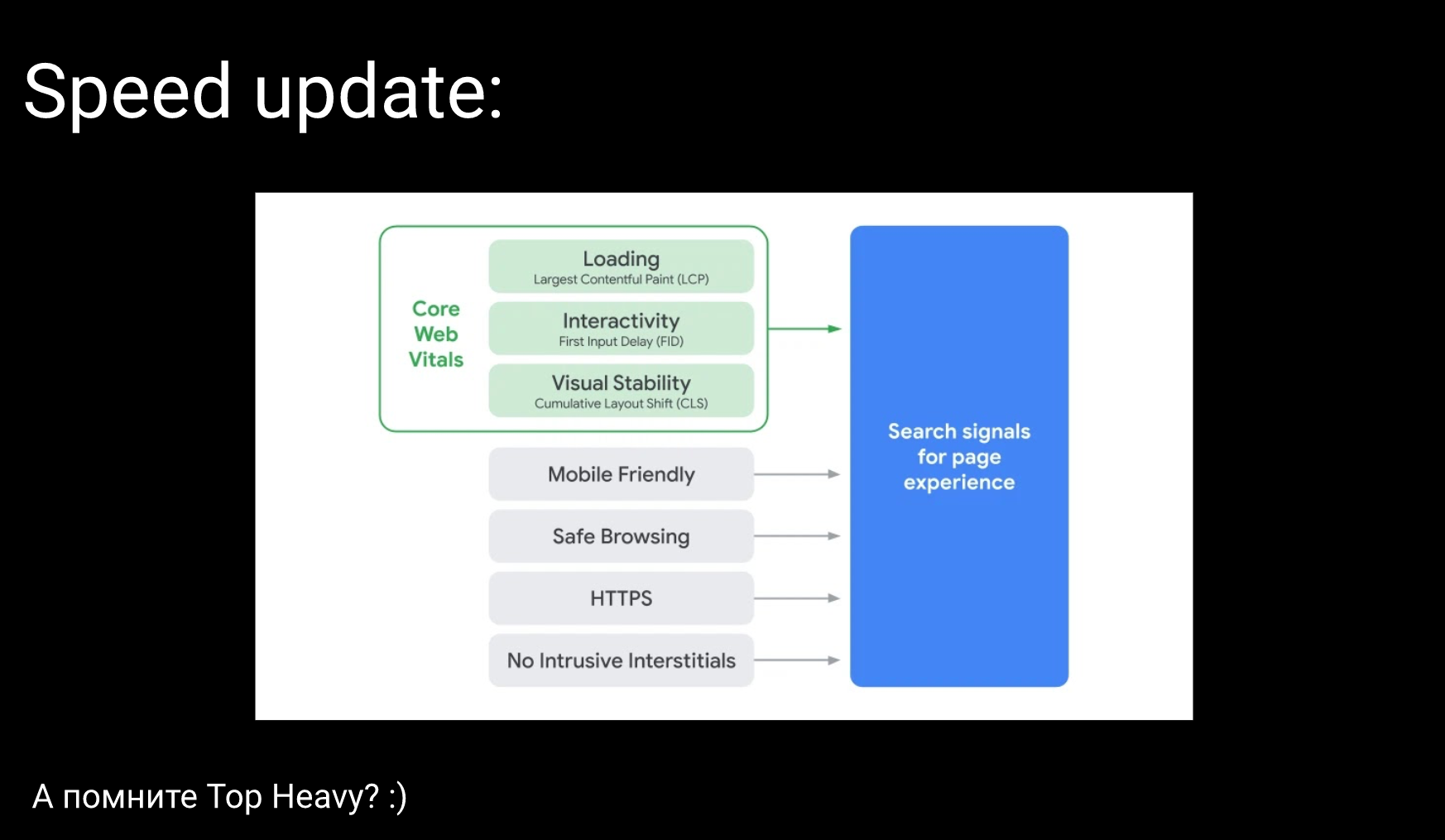
Помните, был такой алгоритм, который назывался Top Heavy. Примерно в 2012-2014 годах повально начали банить сайты за крупную рекламу сверху или большие баннеры, которые не давали на мобильных телефонах сразу же увидеть контент. Почему-то Web Vitals мне напоминают именно те алгоритмы, которые были еще шесть лет назад, и наконец-то и Google дошел до того, чтобы не просто анализировать искусственные данные, а еще и живые пользовательские.
