Фокстрот — один из лидирующих E-commerce проектов на рынке Украины в сегменте техники, электроники и гаджетов. На сайте говорится, что ежемесячно онлайн-платформу посещает около 10 млн. пользователей. Работа с ресурсом на десятки миллионов страниц, требует постоянного мониторинга его технического состояния.
Максим Федорук расскажет о переезде на новую платформу, о факапах с бюджетом на сервера и краулинговом бюджетом, о том как увеличить трафик за счет внедрения микроразметки и других нюансах работы с таким крупным проектом.
Разбор будет проходить на основе нескольких кейсов. Также Максим расскажет об инструментах, с которыми можно работать и решать технические проблемы сайта.
А перед тем, как перейти к кейсам, советуем вам читать наши материалы по теме: Как сделать техническую оптимизацию сайта и Какие есть SEO сервисы для проверки технических ошибок, работы с семантикой и других задач seo-специалистов.
Кейс №1. Много запросов на сервер от GoogleBot
Первый кейс: GoogleBot делает чрезмерное количество запросов на сервер. С этой проблемой мы столкнулись при очередном техническом аудите накануне прошлой Черной пятницы в 2020.
DevOps-ы сообщили об аномальном поведении ботов и краулеров. За счет этого роста у нас x-large нод поднимается больше 20. Такая инфраструктура чисто под GoogleBot-а стоит порядка 40 тысяч долларов в месяц. Даже если нет никаких технических проблем, мы понимаем, что здесь проблема по стоимости.
Ключевые проблемы, которые у нас возникли из-за активности ботов:
- идет постоянное развертывание нод из-за настройки автоскелинга. Пример: если ноды загружены на 70%, в течение нескольких минут разворачивается дополнительная новая нода, чтобы сайт хорошо работал и держал нагрузку;
- чрезмерная нагрузка на базу данных. У нашей базы данных старой реализации проблема была в том, что она могла уйти в потолок. В этом случае приходилось резать инфраструктурные моменты, например, отключать структурные элементы на сайте, просто чтобы он жил;
- впереди Черная пятница, а мы уже на пределе своих возможностей. У нас инфраструктура трещит по швам, а мы еще не получили реальный трафик от людей, который в Черную пятницу у нас x3, x4, а может быть и x5.
Гипотезы
Наша основная информация от DevOps-ов, что самый крупный бот – это GoogleBot. Больше всего запросов идет именно от него. Мы начинаем выдвигать гипотезы:
- Кто-то прикрывается GoogleBot-ом и парсит нас. На том же Netpeak Spider и Screaming Frog можно выбрать GoogleBot Mobile или GoogleBot PC и попарсить кого-то из конкурентов для воровства контента или изучения конкурентов
- Идет атака на сайт. Мы крупный проект. Может, кто-то пытается нас «положить» перед пиком сезона или украсть данные. Читайте более подробно, как защитить сайт от взлома и атак
- Действительно проблемы и GoogleBot что-то нашел. Дальше наши предложения шли на практике
Первое предположение: возможно разработчики вылили в прод кривой билд. Бывает так, что сборка может залиться не на все ноды. Например, у нас есть 7 нод, а на 8-мую ноду залилось плохо. Это плавающая ошибка. В одном большом проекте у нас была история с тем, что индекс Nofollow там был мигающий за счет того, что на части нодов сборка была правильная, а на части – нет. То есть, часть пользователей видела одно, часть – другое. Плюс сборка может быть сама по себе кривой, т.е. просто сделали кривой билд. Мы параллельно делали технический seo аудит сайта и выдвигали новые гипотезы.
Следующее наше предложение заключалось в том, что новый функционал нарушает работу старого.
Также могла быть просто аномальная активность GoogleBot-а. На старых графиках у нас были пики, когда GoogleBot активно сканил.
Еще одна гипотеза: GoogleBot нашел путь к каким-то старым скрытым файлам и папкам, находящихся в структуре, которую он раньше не видел.
Проблема также могла быть с генерацией фильтров. На фильтры мы сразу посмотрели, потому что это самый большой тип страниц. Если взять все комбинации пересечения фильтров, их гораздо больше любой другой страницы. Мы точно понимаем, что это не «Товары», потому что они имеют уникальные урлы, их ограниченное количество. Вероятнее всего где-то есть пересечения, т.е. проблема в сортировке, фильтрах. Гипотезу мог подтвердить детальный технический seo аудит сайта.
Анализ инфраструктуры и безопасности при техническом аудите
Далее мы начинаем разбирать вопрос по безопасности.
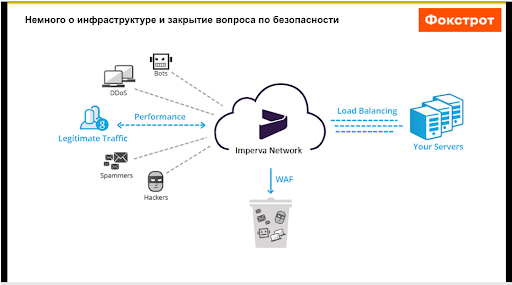
Допустим, нас начинает кто-то парсить. Во-первых, у нас стоит Imperva – это система защиты, которая имеет очень сильный Application Firewall и отсекает весь шлак. Как видно по графику, у нас Imperva легитимный трафик проводит, а боты, DDoS, спам и тому подобное остается на ней, она их блочит. Мы по Imperva бывает расширяем списки, т.е. можем блочить страну, айпишники. Плюс она очень хорошо определяет диапазон айпишников GoogleBot-а. Например, если вы зайдете со Screaming Frog и будете пытаться нас парсить, то через пару страниц вас просто заблочит, потому что Imperva понимает, что вы – фейк.
