- Что такое веб-архив
- Как посмотреть веб-архив сайта
- Какие задачи решает веб-архив
- Как использовать Web Archive в линкбилдинге?
- Как добавить текущую версию сайта в веб-архив
- Как запретить добавление сайта в веб-архив
- Как восстановить сайт из веб-архива?
- Как найти уникальный контент с помощью веб-архива?
- Какие есть аналоги Web Archive
- Неочевидные способы использования веб-архива
При продвижении сайтов SEO-специалисты и веб-мастеры используют разные инструменты, которые позволяют автоматизировать стандартные задачи.
Недавно мы делали большую подборку бесплатных SEO сервисов, советуем почитать этот материал.
У большинства из них есть аналоги, но существуют сервисы, которые нечем заменить. К таким относится Wayback Machine.
В новой статье расскажем, как пользоваться веб-архивом для просмотра истории сайта и поделимся нестандартными вариантами применения знакомого многим инструмента.
Что такое веб-архив
Веб-архив (Web Archive, web.archive.org) — библиотека цифровых снимков веб-страниц. Сервис создавался для того, чтобы сохранить живые копии сайтов и у пользователей была возможность посмотреть динамику развития проекта. Ссылка на сервис: web.archive.org
Wayback Machine буквально переводится как «машина времени». Сервис действительно позволяет переместиться обратно в прошлое и посмотреть, как выглядели любимые сайты 10-15 лет назад.
В 2021 году проект отметил 25 лет с момента создания. На его серверах хранится 615 млрд страниц, часть из которых нельзя найти в поисковых системах. Многие ресурсы уже перестали существовать, но продолжают жить на «полках» веб-архива.
Интернет постоянно меняется, каждый день появляется огромное количество новых страниц и со временем часть из них перестают открываться. Web Archive старается сохранить копию каждой важной страницы сайта, чтобы любой желающий мог посмотреть, как она выглядела, когда сайт ещё работал.
SEO-специалисты и веб-мастеры используют веб-архив сайтов в своих целях. Они поняли, что Wayback Machine — практически единственный источник данных о динамике развития сайта. С его помощью можно узнать, сколько примерно хозяев было у домена и какой контент размещали на ресурсе за всё время его существования.
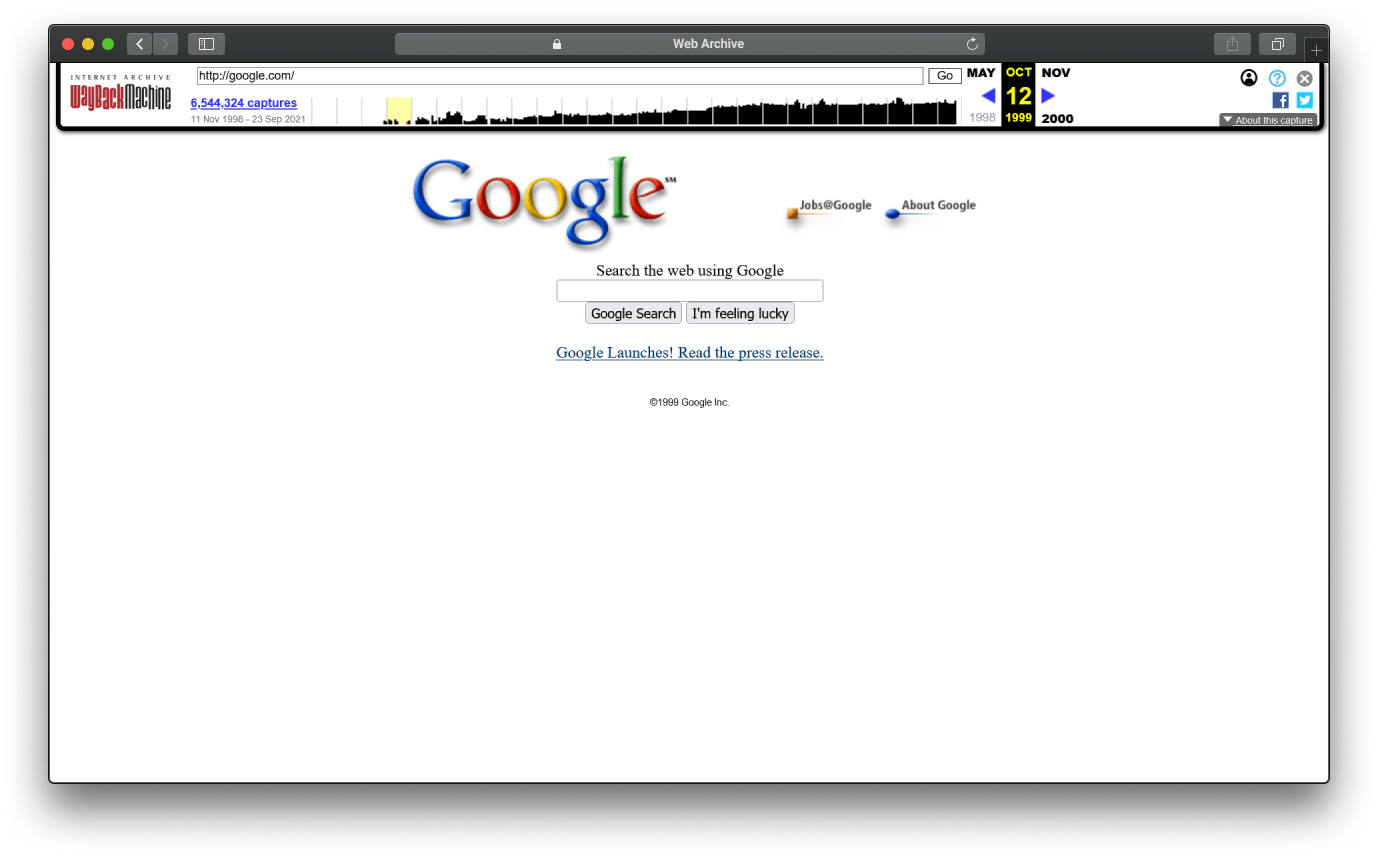
Как посмотреть веб-архив сайта
- Перейдите на главную страницу веб-архива web.archive.org
- Введите домен для проверки в строку поиска
![Как посмотреть веб-архив сайта]()
- Посмотрите архив сайта за любой доступный день
![Как посмотреть веб-архив сайта, календарь по дням в вебархиве]()

Какие задачи решает веб-архив
Веб-архив полезен не только тем, кто продвигает сайты и хочет узнать, не принесёт ли потенциальный донор вред акцептору, если разместить несколько ссылок. Некоторые пользователи занимаются исследованием контента и находят в Wayback Machine информацию, которой больше нигде нет.