В трех словах о том, как мы собственно готовимся и работаем с Web Vitals. Что мы сделали первым делом. Мы определили шаблонные страницы, которые у нас отличаются по наполнению.
Условно говоря, если у вас интернет-магазин, есть главная страница, страница категории товаров и страница конкретного товара. Здесь логично, что страница категории товаров из-за множества элементов является самой нагруженной.
Дальше под все эти страницы определяются KPI, которые можно замерить. Из самых банальных примеров: HTML size, CSS size, Time to First Byte (TTFB), Cumulative Layout Shift (CLS) и т.д. Зачем вы измеряем HTML size?
Я недавно столкнулся с интересным кейсом. Когда мы использовали разметку JSON, настолько хорошо все разметили, классно сделали ТЗ, что у нас HTML size на одном из проектов увеличился в два раза. С одной стороны, это может быть и не сильно влияет на скорость. Но с другой стороны, в два раза. И это показатель того, что уже нужно использовать не JSON разметку, которая по сути повторяет весь контент, а применять Microdata.
Следующий шаг, замеряем все эти показатели в динамике автоматическими тестами. Например, каждый день либо несколько раз в день прогоняем автотесты, записываем все данные и на графиках накладываем коммиты своих разработчиков. Если мы видим, что HTML size сегодня вырос, видим коммиты и релизы, которые были сегодня, то можно узнать, что на это могло повлиять.
Исходя из нашего опыта, я могу посоветовать вам сайт Sitespeed.io. Это не совсем сервис, это сборник Open Source инструментов, который вы можете достаточно легко через докер развернуть на своем сервере и через этот набор инструментов тестировать большое количество данных (все Web Vitals, разные Trace Road, WaterFall и т.д.). В общем, это классная и удобная вещь.
Здесь нужно помнить, что это синтетические тесты, которые будут сильно отличаться от настоящих пользовательских данных. Но если вы не хотите лезть в разработку либо у вас нет на это ресурсов, то вы можете замерять performance более простым способом. Например, Google Search Console предоставляет данные о Core Web Vitals.
Многие также забывают, что в Google Analytics есть отчет "Sitespeed" и особенно классный отчет "Speeds Suggestion", который показывает вашу оценку по Speed Insite и количество ошибок, которые потенциально можно поправить. Скорее всего, там будут ошибки, о которых вы и так знаете, но здесь все зависит от уровня вашего проекта. Возможно, что вы где-то что-то пропустили.
Разметки
Теперь немного о разметках. Первое, с чем я столкнулся в технической оптимизации. Вы знаете, что Google то хочет, то не хочет переходить с Structured-data/testing-tool на Rich results, поэтому работают пока еще эти два инструмента. И как бы не было смешно, они работают по-разному.
Например, можно чекнуть одну и ту же страницу в Structured-data получить массу ошибок, при этом в Rich results не получить ни одной ошибки. Почему так? По моим наблюдениям, Structured-data/testing-tool пытается работать конкретно по руководствам Google, а они не всегда такие же как руководства Schema.org. Поэтому Structured-data более серьезен. Будьте здесь аккуратны и, пока ситуация не изменится, проверяйте двумя сервисами.
Плюс, когда вы работаете над разметками. Здесь надо сказать, ребята давайте работать над ними как можно больше, потому что в СНГ это не сильно популярная тема и ее продвигает пока один человек – Олеся Коробка. Она ведет достаточно качественный Telegram канал, хотя, скорее всего, делится не всеми инсайтами, которые знает.