Дальше наш легитимный трафик проходит на Load Balancing, где у нас стоит CloudFront, а затем на амазоновские сервера. Мы сразу поняли, что никто не смог обойти Imperva.
Дополнительно проверили по самому сайту наличие уязвимостей. Вдруг кто-то бы обошел по ним Imperva, но таких кейсов не нашлось. Мы остановились на том, что варианты с какими-то проблемами по безопасности закрыты и никто нас не парсит, потому что Imperva имеет очень сильный Firewall. Если у вас нет этого сервиса, то вам придется брать айпишники, которые представляются GoogleBot-ом, и смотреть с каких стран они спрашивают. Например, GoogleBot никогда не придет к вам с Украины или с России. У них в основном американские IP-адреса. Если вы сомневаетесь в каком-то IT, можно сделать реверс DNS-запроса и посмотреть действительно ли это GoogleBot.
Как найти технические ошибки на сайте
После этого мы начинаем поиски по сайту. Самый стандартный вариант – использование сеошных парсеров, таких как Netpeak Spider, Screaming Frog. Мы использовали оба. Убрали все ограничения, потому что не понимали в чем проблема, и нам надо было видеть полную картину абсолютно по всем урлам, и начали парсить сайт.
Проблема в том, что стандартные парсеры берут контент, который только физически присутствует на странице, а Google получает данные не только с физического присутствия какой-то ссылки на странице, но и с внешних источников. Плюс его парсер значительно сильнее любого софта, который вы можете себе придумать.
Как убедиться, что ваш сайт сканирует именно GoogleBot
По результатам этого аудита мы ничего не увидели. У нас все нормально, все страницы плюс-минус одинаковые, и каких-то глобальных аномальных проблем мы не наблюдаем. Но при этом бот продолжает класть наши серверы.
Что касается истории с реверсом DNS, здесь ссылки, чтобы собрать информацию об айшниках. Если вы сомневаетесь, что это действительно GoogleBot, вы можете взять какую-то выборку, сделать обратный DNS-запрос. Проще говоря, вам говорят: «Я – GoogleBot», вы ему стучите обратно, и только Google может ответить, что это GoogleBot. Здесь это подделать невозможно, а если возможно, то это какой-то next level. Обычно это самый лучший вариант проверить, действительно ли вас посещает Google.
Анализ отчетов в Google Search Console
Дальше мы получаем одну зацепку. Если вы будете смотреть отчеты в Google Search Console в Покрытие – Исключено – есть отчеты по Не найдено (404), где находятся страницы, закрытые от индексации. Там мы видим среди тысячи url вот такую странную историю, в которой пересекается наша система тегирования.

Появляются километровые комбинации url, которые у нас в системе нигде не генерировались, такую прямую ссылку получить нельзя. Мы получили триллиард комбинаций именно такого формата, и понимаем, что у нас проблема с фильтрами и системой тегирования. Это первая наша история. Важно, что прогон софтом их не находил.
Проверка логов сервера
Мы принимаем самое верное решение, которое является основой современного аудита. Стандартный аудит заканчивался тем, что люди запускают, например, Netpeak Spider либо Screaming Frog, делают аудит сайта, клацают что-то руками, максимум проверяют скорость GTMetrix. Вот и весь аудит. В текущих реалиях GoogleBot очень хорошо разбирает логику javascript. К сожалению, все существующие парсеры не могут так глубоко нырять. Если вы не используете логи, то будете видеть только половину всех данных по вашей техничке.
Логи сервера – это запись о посещении вашего ресурса любым ботом, юзером и т.д.
Самые важные данные, которые вам нужны в логе:
- IP-адрес,
- дата и время посещения,
- тип запроса (get или post),
- страница, которая посещалась;
- протокол, по которому было посещение;
- код ответа сервера и User-агента.
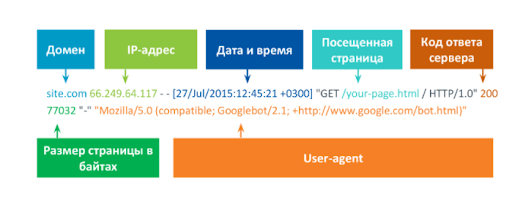
Так вы сможете точно понять, кто к вам заходит. Размер страницы здесь не сильно важен. Это ключевые данные, которые вы можете вытащить с лога.
Как работать с логом:
- с помощью специальных инструментов. Пример: Kibana. Его юзают все разработчики, DevOps-ы и т.д. Я дал ссылку на logz.io, это саасная Kibana. Например, у нас Kibana стоит на своих серверах. Если у вас мелкий проект и нет этого инструмента, вы можете использовать саасное решение, загружать туда свой лог и с ним работать. При этом у них версия trial на 7 дней. Дл небольшого лога его будет достаточно. Если лог масштабный, то можете использовать платную версию (~2$) и будете иметь саасное решение, но все-таки Kibana
- через Excel. Вы разбиваете лог по столбикам и дальше благодаря фильтрации работаете с ним
- Jetoctopus. Это хороший сервис, но мы, например, любим Kibana, потому что здесь доступны регулярные выражения и сюда можно напрямую стримить данные и т.д. Для меня Kibana – это самый взрослый подход из всех имеющихся
- Screaming Frog SEO Analyser, но здесь бесплатная версия до 500 урлов, а платная значительно уступает Kibana.