Самый очевидный сценарий использования сервиса для SEO-специалистов — просмотр исторических данных сайта. Но стоит сразу отметить, что несмотря на огромный объем страниц, некоторые ресурсы недоступны в веб-архиве.
С помощью Web Archive можно:
- посмотреть историю сайта. И убедиться, что на нём не было запрещённого контента, который может повлиять на судьбу ресурсов, связанных с ним ссылками. Можно узнать, как сайт выглядел раньше;
- посмотреть неработающий сайт. Можно посмотреть неработающий или удаленный сайт;
- восстановить потерянные данные. К примеру, если веб-мастер забыл продлить домен и не сохранил бэкап, веб-архив является практически единственным источником данных;
- следить за конкурентами. Исторические данные покажут, как меняется title, description, контент страницы и редиректы. Отличный способ анализировать сайты конкурентов.;
- проверить сайт перед покупкой. Сейчас на нём может быть «белый» контент, а в истории обнаружится «чёрный» период;
- проверить качество дропа. Если веб-мастер покупает брошенный домен, история влияет на целесообразность покупки;
- обнаружить ссылочные связи. Можно смотреть, на какие ресурсы в разное время ссылались конкуренты;
- проследить цепочку редиректов. Веб-архив сохраняет не только снимки страниц, но и показывает перенаправления;
- увидеть содержимое robots.txt. Чтобы узнать, какие страницы были закрыты от роботов ранее. Например, вы продвигаете сайт и хотите знать, каким раньше был файл роботс;
- проследить изменение структуры сайта. Чтобы понять, насколько быстро увеличивалось количество страниц.
Полезная ссылка по теме: Руководство по настройке robots.txt.
Архив веб-страниц — must have инструмент для всех, кто занимается продвижением ресурсов, зарабатывает на контентных проектах или ведёт клиентские сайты. Его нечем заменить, потому что данные собираются 25 лет. Ни один аналог не может похвастаться таким объемом информации.
Ещё одна важная задача, с которой справляется только Wayback Machine — восстановление утраченного контента. Например, если владелец потерял доступ на хостинг и свежих резервных копий у него не осталось, веб-архив является практически единственным источником данных.
Есть сервисы, которые могут восстановить структуру страниц из Web Archive в автоматическом режиме. Конечно, если в сервисе сохранились все важные файлы. Может показаться, что веб-архив работает идеально и качество восстановления данных не будут отличаться от реального бэкапа, но это не так.
Проблемы веб-архива:
- Сохранение только важных страниц. Роботы сервиса парсят контент сайтов и выбирают страницы, которые соответствуют требованиям алгоритмов. Поэтому при восстановлении контента из веб-архива покрытие может составлять всего 50% от общего количества адресов
- Отсутствие актуальной версии. Обычный сайт не особо интересен алгоритмам Wayback Machine. Поэтому в архиве могут храниться версии страниц 3-5 летней давности
- Некорректные URL. По наблюдениям SEO-специалистов, веб-архив может менять исходные адреса на новые. А если контент будет восстановлен по новому адресу, нет гарантий, что прежний трафик вернётся на прежний уровень
Поэтому восстановление контента страниц из цифровых снимков — сложная задача. Особенно если учесть, что на выходе будёт голый HTML, а CSS и JS-скрипты могут не сохраниться. Тогда придётся создавать сайт заново и пригодится только текст и медиаконтент.
Для SEO-исследователей Web Archive — кладезь полезных данных, но по части восстановления контента к сервису есть много претензий. Но все они не имеют смысла, потому что разработчики цифровой библиотеки создавали её совсем для других задач.
Как использовать Web Archive в линкбилдинге?
Если веб-мастер хочет продвигать сайт с помощью ссылок и собирается закрыть задачу с помощью Collaborator, веб-архив поможет убедиться в надёжности донора.
Ранее мы писали о том, как оценить донора для покупки ссылок в Коллабораторе, на какие параметры смотреть, советуем почитать этот материал.
А сейчас разберемся, как с помощью Web Archive можно посмотреть историю развития проекта и получить подтверждение «чистоты».
Какие данные можно получить для линкбилдинга:
- возраст домена;
- изменение тематики;
- количество владельцев по косвенным признакам;
- история структуры сайта;
- история мета-тегов;
- качество контента;
- ссылочные связи.