Вернемся к разметкам. Помогайте понять Google, какой контент у вас есть на сайте. Особенно, если у вас разные react. Чем сложнее код, тем сложнее Google понять, где у вас что находиться. Вы можете сделать разметки и, этим подсказать, например, это у меня объявление по квартире, здесь есть цена, метраж и подобное. Конечно, это не поможет в визуальных фичах, которые есть у Google, по типу звездочки рейтинга, цены, FAQ и т.д. Но это поможет Google понять, какой контент у вас имеется.
Здесь есть один важный нюанс. Для большинства этих разметок от Google нет никаких руководств, поэтому вам необходимо будет читать гайды Schema.org и желательно опускаться вниз и пытаться разобраться со всеми дополнительными ссылками. Либо на GitHub, в котором годами идут обсуждения того, как правильно сделать либо ссылки на какие-то руководства, например, на разметку Good Relation.
Из недавнего кейса, с которым я столкнулся: ребята долго пытались попасть в одну разметку, в которой использовалась дата и время. Они писали, допустим, 1 марта 2021 года, но как оказалось Google не умеет читать такой формат. И изначально в той разметке, которую они использовали, использовалась Good Relation, в которой нужно передать данные конкретно в таком формате: год, месяц, время.
Поэтому будьте внимательны и передавайте данные, которые в конечном итоге Google сможет прочитать и дополнительно их использовать.
Сессия вопросов и ответов
– Первая мысль, которая мне сразу приходит в голову, есть большая вероятность, что это не Google. Здесь желательно проверить через reverse DNS lookup. Я думаю, что Игорь уже проверил, но на всякий случай, вдруг вас кто-то парсит.
Второй момент, попробуйте через Search Console изменить тот ползунок, который я показывал на одном из слайдов. Зачастую это помогает.
По поводу Too Many Requests, если честно, спорный вопрос, потому что "привет" 500 ошибки и возможны выпады из топа. По мощностям попробуйте повесить какую-то SDN (Software-defined Networking), тот же Cloudflare.
Значит из первых мыслей, проверить reverse DNS, возможно кто-то парсит. Проверить стрелочку в Search Console, куда она смотрит, возможно, в ноль, тогда стоит переделать. И, собственно SDN.
Кстати, по поводу краулинга, есть достаточно интересный кейс. Если Google балансит, то есть он видит, что сайт ложится, то пытается меньше его запрашивать. У нас был кейс с Яндексом, когда мы кнопку сканирования выкрутили на 600 запросов в секунду и, собственно, он столько и делал. Поскольку у нас сервера можно проверять бесконечно (у нас распределенная система), он денег съедал "мама не горюй". Поэтому не играйтесь с этими штуками.
– Самый первый вариант – это проверять через Google Search Console. Вообще у многих есть такая проблема. Смотрите, мы выкатываемся либо с новым компонентом, либо на новом фреймворке, естественно, не понятно как это будет работать.
Поступайте так, как делает компания "LF8" – зарубежное SEO-агентство. Они просто сделали себе тестовый сайт, на котором выкладывают страницы. Допустим, у них есть страницы и определенный новый компонент, который они хотят протестировать. Эту страницу они загоняют руками через Google Search Console в Index, а затем смотрят, сработало – не сработало, есть ли это в коде, есть ли это, как минимум, в кэше.
Здесь есть много споров относительно того, а действительно ли Google в КЭШе показывает тот код, который он использует для индексации. Но это даст хоть какие-то данные: видит ли Google что-то или нет.
– У нас в этом году на Sealevel было принято решение о том, чтобы не говорить фразу "это историческое решение". К сожалению, я не могу по-другому ответить. Это было историческое решение, которое было принято в начале кампании, лет 12 назад.