Что мы можем брать с лога:
- список посещенных url и частоту сканирования по ним.
- redirect-ы,
- ошибки сканирования (ответы 404 и 500)
- эффективность распределения краулингового бюджета. Если мы взяли GoogleBot и посмотрели, например, что он посещает кучу каких-то шлаковых страниц, а основные категории или товары посещает за неделю 1-2 раза, то, вероятнее всего, у нас плохо распределяется сам бюджет.
Лайфхаки работы с логом в Kibana
- Отсекаем свой IP-адрес. Если вы парсите сайт и представляетесь GoogleBot, то это шлаковые данные
- Отсекаем все логи, которые не содержат user-агент GoogleBot
- Проверяем диапазон айпишников, с которых нас посещает GoogleBot. По сомнительным делаем реверс DNS.
Это можно сделать через Ubuntu терминал и получить ответ для любого сайта. Если вы попытаетесь тестировать на своем сайте, где стоит система защиты, то не сможете сделать обратный DNS-запрос, потому что она вас заблокирует. - После отправки данных в Kibana проверяем количество строк, которое передалось. Классная практика: Сделать первый файл маленький, допустим на 100 строк. Залить в Kibana, посмотреть, как прошла заливка, посмотреть количество строк, а потом уже грузить большие партии. Но количество строк все равно нужно проверять потому, что может произойти какой-то сбой, и вы не догрузите данные
- Используем Grok, если Kibana не распознала ваш лог (допустим у вас есть Engine, патч серверы). Тут маленькая инструкция по паттернам для Grok-а. Вы должны будете объяснить Kibana-е, какой элемент лога что означает
- Большой лог нужно разбивать на несколько файлов. Если у вас большой лог, вам также придется его разбивать на несколько файлов. Например, лог может быть 2 Гб. Тогда вам надо использовать unix команды, разбивать их по какому-то определенному количеству строк. Например, через Ubuntu стандартная команда разбить – это сплит пробел тире L количество строк пробел название файла, который вы будете разбивать. Он вам прямо в папке, где лежит этот файл, разобьет его на нужное количество строк.
Пример Grok
Он выглядит примерно так

Вы объясняете Kibana свой лог. Например, мы показываем IP, потом пробел, после идет тире, опять пробел и т.д. Мы описываем весь лог, который у нас представлен в виде Grok-а. Дополнительно есть Grok-конструктор — сервис для проверки. куда можно закидывать лог, писать по нему Grok и смотреть, как он разбивается. Таким образом можно потренироваться в написании Grok-а.
Выводы после технического анализа
На основе данных лога мы сделали два вывода:
- есть проблема в реализации системы тегирования
- в системе сохранились старые ЧПУ url, при заходе на которые GoogleBot может получить ответ 200.
Вся эта история происходила, потому что у Фокстрота большой сайт и самописная система. Это руками никак нельзя было найти, это можно было увидеть только по логу, когда бот посещает эти страницы.
Плюсы в этом кейсе: все эти страницы были закрыты через <meta name="robots" content = "noindex, follow />.
На выходе — увеличение мусорных комбинаций фильтров, закрытых от индексации. GoogleBot увеличил краулинговый бюджет сайта в десятки раз и начал просто в бешенном темпе переобходить эти мусорные страницы. Отсюда можно сделать вывод, что <meta name="robots" даже c noindex nofollow в целом не запрещает ботам посещать страницу.
Мы получили картину: бот открыл страницу, увидел запрет на скан и ушел на следующую. Проблема инфраструктуры оказалась в том, что бот не может получить ответ "noindex" до того, как он откроет страницу. Он ее открывает, получает noindex и уходит, а поскольку он открывает их много и быстро, это начинает загружать и CPU процессоров, и поднимать ноды и т.д.
Что делали
Варианты по решению этой проблемы:
- Запретить в robot.txt. Но в наших кейсах невозможно подобрать маску url, потому что по факту это комбинация разных фильтрационных страниц. Выписывать триллиард фильтров на сайте и пытаться сделать какую-то маску просто невозможно. Плюс, если GoogleBot знает о странице, то зачастую, особенно на крупных проектах, robot.txt игнорируется. Например, если бот нашел в больших количествах какие-то ссылки в коде или скриптах, то исходя из нашей практики, он его игнорирует. То есть бота не удавалось остановить через robot.txt в подобных случаях. Если он страницу никогда не знал и не посещал, то robot.txt в этом плане помогает. Но если бот ее знает, то у нас возникали проблемы
- Заменить часть noindex follow на noindex nofollow, чтобы сказать боту: «Не индексируй, не иди дальше». Мы это сделали на большей части сайта, но по результату это ничего не дало.
- Использовать Http-заголовок X-Robots-Tag: noindex. Идея была в то, что Http-заголовок заголовок поисковый робот видит раньше, чем код страницы. Это должно частично снизить нагрузку на сервер.