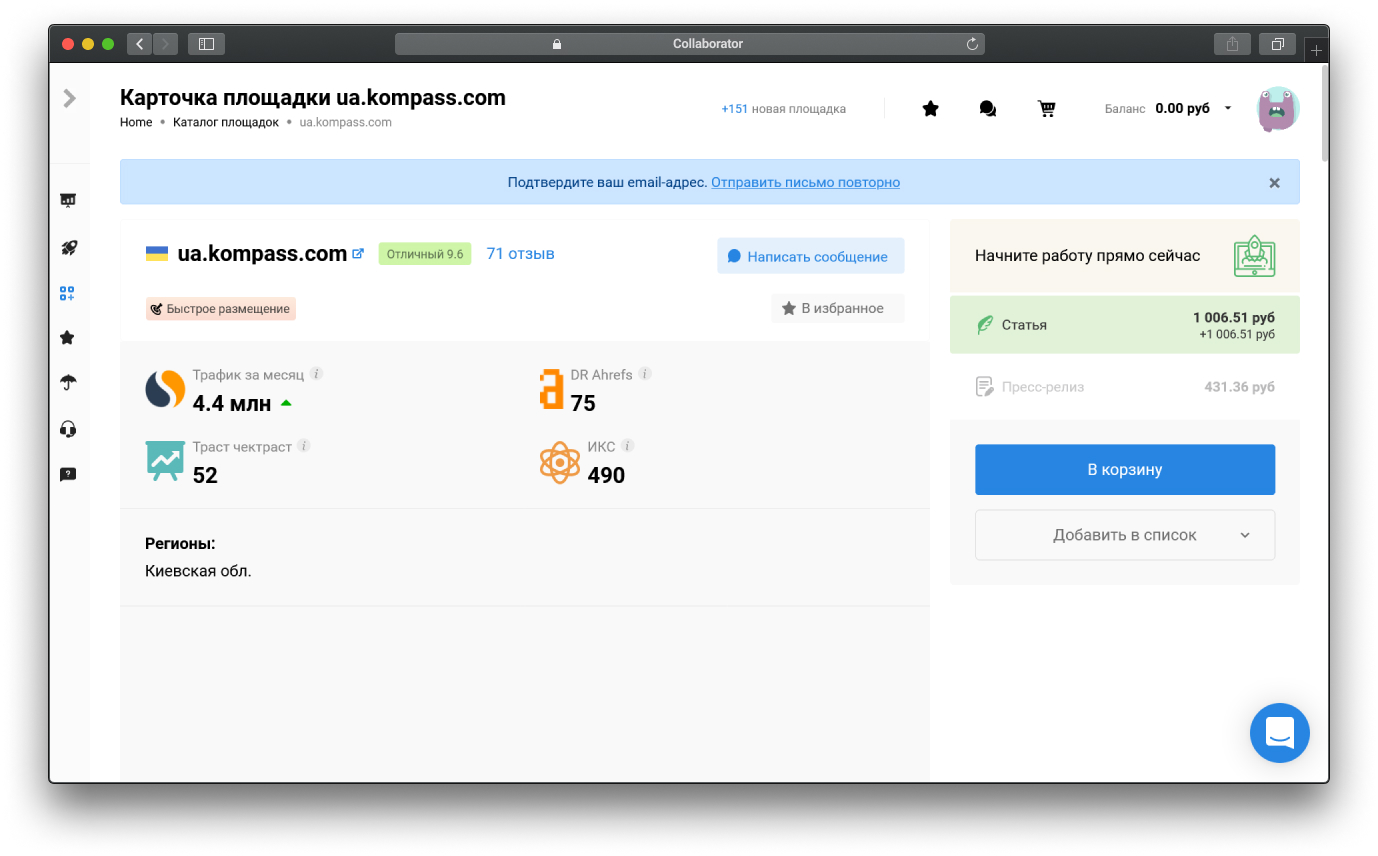
Пример, как использовать Web Archive для построения ссылок
- Выберите домены, которые удовлетворяют вашим требованиям, в Collaborator
![как оценить параметры домена-донора]()
- Откройте главную страницу веб-архива
- Введите адрес конкретной страницы или главной
- Посмотрите исторические данные
![исторические данные по сайту в веб архиве]()
- Отправьте заявку на сотрудничество
![заказ ссылки на сайте после проверки в веб-архиве]()
Ссылочные параметры домена могут быть очень крутыми, но если история у него не совсем чистая, размещаться на таком сайте опасно. Это может негативно повлиять на продвижение ресурса в поисковых системах.
Как добавить текущую версию сайта в веб-архив
Веб-мастера интересуются не только тем, как посмотреть веб-архив, а и способами добавления актуальной версии страницы. Проблема в том, что роботы сервиса обходят сайты по своему графику и их сложно привлечь в отличие от спайдеров поисковых систем.
Точных данных о работе алгоритмов Web Archive нет, но можно предположить, что на интенсивность обхода влияют несколько факторов:
- возраст сайта;
- интенсивность обновления;
- авторитет проекта;
- количество трафика.
Роботы веб-архива регулярно посещают площадки с большой аудиторией и миллионами страниц в индексе поисковых систем. По ним практически всегда есть свежие данные, а вот молодые сайты с минимальным трафиком могут попасть в базу сервиса через полгода или год после запуска.
Заниматься конкретно привлечением роботов Web Archive нет смысла, потому что гарантий успешного выполнения задачи нет. Но есть рабочий способ сохранения цифрового снимка страницы.
Разработчики сервиса понимали, что обход всего интернета — очень трудоёмкая задача, поэтому добавили инструмент, который позволяет отправлять сигнал на обход страницы.