По текущему опыту я скажу о двух моментах. Первый момент, я бы не сказал, что сам url сильно влияет на ранжирование, поэтому старайтесь просто делать его удобнее как для Google, так и для себя.
Например, как делал бы я сегодня. Я бы разделил url на сегменты: первое – sale или rent, второе – flat, house и т.д. Как минимум, папочная структура поможет поисковику легче сегментировать сайт и понять, где у вас низкочастотные внутренние страницы, а где нет. Это особенно хорошо работает на первом этапе пока еще никакой граф перелинковки Google или другая поисковая система не увидела. Это первый момент, который я сделал.
Второй момент, понятное дело, что с такими урлами работать по аналитике это просто "жесть", поэтому нам приходиться постоянно опрокидывать custom domain, вместо того, чтобы сделать как "белые люди" Regex по url и все.
Следующий момент по опыту работы не с СНГ, а со странами по типу Тайланда и т.п. Google не очень хорошо "шарит" язык, но хорошо "щарит" стринги. Например, если у вас написано на тайском языке "купить квартиру Киев" и точно также выглядит запрос, то Google может дать больше преференций такому урлу, чем урлу с "sale flat". Поэтому за рубежом мы раньше пытались использовать точное вхождение запроса в url, но сейчас я стараюсь от этого отходить и делать удобнее для себя. Это и есть историческое решение.
– Если говорить про ЛУН, то никак. Почему? Потому что у нас постоянно обновляется контент и мы заметили, что Google практически не попадал на 304. То есть он заходит и, у нас уже либо квартира пропала, либо появилась, поэтому он не попадал на 304.
– Все, что перечислено. Могу добавить только X-Robots-Tags. Ищите через заголовки, только если что-то меняете в HTML, не забывайте заголовки тоже менять.
– Здесь нужно смотреть глубже, но есть большая вероятность, что просто напросто в логии не попадают эти ошибки. Может быть, проблема в самом Cloudflare. Насколько я помню, сам Cloudflare по ip отдает логии на платной основе. Если у вас платная, то можете посмотреть там. Но, скорее всего, по какой-то причине это просто не записалось в логах.
– Здесь все зависит от того, вернется ли этот товар или нет. Если этого товара больше никогда не будет существовать, то его нужно удалить и заредиректить на ближайшую страницу. Если этот товар появится, то пишем "скоро будет в наличии" и ничего не трогаем. Зачем ставить себе Noindex и выкидывать эту страницу из индекса, если она потом вернется? Можете в Telegram канале почитать, я там писал по этому поводу пост.
– Первое, в презентации, когда я показывал Kibana, там как раз было видно запрос типа user-agent googlebot и сайт Турция. Наша основа в том, что мы собираем все данные по тем же логам в одну Kibana и в каждой записи мы пишем хост и, таким образом определяем, какой это сайт. Из-за того, что сайты все шаблонные (это один движок), то я могу смотреть либо по конкретной стране, либо по всем суммарно, не фильтруя по стране.
Трафик, как и все отслеживаем через Google Analytics, только скидываем это все в один spreadsheet и в одну Google Data Studio, соединяем все и смотрим. Здесь ничего особенного. Просто все логии скидываем в одну Kibana и уже там смотрим.
По поводу индексации, смотря, что в вопросе имеется в виду. Если про ошибки, например, not seen и то, что в Google Search Console, к сожалению, мы это никак не парсим. Зачастую, я смотрю это вручную. Примерно раз в одну-две недели.
По отслеживанию title, тэгов у меня есть два процесса. Первый процесс полностью автоматизирован через Screaming Frog, у которого есть режим headless. То есть можно без интерфейса с набором конфигураций запускать Screaming Frog на Linux сервере. Это запускается на постоянной основе, раз в несколько дней и там уже видно, есть ошибки или нет. Плюс если происходит большой релиз, я в ручную на компьютере включаю Netpeak Spider и перепроверяю несколько стран.