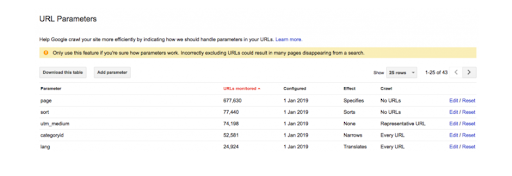
- Запретить сканирование страниц по параметру Url. Инструкция, как это сделать. Отсекаем параметры, которые Google лучше не посещать. У нас это работало плохо. Причины: наш сайт старый, в консоли вбита https версия, а оптимально подключить консоль через DNS-запись и получить две версии сайта. Потому что в старой могут быть какие-то настройки по параметрам Url и возникает конфликт. Мы запретили некоторые вещи через «Параметры Url», а бот все равно ходил дальше. Если у вас сайт был когда-то на http, то тоже проверяйте параметры Url, площадь http-версии.
![Запрет на сканирование гугл через «Параметры Url»]()
- Уменьшить количество прямых ссылок на закрытые страницы. В результате технического анализа сайта мы предположили, что если бот находит какие-то ссылки, то нужно попытаться уменьшить количество шлаковых ссылок на страницах, чтобы он их вообще не видел. У нас не ЧПУ-шные фильтра формируются через ?filter=. Мы решили для этих фильтров не проставлять физическую ссылку в фильтр сайта на категориях и других фильтрах, пока она не станет ЧПУ-шной. Мы понимаем, что эти страницы закрыты от индексации, они не ЧПУ-шные, мы их не прорабатываем и боту там делать нечего.
Единственный минус: может возникнуть проблемная история с индексацией товаров. Если есть проблемы тегирования, дальше мы делаем фикс системы тегирования и убираем возможность выбора тега на уровнях вложенности, чтобы нельзя было делать пересечения нескольких тегов. Почему? Потому что по частотности нет смысла, в основном теги и так уже низкочастотники. А пересечение двух низкочастотников в Индекс не открывается, там ничего интересного нет.
Возникает мысль, что если закрыть столько страниц, то могут возникнуть проблемы с переобходом карточек товаров. Чтобы избежать этого, мы реализовывали доработку с перелинковкой непосредственно на карточки товара. У нас есть такая вещь как Softcube. Это интеллектуальная система подбора товаров. Грубо говоря, рекомендации «С этим товаром покупают…», «Вы смотрели…» и т.д. Мы попытались это открыть в Индекс, но у начал падать Softcube, пошла большая нагрузка на процессоры. Поэтому пришлось отказаться от этой затеи и убрать его обратно в отложку.
Дальше мы сделали обычный блок перелинковки, который работал по такой логике, что первые 5 товаров ссылаются на следующие 5 товаров. Этот блок перелинковки мы разместили по всем товарам. Для нашей истории мы решили вопрос того, что товары хоть как-то залинкованы и все работает в рамках своей категории. - Полумеры. Поскольку нам нужно сэкономить деньги, решили прибегнуть к каким-то полумерам. Для меня это именно полумеры, потому что если с нашей проблемой мы бы сделали это на долгосрочную перспективу, то получили бы огромные проблемы с индексацией, потому что для нас это нехарактерное количество запросов.
Что нужно сделать? Нужно зайти в настройки частоты сканирования роботом в консоли, задать настройки, чтобы бот заходил не больше 8-10 запросов. Буквально через полдня-день бот сильно снизит количество запросов по вашему сайту.
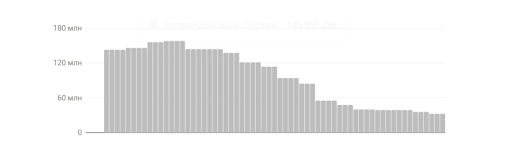
Важный момент: например, у Фокстрота стандартный обход чуть ли не в миллион посещений. Если мы сделаем 10 запросов в день, представьте, насколько проблемно станет загонять страницы в Индекс, при условии того, что у нас еще появилась куча шлаковых страниц. Некоторые включают это решение на пару месяцев, а затем начинают постоянно продлевать. Но если эту историю держать долго, то вы просто замораживаете эту проблему. Плюс возникает еще одна проблема — ваш сайт не индексируется нормально. - 410 ответ вместо тысячи слов. На графике ниже видно, что когда мы начали падать, у нас было 350 миллионов, потом стало 180 и вообще ушло в ноль. Мы поняли, что вероятнее всего, придется давать 404-ответ либо 410-ответ. Разницы между ними никакой, потому что для Google это одно и то же. Мы давали 410 просто по причине личного спокойствия. 410-ответ – это страница удалена навсегда.
![Падение позиций сайта и ответ 410]()
Важно: не использовать методы одновременно!
Например, директива noindex будет эффективна, только если доступ робота GoogleBot к странице не запрещен с помощью файла robot.txt или иного средства. Если поисковый робот не может просканировать страницу, он не обнаружит директиву noindex. В этом случае страница по-прежнему сможет появляться в результатах поиска, например, если на нее ссылаются другие страницы.
Кейс №2. Битые ссылки в data-url
Второй наш кейс еще раз подтверждает важность логов. Этот кейс был связан с переездом на новую систему управления сайтом. С чего мы начали технический аудит сайта? Мы взяли лог, изучили его 800 тысяч строк и выяснили, что более 40% посещений GoogleBot выдает ответ 404.
Бот тратит огромное количество ресурсов. Когда мы начали изучать эти страницы, они оказались нашими data-url. Вот пример data-url-а. В них обнаружились «9472&», где amp идет мусорный. Как это получилось? Новый движок системы генерировал ссылки, а браузер их кодировал и просто добавлял amp к значку &. В результате появился несуществующий адрес, и он получал 404.