Вот как это работает:
- Откройте главную страницу сервиса
- Введите в поисковую строку адрес, которого нет в базе
- Нажмите кнопку «Save this URL in the Wayback Machine»
![Как добавить текущую версию сайта в веб-архив]()
- Нажмите «Save Page» на следующем экране
![Добавление сайта в веб-архив]()
- Дождитесь обработки данных
![Сохранение текущей версии сайта в веб-архиве]()
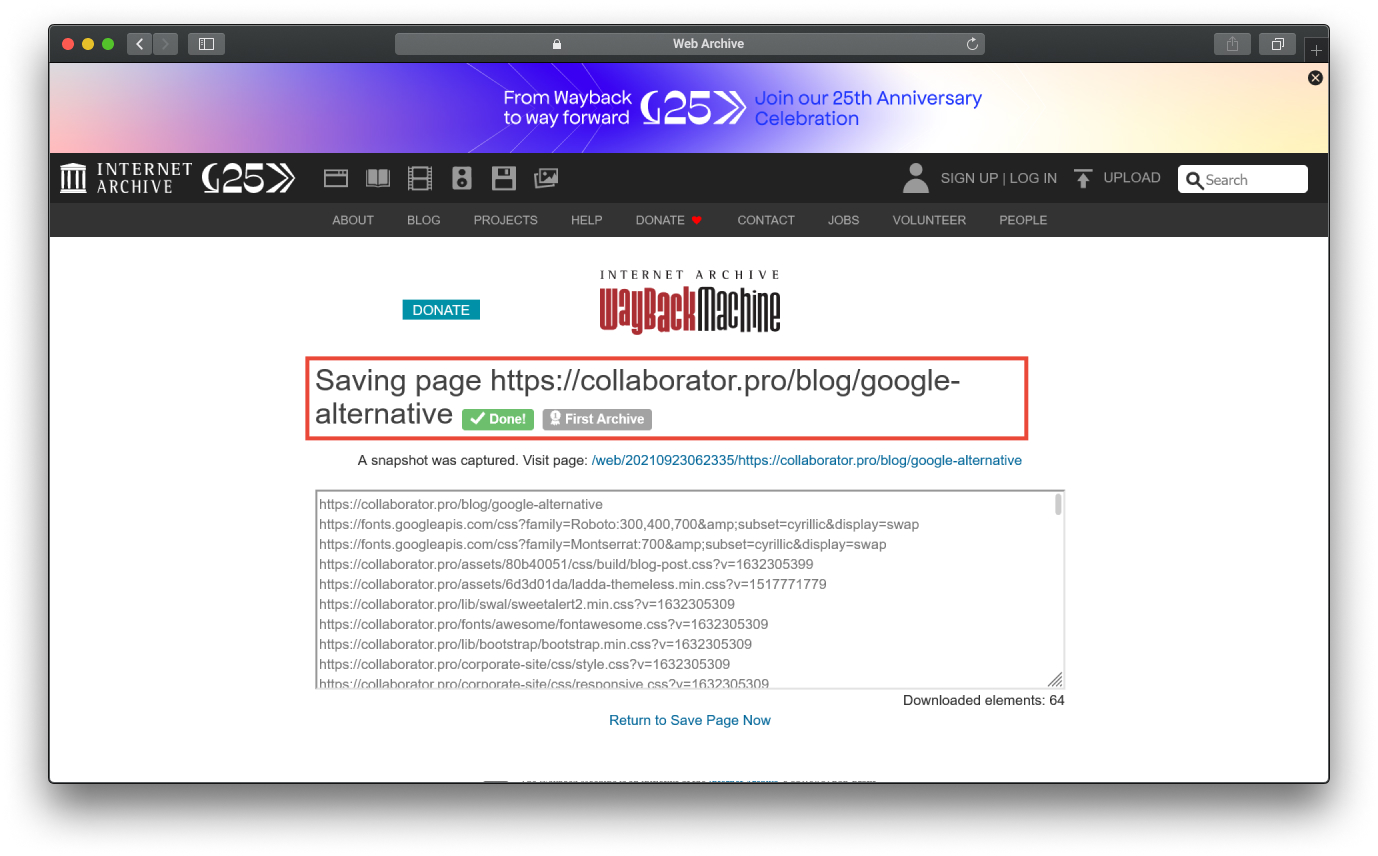
Добавить таким образом несколько страниц не сложно, но если на сайте регулярно появляются десятки новых адресов, без автоматизации задачи не обойтись. Можно создать скрипт, который будет автоматически добавлять страницы в веб-архив, но это не всегда целесообразно.
Как запретить добавление сайта в веб-архив
Если бережно сохранять резервные копии проекта, не размещаться на сомнительных хостингах и вовремя продлевать домены, добавлять страницы в Wayback Machine нет необходимости.
Тем более что сервис не даёт никаких гарантий на полное восстановление контента. Роботы могут легко пропустить важные файлы в процессе парсинга. И тогда в цифровом снимке не будет никакой пользы.
Самый простой способ запретить добавление страниц в базу сервиса — специальная директива в robots.txt. Выглядит она следующем образом:
User-agent: ia_archiver Disallow: / User-agent: ia_archiver-web.archive.org Disallow: / |
Краулеры Wayback Machine учитывают правила технического файла и после обнаружения запрета, перестанут добавлять страницы в базу. Хотя 100% гарантии никто не даёт.
В качестве альтернативы можно добавить правило в .htaccess и полностью запретить доступ роботам с определёнными юзерагентами. Этот способ более надёжный, потому что спайдеры не смогут попасть на сайт.