– Здесь стоит уточнить, что имеется в виду: sitemap.xml или html карта сайта. Если речь о sitemap.xml, то есть несколько важных нюансов. Первое, если ваша страница есть в sitemap.xml, это не значит, что Google будет ее индексировать.
Самый известный кейс был с Stack Overflow. Когда они спросили у Google, почему у них страницы выпадают из Индекса. На это Google им ответил, что у них появляется масса контента, вопросы понижаются во внутренней выдаче, ни в какие категории не попадают. На то, что они были в sitemap, Google было все равно, ему был нужен какой-то граф перелинковки. Поэтому sitemap не всегда помогает, вам все равно будет нужен граф перелинковки.
Второй кейс, на который стоит смотреть, по поводу canonical, noindex и т.д. Здесь нужно читать Справку и думать логически. Когда мне говорят, давайте поставим canonical на первую страницу, я спрашиваю о том, что является ли вторая страница дублем первой или нет. На этом и строиться мой ответ.
Если вам нужна пагинация, чтобы бот видел ваши товары (плохая перелинковка), то поставьте Noindex Follow. Он будет ходить по пагинации, не индексировать ее, но хотя бы видеть товары.
Если вы ставите canonical на первую страницу. Во-первых, странно по логике, потому что вторая и первая – разные страницы. Во-вторых, canonical – это рекомендация, а не правило для Google. Ну, и ваши страницы должны попасть в Индекс.
Например, у нас есть конкурент m2bomber, который заигрался с пагинацией. У них выдача, допустим, "купить квартиру Полтава" пагинация 456. С одной стороны, классно – мы в топе. С другой стороны, возникает вопрос, а конверсия с этой страницы точно хорошая?
– Я бы не искал просто программиста или SEO-специалиста. Я бы искал человека, который работал в вашей нише с похожими сайтами. Можно, конечно, ответить, что просто найдите SEOшника. Вы его найдете, а он работал, например, в агросфере, а вы работаете в медицине. Поэтому он вам вообще ничем не поможет.
Поэтому попытайтесь фрилансера либо SEOшника, который работал именно в похожей теме и с подобными сайтами. Если большой интернет-магазин, то собственно ищите SEOшника, который работал с большими интернет-магазинами.
Зачастую здесь нужен тандем из разработчика и SEO-специалиста, потому что SEOшник не всегда хороший разработчик. Не нужно искать SEO-специалиста и программиста в одном лице, из этого ничего хорошего не получится.
– Это достаточно интересный вопрос, потому что ЛУН – это набор различных бизнес юнитов. Например, на одном из первых слайдов, я показывал есть ЛУН и Flatfy. Только ЛУН – это каталог, по факту, контентный проект. Здесь нужно больше работать с контентом и, это уже работа не SEOшника, а контент-маркетолога.
Flatfy – агрегатор, на котором постоянно внедряются новые технические элементы. Поэтому здесь постоянно работа с техничкой. То есть все зависит от того, с каким проектом из бизнес юнита я работаю. А еще же есть масса секретных проектов, поэтому все зависит от направленности.
– Все зависит от того, где строим. Если мы говорим об Украине, то здесь все достаточно просто. Когда ты известный, то можешь сказать, мы сделали крутую фишку, например, ЛУН Місто – сервис, который отслеживает загрязнение воздуха. То здесь можно писать пресс-релизов сколько угодно. То есть это уже не столько ссылочная, сколько чистый пиар, в который мы говорим "вставьте ссылку".
Если говорить о других странах, то там все немного сложнее, но пытаемся выезжать на тех же темах со статистикой и т.д. Я нахожу человека, которого обучаю, чтобы он аутричил. Обучаем, аутричим, пишем тексты, через него плачу и тому подобное. В принципе, все как у всех. Единственное, что я пытаюсь с каждого аутричера выжать максимум. Если вы решаете какую-то проблему, допустим, с тем же ссылочным, то решайте ее комплексно (бренд, трафик, ссылка).