Если бы не лог, мы не нашли бы ни первый, ни второй кейс. Лог – это 50 процентов картины. Даже если у вас мелкий проект, вы сможете увидеть проблемные скрипты, по которым ходит бот; тратиться ли ваш краулинговый бюджет по назначению.
Например, если у вас маленький сайт и открыта в Индекс тысяча url, а в консоли закрыты от индексации 3-4 тысячи мусорных. Бот по ним ходит, тратит бюджет. Ваши страницы, которые могли бы сканиться чаще, остаются без внимания. Допустим, вы работаете в нише, где часто воруют контент. Если ваш сайт плохо индексируется, у вас его успеют своровать. Просто за счет того, что у вас есть «мусорный прицеп», и вы не хотите фиксить. Учитывайте это при техническом анализе сайта.
Важно, что при любом парсинге Netpeak Spider или Screaming Frog data-url-ы не сканируются, т.е. вы никогда не узнаете, если у вас проблемы. Если бы мы это не фиксили, я думаю, что сайт со временем бы очень сильно стало водить в стороны.
Как устранить битые ссылки на сайте
Поговорим о том, как бороться с битыми ссылками на сайте. Это первое, на что обращают внимание seo-специалисты при техническом анализе сайтов. В Kibana вы можете делать Дашборды. Вот пример Дашборда с Kibana, который я взял из Интернета.
Что можно делать в дашборде Кибана:
- сделать подборку по количеству страниц с ответом 200, 300, 400 или по определенному типу страниц (.html, .css, .jpeg);
- наблюдать здоровье сайта чуть ли не режиме реального времени;
- мониторить различные файлы по странице;
- сделать маски url, которые хотите мониторить.
С помощью такого Дашборда вы в реальном времени видите картину того, что происходит с сайтом. Это уже действия на опережение.
Читайте материал Collaborator, как устранить битые ссылки на сайте.
Кейс №3. Устраняем ошибки со скоростью загрузки
Этот кейс связан со скоростью загрузки. Здесь выделим частые ошибки оптимизаторов и разработчиков
Ошибка №1: контент с первого экрана просмотра расположен слишком далеко по коду.
Состоит в том, что нужные элементы находятся слишком низко по коду. Когда бот заходит на страницу, он ее сканирует сверху вниз. Если какой-то баннер у вас находится ближе к футеру, а визуально отрисован ближе к хедеру, то придется ждать, когда бот просканирует весь код и только после этого доберется до нужного баннера и все подтянется. Важно, чтобы нужные элементы для первого экрана просмотра были максимально близко к началу страницы.
Ошибка №2: все картинки в формате WEBP.
Очень крутой формат, но старые операционные системы Apple его не поддерживают. Вы также можете отрезать часть трафика со старых устройств, которые по какой-то причине не обновились.
Ошибка №3: блокам с отложенной загрузкой не задали фиксированный размер.
После летних апдейтов, все начинают переживать за смещение макетов. Зачастую люди запускают синтетику через PSP, видят, что у них все хорошо по смещению макета. А потом смотрят Пользовательский отчет через 28 дней, а там все плохо. Плохо, потому что вы используете синтетику и можете «обманывать» Google. То есть часть блока вы можете сделать в отложенную загрузку и в синтеттесте он их не увидит. Но пользователи видят эти блоки с отложенной загрузкой, а для них нет фиксированного размера. Когда блок прогружается, происходит как раз смещение макета и ваша «гармошка» раздувается. Решение – задавать фиксированный размер блоку.
Ошибка №4: для gzip или brotli не задан уровень сжатия и он равен 1.
Еще одна ошибка, когда gzip или brotli вроде бы настроен, но ничего особо не сжимает. Разработчик это поставил, а уровень сжатия равен 1. Варианты есть (у того же brotli от 1 до 5). Получается, что функционал есть, но он не работает в полную силу.
Ошибка №5: мусорные скрипты.
У нас был классный кейс: после теста нашей системы защиты Imperva, мы подключали Bot protection. Функционал включили-выключили, но скрипт остался. Произошел какой-то лаг на Imperva и остался скрипт, который не работает. Он создавал нагрузку на процессор в 2574 миллисекунды. Это сильно влияло на скорость системы.
Ошибка №6: проблемы с интеграцией сервисов IT-аналитики (AppDynamics, Dynatrace).
По факту это большие сервисы, которые показывают, какой кусок кода где сбоил. Но при их кривой интеграции возникают задержки 3-4 тысячи миллисекунд на процессор. Когда эти две истории совпали, мы поняли, что секунд 10 будем ждать ответ сервера.
Ошибка №7: не проверяются разрешения изображений.
Если у вас какие-то картинки большие, важно, чтобы для Mobile они не сжимались через CSS. Например, чтобы грузилась отдельная картинка с нужными параметрами. Потому что если сожмете с CSS, размер и вес картинки не меняется, а для Mobile это слишком много. Для него картинка размером 2000х2000 пикселей не нужна.
Ошибка №8: неправильно настроено кэширование статических элементов.
Для Mobile особенно важна отложенная загрузка для скрытых изображений и разных элементов. Плюс можно работать со скриптами внешних подрядчиков. У наc скрипт Приватбанка создавал большую нагрузку при первой загрузке страницы. В итоге мы пообщались с их разработкой и смогли разбить сбор данных на 3 этапа (ранее собирались одним запросом). Для них ничего не поменялось, но для нас нагрузка упала в разы.