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} ^.*(ia_archiver|ia_archiver-web.archive.org).*$ [NC]
RewriteRule .* - [F,L]
|
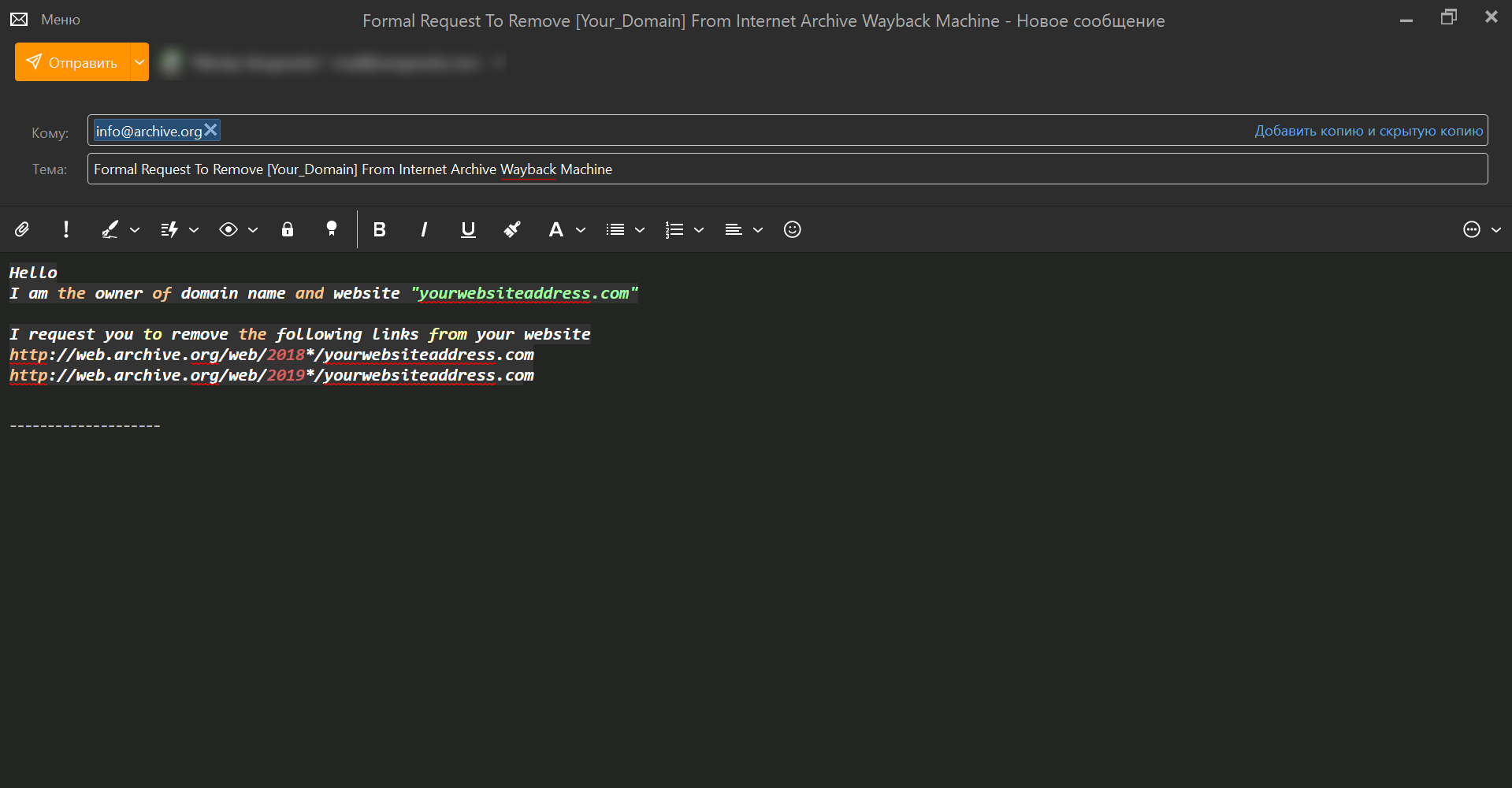
Опыт веб-мастеров показывает, что такие действия приводят не только к остановке обхода страниц, но и полному удалению сайта из базы Web Archive. Если контент всё равно продолжает отображаться, можно написать письмо на почту [email protected].
Hello I am the owner of domain name and website "yourwebsiteaddress.com" I request you to remove the following links from your website https://web.archive.org/web/2018*/yourwebsiteaddress.com https://web.archive.org/web/2019*/yourwebsiteaddress.com |
В этом примере мы просим удалить конкретные страницы, но можно отправить запрос на весь домен. Затем останется следить за наличием сайта в Wayback Machine. Не забудьте добавить запрет в robots.txt, потому что это показывает модераторам сервиса, что владелец сайта действительно хочет избавиться от цифровых снимков страниц.
Для надёжности лучше отправить письмо с почтового ящика своего домена. Тогда необходимость в дополнительных подтверждениях отпадёт. По наблюдениям веб-мастеров, на обработку запроса уходит в среднем 2 недели.
Как восстановить сайт из веб-архива?
Лучше не допускать ситуаций, когда история сайта из веб-архива становится единственным источником данных. Всегда храните бэкапы, чтобы можно было восстановить контент без парсинга Web Archive и сторонних сервисов.
Если забыли продлить домен и вспомнили о сайте через несколько месяцев, когда аккаунт на хостинге уже потерян безвозвратно, можно попробовать восстановить сайт с помощью данных из веб-архива. Или же вам нужно восстановить чужой сайт, доступа к которому никогда и не было.
Решить эту задачу помогают специальные сервисы, которые собирают данные из Web Archive и превращают их в готовую HTML-структуру страниц. Их можно разместить на старом домене без CMS или потратить время на «натяжку».
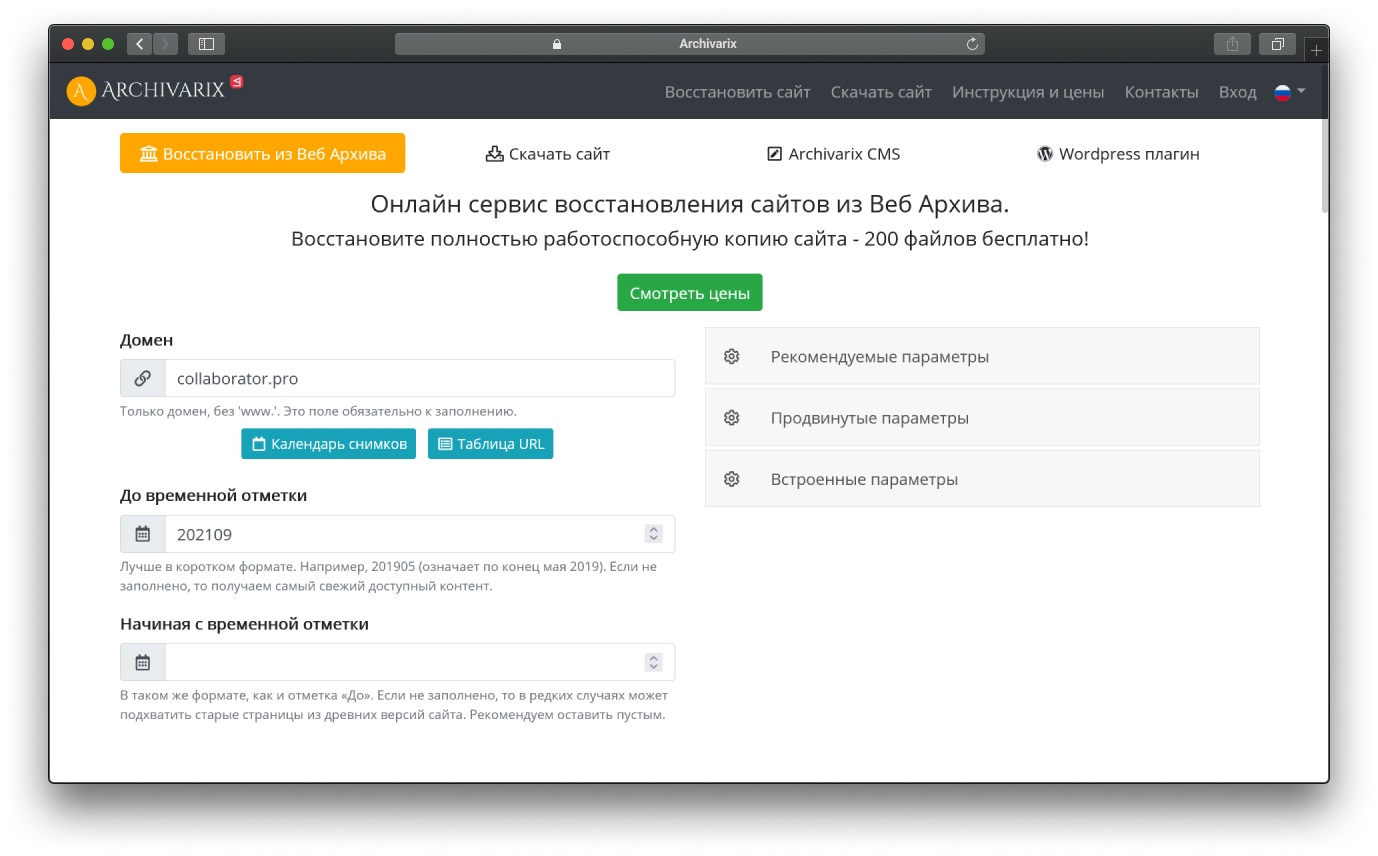
Archivarix
Сервис восстанавливает контент из веб-архива и предоставляет пользователям гибкие настройки. Например, можно:
- запустить оптимизацию медиконтента и HTML-кода;
- сжать скрипты;
- удалить рекламные блоки и скрипты аналитики;
- сделать внутренние ссылки относительными.
Главная фишка Archivarix — извлечение структурированного контента. Благодаря этой функции можно спарсить статьи и получить файл для импорта в Wordpress. Эффективность работы инструмента достаточно высокая и он сильно сокращает количество рутинной работы.
Восстановленные сайты можно поднять на базе Archivarix CMS. Её будет достаточно для базовых задач вроде монетизации дропа посредством продажи ссылок. Но при желании можно «натянуть» сайт на Wordpress.
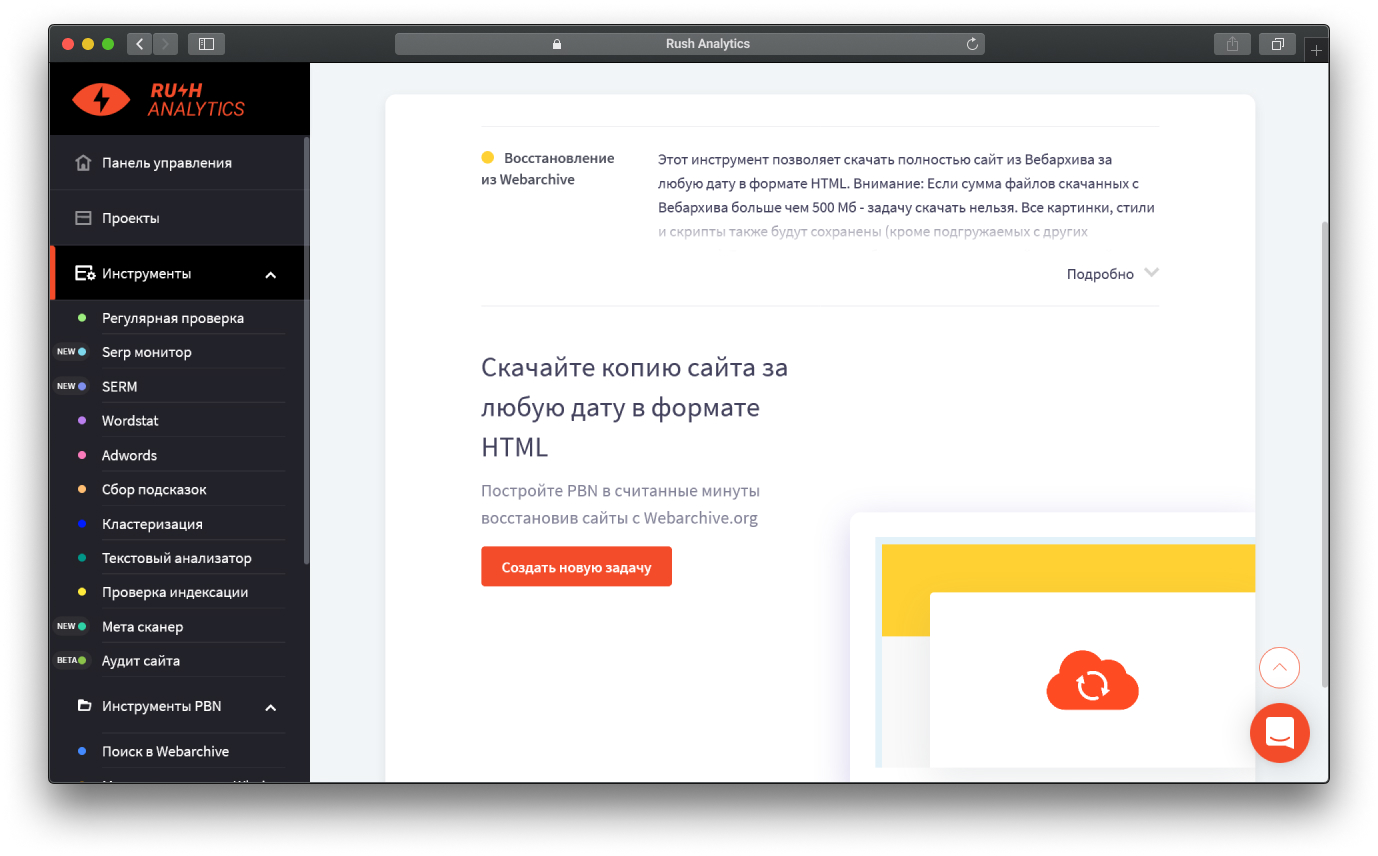