Сессия вопросов-ответов
– Есть отдел безопасности, который выбирает решения, с которыми он будет работать. Мой прошлый опыт — Angling и другие решения, которые использовались только для скрытия своего хоста. Поэтому с Cloudflare мы знакомы. Мой субъективный вывод: Imperva по количеству настроек и по силе Firewall-а в разы сильнее. В плане инструмента для безопасности, а не скрытия хоста, Imperva лучше.
Также у нее есть инкапсульная защита (не скажу, есть ли она на Cloudflare). То есть, если вы сделаете запрос на сайт, и у Imperva будут сомнения, то она вам высылает капсульную защиту. Вам отправится скрипт для проверки, он даже Google отправляется периодически. Фишек по функционалу именно в плане безопасности в Imperva намного больше. А поскольку для нас важный момент в том, чтобы нас не «положили» никакой атакой, то именно сам Firewall очень мощный. Мы до этого юзали амазоновский Application Firewall, но он был ни о чем. Атаки через него проходили, а Imperva очень мощно держит. Это, конечно, вопрос уже больше на безопасность, но в плане настроек Imperva на голову выше, хотя и намного дороже.
– Любые связки замедляют работу сайта. Потому что сначала идет обращение на IP Imperva, она перепроверяет легитимный ли трафик и перенаправляет его дальше. Каждый элемент из цепочки снимает какие-то баллы, но по скорости никаких критичных моментов нет.
Плюс Imperva в том, что у нее есть функционал по сжатию. Каких-то глобальных просадок по росту, когда мы включали-выключали Imperva, не замечали. Когда мы полностью «тушили» Imperva, если брать page speed, то где-то 1 балл у нас улетел. Если все хорошо настроено, то проблем не возникает.
Еще один момент, что многие сейчас большое внимание уделяют скорости. Я смотрел большие зарубежные исследования, у ребят максимальный рост в позициях был в основном при выходе из красной зоны в желтую. Когда ты находишься в стабильно желтой зоне (60-65 баллов), то с переходом в зеленую зону рост позиций минимальный. Это то, что мы видели по тестам и наблюдаем на практике.
Поэтому если вопрос в задержке, то лучше сделать выбор в пользу безопасности. Во-первых, чтобы вас никто не DDoS-ил. Во-вторых, это лишняя проблема для конкурентов вас парсить. Imperva можно обойти, но это требует усилий.
– Не нужно бороться. Первое, вы можете посмотреть, может у вас нормально не прописаны alt-ы по картинке. Но картинки – это трафик. Опять же, момент, чем сайт занимается. Может для вас наличие огромного количества картинок – это must have. Но я бы с этим не боролся. Если у вас изображения с alt-ами, то бот должен видеть контент. Если картинки есть, он должен их видеть. Это нормально. Лучше посмотреть лог, потому что если вы видите это по Search Console, то это не о чем. Тысяча урлов это не показатель.
– Здесь нет разницы. В принципе x-default не является must have тегом. У нас, например, стоит Hreflang русский и Hreflang на украинскую версию. Нам этого хватает. X-default можно сделать, но разницы никакой. Может в том случае если бы мы определяли дополнительно по IP, меняли языковую версию. Скорее всего, эта история подходит под международный сайт, у которого много языковых версий, здесь это классно бы работало. Но для локального проекта, который заточен под одну страну, это не нужно.
– Сейчас еще русский. У нас была смена CMS и мы для чистоты данных не решились сделать украинский язык по умолчанию, как у нас сейчас идет по закону. Лайфхак: у нас все внутренние файлы идут через папки. Это уже плюс, что идет папка.ру и папка.укр. Если вы где-то попали на папку.ру, то это страница не по умолчанию, потому что вы на русской языковой версии по url. По факту, у нас все внутренние страницы по закону.
– Если брать то, что дает нагрузку, например, на базу данных, серверы, тогда вопрос не в технологиях, а в том, насколько правильно написан скрипт, сколько он делает запросов. Когда мы начали оптимизировать площадку, наш технологический стек был понятен из нашей прошлой системы. Разработчики у нас пишут на C#, значит у нас в любом случае будет он. Мы изначально были на облачных серверах Амазона, а перед ними стоит Imperva и Cloudfront. То есть у нас ничего особо не поменялось. Единственное, что начали юзать Redis, которого раньше не было. Технологический стек не особо менялся, но все ключевые проблемы были связаны с тем, что не оптимально записаны запросы в базу данных. Какой-то запрос можно сделать проще и он не будет нагружать базу. То же самое и по сайту: например, страница долго грузится, потому что громаднейший фильтр вызывается одним запросом. А этот фильтр можно брать с ElastiCache и подтягивать какую-то готовую версию. Но это история уже не про технологии, а про качество написания самих скриптов, в том числе и внешних, которые вы разместили. Зачастую именно какой-то запрос плохо записан в сайт либо в базу. Ключевые проблемы обычно в этом кроются.
– Я про это говорил. Мы использовали x-robots noindex для того, чтобы остановить бота. X-Robots-Tag по факту тоже самое, что и meta name robots nofollow. Их можно использовать и так и так. Например, вы зашли на какой-то сайт и видите, что у них все открыто для индексации. Посмотрев HTTP-заголовок, вы увидите, что все закрыто просто другим методом. Это один из методов закрытия, который в нашем кейсе с ботом не помог.