Rush Analytics
В SEO-сервисе доступен инструмент для восстановления сайтов из веб-архива. Выступает в роли конкурента для Archivarix, но выкачивает только HTML-копии страниц. Интеграцией в CMS веб-мастеру придётся заниматься самостоятельно.
Сервис выделяется благодаря пакетной загрузке. Можно скачать хоть 200 сайтов за одну операцию. Эта возможность будет полезна тем, кто хочет массово смотреть веб архив сайтов и восстанавливать контент брошенных доменов и использовать их для продвижения основного проекта или продавать.
Попробовать Rush Analytics →
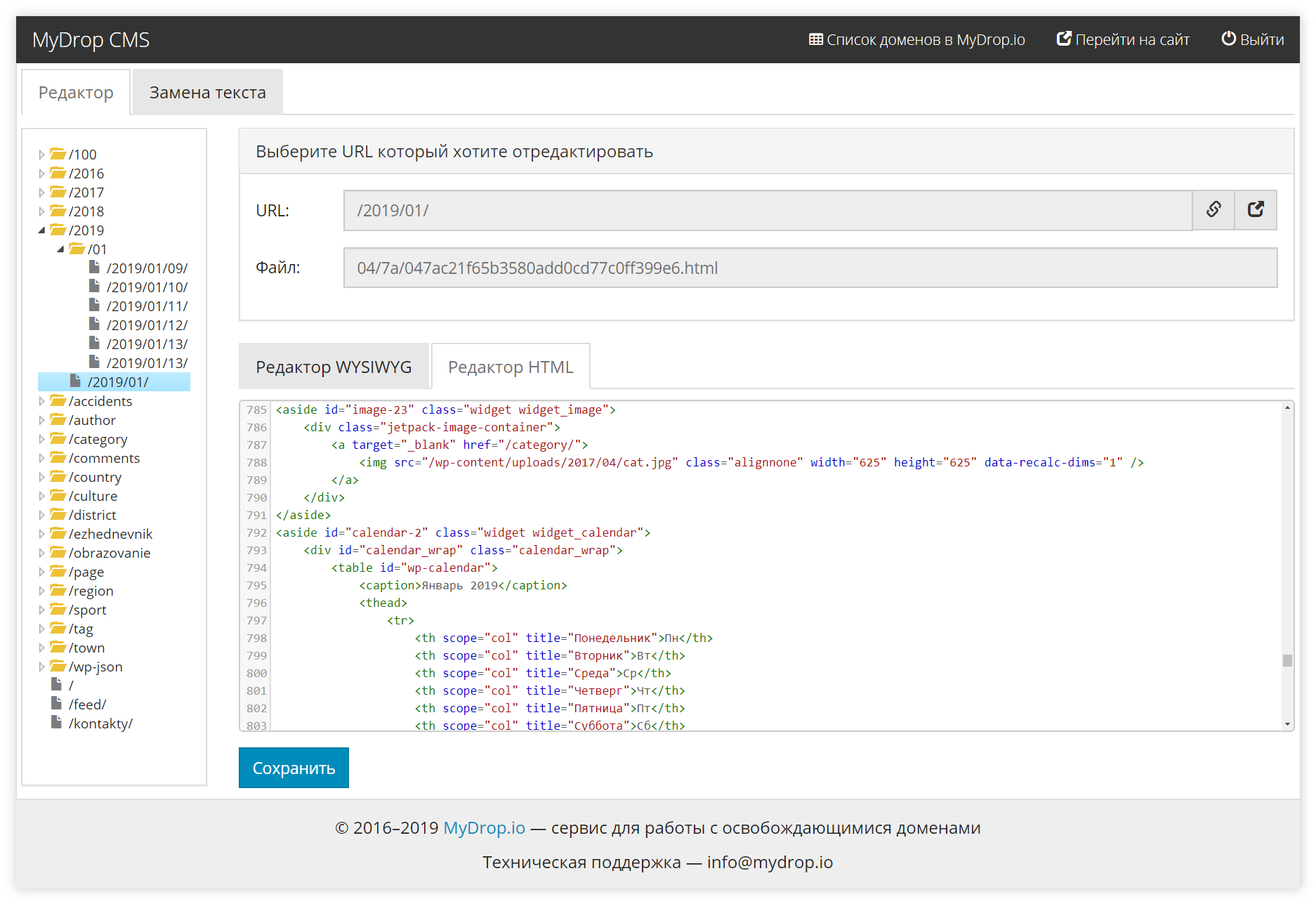
MyDrop
Сервис предлагает веб-мастерам списки освобождающихся доменов в 100+ доменных зонах. Кроме этого он даёт возможность восстановить контент и предварительно посмотреть, как он выглядит.