– Мы всегда можем в Google Search Console исключить url, и он удалиться из Индекса. Я бы это юзал, только если какие-то скрытые документы попали в Индекс, т.е. супер важная информация. На счет переобхода. Зачастую стартуют новые iPhone и все начинают у себя в футере докидывать ссылки на них, чтобы увеличить количество прямых ссылок на эту страницу. Плюс начинается закупка какой-то ссылочной массы, стучание либо по api-консоли, либо через Add URL на переобход. Плюс бывает, что начинают лить какой-то контекст либо какие-то социальные факторы, такие как Twitter, Facebook. То есть используют все точки, чтобы бот с внешнего ресурса перешел не страницу. Плюс вы можете в консоли попинговать. Это базовые методы.
– Глобально он у нас не просел. Если брать основной пул, у нас местами шатается сам title, но и у конкурентов его шатает. Из позитивного то, что у соседа хата тоже горит. Но для нас это глобальной проблемы не представляет. У нас оно достаточно быстро проходит, и если прошло, то у большинства. Отличие нашего проекта в том, что у нас сильный бренд. Такие бренды как Фокстрот, Розетка, Комфи на рынке узнаваемы. Люди понимают, что если там написана какая-то белиберда, пусть даже китайскими символами, это Фокстрот. Видя домен Фокстрот, они понимают, что это тот сайт, который они искали. 10 процентов трафика крупного магазина – брендовый. Хотя есть органика и платный, поэтому в сумме еще больше.
– Был случай, где нас чуть «пошатало» по страницам: к фильтрам к url перед точкой html добавился лишний slash. Вышел slash.html и проблема была в том, что у нас начали вылетать url за счет того, что бот получал 404-ответы. Деиндексации не было, наверное, по причине отменного траста к ресурсу. Вы видели, что когда у нас возросло количество страниц, бот решил, что мы подобие Амазона и начал нас сканить на сумасшедшие деньги. Поэтому проблем не было.
Если у вас идет глобальная деиндексация, первым делом нужно проверить карту сайта. Посмотреть перелинковки, все ли страницы попадают в карту, нет ли битых url. Посмотрите по хлебным крошкам, по меню. По логу посмотрите, есть ли какие-то мусорные изолированные страницы. Также бывают проблемы с самим движком. Я знаю, что у тех, кто сделан на реакте, бывают проблемы с индексацией. Поэтому здесь нужно смотреть и по техничке: вы думаете, что ссылки есть, а они стоят не физически, а через какие-то java-запросы и бот не может через них достучаться. Я бы сначала посмотрел с технической стороны, можно ли легко перейти на все эти страницы и они не имеют глубокой вложенности, что с картой сайта все хорошо и по логам – нет кучи шлака.
Дальше страницы отправлять на переиндексацию, через Add URL поспамить, попытаться их вернуть. У нас был такой кейс: выпадала одна страница. Кидали в Add URL и она возвращалась просто. Можно также ссылочный построить, попытаться определить какой-то крауд. Это диагностика по этапам. Сначала проверьте техничку. Если с ней все хорошо попытайтесь через Add URL. Не помогает Add URL, добавляйте крауда и попробуйте вальнуть каких-то социалок.
– Если брать наше ключевое ядро, оно у нас и так максимально раскидано. У нас есть система тегирования, которую мы сейчас приостановили из-за кейса №2. В первую очередь нас интересует коммерческое ядро. Наше коммерческое ядро все раскидано. Есть ключевой запрос, но при этом категорийный: купить, цена и т.д. Есть бренд плюс категория. Какие-то свойства, характеристики, модельные ряды сидят в фильтрах. У нас в принципе все присутствует, и я не вижу смысла в лютом дроблении. У нас на ноутбуках есть дробления, например, от 10 тысяч гривен и т.д. Мы в семантике создаем то, где видим траст. Плюс у нас какие-то отзывы создаются. Просто то, что пользователю не нужно, вы не находите. Например, если в категории «Смартфоны» в карточке товара больше 5-ти отзывов, у нас под них создается отдельная страничка. Пользователю она не нужна, он ее и так получит через какой-то попащник. Это больше гугловая страница выходит.
– Микроразметка вообще не дает никаких плюсов в ранжировании. Любая разметка (html5, микроразметка) нужна для того, чтобы подсказать Google о каких-то определенных элементах на вашем сайте, чтобы он их воспринимал правильно. Микроразметку организаций, хлебных крошек и т.д. нужно делать, чтобы боту показать, это точно хлебные крошки, это точно организация, это стопроцентно логотип. Передать больше информации Google, это в плюс. В основном микроразметка дает плюшки на увеличение CTR вашего сниппета. Вы CTR не увеличите, но дадите больше данных Google. Я считаю, что чем идеальнее размечен сайт, тем лучше. Я не могу сказать, что это дает какой-то выхлоп в ранжировании. Я о таком не слышал.
Читайте материалы Collaborator: Как сделать сниппеты с высоким CTR и Как сделать микроразметку FAQ Page.
– Если делать под Россию, то да, стоит. Потому что большая страна и, например, во Владивостоке и Москве, в зависимости от того, где находится сервер, это будет сильная разница. Для локального рынка небольшой страны, например, для Украины, эффект будет не настолько ярким. Вы находитесь в Украине, ваши сервера тут же, поэтому особо вы ничего не сэкономите. Но если вы украинский проект и ваши сервера находятся где-то во Франкфурте, то да. CDN система, например, будет решать, что картинки будут грузиться локально с Украины. Это зависит от того, под какие гео вы работаете и какой страны.
– До нуля вы их не доведете. Во-первых, в исключенных не ошибки. Вы будете видеть там noindex. Среди них даже какая-то часть доступна. Вы не сможете их срезать, да этого и не нужно, потому что у вас стоит noindex nofollow.
Допустим, у вас закрыта страница пагинации через noindex nofollow. Бот все же имеет возможность посещать страницы пагинации, видеть ваши карточки товара, и они будут лучше индексироваться. Зачем вам это все убирать? Этим вы можете создать себе проблему с индексацией. Так же и каноническая ссылка.
Но в этих отчетах есть и шлак. Этот шлак увидеть вам будет тяжело, потому что тысяча строк. Тысяча строк это очень мало. Даже если у вас нет Kibana, то есть хостинг. У любого хостинга есть логи. Вы можете зайти в этот лог, выгрузить его в Excel и поработать с ним. Опять же в Kibana есть trial на 7 дней. Вбиваете любую почту, выгружаете свой лог, учитесь, как его загрузить в SAA-сную Kibana и неделю работаете с ним, изучаете более детально, что происходит с вашим сайтом.
– Чем оно раздувает код? У вас идет обычная ссылочка. Если у вас кейс, когда вы для IOS создаете jpeg, а для остальных отдаете WebP, то у вас будет две ссылки и DOM-дерево чуть увеличиться. Но вы очень много выигрываете за счет веса картинки. Если вас это смущает, то делайте minifier html и тогда у вас html-код еще уменьшится.
– Opencart – это классное решение. Но тот, кто делает сайт на Opencart, скорее всего, не крупная компания. Мы брали самописное решение от наших разработчиков. Оно держит миллиардные нагрузки. Представьте нашу нагрузку в Черную пятницу, какой трафик падает на наши сервера и сколько обходится стоимость инфраструктуры под это дело. Если брать под CMS, то я бы взял Opencart. Под него есть куча плагинов, которые могут фиксить какие-то глобальные проблемы. Сам по себе Opencart дырявый, но пара плагинов, которые можно купить в сумме за тысячу гривен, могут закрыть половину его «дырок». Здесь небольшие цены и есть много инструкций и кейсов о том, как пофиксить что-либо.
В самом начале я брал бы это за основу, потому что там есть много решений. Если взять CMS от какой-то веб-студии, которая более закрыта, у вас не будет нормальной документации; с плагинами только через разработчиков. Например, если плагин, который вы можете купить для Opencart за 500 рублей, то для самописного решения он будет стоить 50 тысяч рублей.
Рекомендация от Collaborator: проанализируйте, какие CMS используют конкуренты. Читайте, как определить CMS сайта.
– Если вопрос именно в отрисовке страницы, то есть куча факторов. Первый момент зависит от того, как ответит ваш сервер, как получит первый TTFB. Любая загрузка страницы начинается с того, что запрос идет на сервер. Если есть какие-то системы безопасности, проходит их. И как только мы получили первый html-код, мы получаем наш TTFB. Это первая оценка, которая на все влияет. Дальше по первому экрану мы получаем картинки, speed index, cls и т.д. Это все комплексное и зависит от разных точек. Если у нас есть, например, Elasticsearch, то будет важно, насколько быстро он выполнит товар, который попадет на первую страницу; насколько быстро ответит сервер, прилетит картинка, которая тоже лежит на каком-то сервере. Поэтому здесь целый комплекс, а рендеринг особой роли не играет.
– Если у вас стоит Kibana, а не SAA-сное решение, то логи у вас уже стремятся туда. Логи сохраняются, по-моему, 2 недели. Две недели лог хранится, и обновляется с каждым новым днем. Если вы там настроите Дашборды, то вы будете в real time. Вам надо будет просто заходить раз в день и смотреть эти Дашборды, чтобы понимать состояние вашего сайта. Но если у вас этих инструментов нет или вы используете саасное решение, то можно оптимизировать. Например, написать какой-то скрипт и настроить на него крон. Допустим, вы на сервер положили скрипт и через крон начали стримить в каком-то саасном решении. Это такой полуавтомаический вариант.
Если вы делаете это руками, то я бы мониторил по мере того, как разработчики что-то заливают на сайт или когда происходят глобальные апдейты Google. В нашем кейсе, когда был большой апдейт Google, бот не ходил раньше по data-url. Мы его не наблюдали в переходах по data-url. Когда бот обновился, то начал активно бегать. Это уже не связано с разработчиками. Если вы не можете сделать это автоматически, у нас есть две точки, от которых нужно отталкиваться: технические изменения на сайте и апдейты Google. Плюс периодически можно проверять для себя. Мы мониторим чаще. Во-первых, потому что у нас разработчики заливают каждую неделю; во-вторых, крупный ресурс, а чем больше ресурс, тем больше проблем.
– В принципе можно. Вопрос по ресурсу. У меня специализация e-commerce и больше под Google. Я пока сосредоточен на локальном рынке. Возможно, среди вас есть seo-специалисты, которые продвигают сайты под другие поисковые системы.
– Через разметку.
И под конец хотелось бы поделиться несколькими материалами Collaborator для улучшения своих скилов в SEO:
- бесплатные SEO сервисы, которые понадобятся вам в продвижении сайтов;
- SEO сервисы для продвижения в YouTube,
- SEO курс для новичков в нашей Академии, автор: Сергей Кокшаров;
- SEO книги на русском и английском языкам: актуальная seo-литература для всех, кто учится продвигать сайты.