Особенность MyDrop в том, что парсинг данных осуществляется не из Web Archive, а из своей базы. В отличие от веб-архива, сервис бережно сохраняет все страницы и особое внимание уделяет структуре URL.
Сервис идеально подходит для веб-мастеров, которые хотят заниматься восстановлением и продажей дроп-доменов. Он собирает данные по всем освобождающимся доменам и сохраняет цифровые снимки 100% страниц.
Как найти уникальный контент с помощью веб-архива?
Разработчики Wayback Machine создавали его для исследователей, которые любят изучать старые сайты, но им активно пользуются SEO-специалисты, веб-мастеры и манимейкеры.
Веб-архив интересен ещё и тем, что он предоставляет уникальный и бесплатный контент. На рынке даже есть магазины, где можно недорого купить статьи под любую тематику из Web Archive.
Веб-мастеры покупают контент из веб-архива для наполнения сателлитов, PBN-сеток и даже размещают его на продвигаемых сайтах. В некоторых случаях он приносит трафик, но поиск хорошей и полезной статьи может затянуться на несколько часов.
Как получить уникальных контент с максимально с помощью Web Archive:
- Находим списки брошенных доменов релевантной тематики
- Анализируем данные из веб-архива
- Вытаскиваем нужные статьи. Можно использовать парсеры из предыдущего пункта
- Публикуем на своём сайте
- Получаем трафик
Проблема подхода в том, что такой контент может быть не уникальным. Несмотря на высокие показатели по Text.ru, Content-watch и другим сервисам. Опытные веб-мастера знают, что у поисковых систем есть аналоги веб-архива, где хранятся данные по страницам, которые обнаружили краулеры.
Можно использовать такой способ для создания сетки PBN и наполнения ее контентом, но если речь идёт о крупном проекте с большими планами на будущее, лучше заказывать статьи в блог или описания для посадочных страниц у надёжных авторов.
Совет: добавляйте на сайт действительно уникальный контент. Мы подготовили материал: обзор популярных украинских бирж статей.
Какие есть аналоги Web Archive
Сервис работает 25 лет и за это время накопил огромную базу в 615 млрд страниц. Очевидно, что у такого инструмента нет аналогов. Сервисов с более свежими данными хватает, но посмотреть полную динамику развития сайта можно только в оригинальном веб-архиве.
Из похожих по возможностям сервисам можно выделить:
Полноценного конкурента у Web Archive нет. Например, последний сервис позиционируется как «уникальное» решение и защищен патентом, а по факту парсит данные из Wayback Machine. Страница, которую мы добавили в веб-архив в процессе написания этой статьи, чудесным образом появилась и у клона.
В качестве альтернативы можно использовать сервисы, которые позволяют извлекать данные из кеша поисковых систем. Например, Cached View даёт возможность увидеть сохранённые версии страниц в кеше Google и Web Archive.
Ещё один интересный инструмент — Time Travel. Сервис ищет данные о страницах по всем веб-архивам и даёт возможность переключаться между цифровыми снимками с разными датами.
В каком-то смысле Archivarix можно назвать аналогом веб-архива, потому что сервис не только парсит с него информацию, но и накопил исторические данные по 350 млн доменов с 2017 года. Он предоставляет возможность искать страницы по ключам в своей базе, а сохранённый контент берёт начало с 1996 года.

Неочевидные способы использования веб-архива
Если на время забыть о SEO и вспомнить о задумке разработчиков Wayback Machine, то легко найти неочевидные варианты применения сервиса. С его помощью можно не только восстанавливать контент, следить за конкурентами или добывать бесплатные статьи.
Дополнительные варианты:
- Доказательства для суда. В американской судебной практике уже есть случаи, когда данные из Web Archive использовались как доказательство
- Разоблачение мошенников. Даже если они удалят сайт с хостинга, цифровые снимки могут сохраниться в веб-архиве
- Журналистские расследования. Независимые журналисты в своих материалах часто используют данные, которые уже не получится найти в Google
Не все считают веб-архив полезным инструментом. Например, есть мнение, что это самый большой пиратский сайт. В 2020 году компания даже получила иск о защите авторских прав.
Краткая выжимка статьи:
- Web Archive сохраняет цифровые снимки страниц
- Алгоритмы веб-архива выбирают важные страницы
- Сервис можно использовать для решения разных SEO-задач
- Можно добавить или удалить контент из Wayback Machine
- Есть много сервисов для автоматизированного восстановления сайтов из веб-архива
- Полноценных аналогов Web Archive не существует
Пишите в комментариях, для чего используете веб-архив? Восстанавливаете сайты, следите за конкурентами или смотрите на старый дизайн популярных площадок?