SEO для e-commerce: 4 типичные проблемы и как их устранить. Максим Федорук

Попробуйте Collaborator.pro
Выберите из 36441 высококачественных веб-сайтов и 3414 Telegram каналов
Вперёд
Для тех, кто работает с «техничкой» в e-commerce, доклад Head of SEO в Фокстрот Максима Федорука на Первой SEO-конференции Collaborator — просто must have к просмотру.
Ведь набор проблем тут, по сути, единый. И Максим очень подробно их описал.
Типичные проблемы SEO для e-commerce:
- неверное использование кэшированных данных;
- «мигающие фильтры» (если фильтр сам по себе нестабильный);
- текучка архивных товаров;
- медленная скорость загрузки сайта.
Рассмотрим подробнее каждую
Неверное использование кэшированных данных
Проблема
Неправильное использование кэшированных данных заключается в том, что мы сохраняем какие-то элементы в кэше. И если мы неправильно работаем с кэшем, то на странице может динамически меняться текст, title, description, h1, meta name="robots", который может рандомно закрывать и открывать страницы в индексацию и т.д.
Примеры
- Title «фены» поменялся на страничку пагинации.
- на странице Black Friday – Одесса видно, что у него title находится от Николаева.
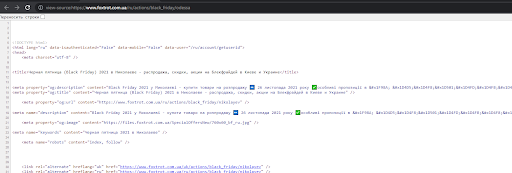
То есть данные по сайту как-то плавают и SEO-специалист не может дать гарантию, что текст, title, description, h1 и какие-то другие элементы будут соответствовать этой странице.
Решение
Диагностика проблемы. Проблему сложно увидеть при стандартном парсинге. Лучший вариант это проверить – использовать инструменты для автоматического отслеживания изменений на страницах сайта. В качестве отслеживаемых элементов используются:
- заголовок страницы (тег title),
- описание страницы (мета-тег description),
- заголовок документа первого уровня (тег h1),
- содержимое страницы (контент).
Пример инструментов: Радар в Топвизор или любые сервисы CMS для SEO. Можно трекать изменения элементов постранично и уже на основе этого строить какую-то гипотезу.
Кейс Фокстрот.
Проблема оказалась в ключе кэша. Допустим, ключом был bf_seo-1, где 1 или 3 – это код языка. То есть в нашем ключе кэша мы учитываем языковую версию, чтобы они не перетасовались между собой. Но мы не учитывали url. В итоге языковая версия совпадала, но при этом в рамках черной пятницы url не понимала. Когда пользователь заходит, мы получаем какую-то страничку в кэше, и потом эта страничка рандомно отрабатывает на любых других страницах. Если у вас мигает страница (например, контент или страница то открыта, то закрыта от индекса), вы начинаете просаживаться в поисковой выдаче.
Как решали: мониторили, находили конкретную причину постранично и передавали на разработку. Сказали, что проблемы с кэшированными данными, мы их точно определили, можно проводить на тестовой среде какие-то эксперименты. То есть можно скидывать закэшированные данные, проверять, как происходит изменение контента и дальше фиксить именно эту проблему. Легкий сервис наподобие Радара в Топвизор решает глобальную проблему на сайте.
Мигающие фильтры или что делать, если есть текучка товаров
Проблема
На сайте постоянная текучка товаров. Из-за этого трафиковые фильтра теряют товары и зачастую получают ответ 404.
Пример
- фильтр /mobilnye_telefony_apple-iphone-12-pro-max.html, каждые 2 недели теряет все товары на 3 дня. В момент launch очень тяжело получить товар на складе. То есть по некоторым фильтрам мы можем не иметь товаров. Тогда этот фильтр может скрыться с сайта.
- сезонный товар на фильтре /gazonokosilki_akkymyljator.html может быть не в наличии несколько месяцев.
В свое время для этих страниц мы купили текст, прописали title, description, h1, нарастили ссылочную массу, т.е. проработали всю страницу и в итоге получили все 404. Для интернет-магазина это большая проблема.
Решение/кейс
Разберем кейс, как это все можно поставить на конвейер
- Фильтр потерял товары — пишем дату потери товара. Она нам нужна для расчета.
- Фильтр отрабатывает по прямому URL — отдает код ответа 200
- Фильтр скрыт из категории на отображение— оставить ссылку в коде можно на усмотрение оптимизатора и убирать из кода, когда код ответа не будет = 200.
- Фильтрационная страница сохраняет ранее прописанные title, description, h1, seo-текст, каноническую ссылку, meta name robots.
- Фильтрационная страница доступна в sitemap.xml, пока отдает ответ 200.
- Наличие карточек товаров - важный коммерческий фактор, выводим сообщение: «К сожалению, товаров по заданным параметрам не найдено», далее подтягиваем товары с родительской категории или категория + бренд. Второй вариант сложнее но более целевой. Важно чтобы сортировка отличалась от категории или категория + бренд.
Или выводим архивные товары по данному фильтру. - Если фильтр потерял товары и за 3 месяца не вернул их, то ставим 302 на родительскую категорию.
- Если 302 редирект стоит больше 3 месяцев, то ставим 301 редирект.
Допустим, что фильтр потерял товары. Мы пишем дату потери товара, потому что она нам будет в дальнейшем нужна для расчета. Когда фильтр потерял товары, то он отрабатывает по прямому URL – отдает ответ 200. Сначала он не получает 404, не получает никакой редирект, т.е. он нормально работает. Дальше мы можем либо скрыть фильтр из категории на отображение, либо пока он работает на 200-ом – оставить ссылку в коде, либо выпилить ее. Это уже на рассмотрение SEO-оптимизатора.
Поскольку у нас есть страница, которая отдает 200-ую, необходимо чтобы она сохранила свой SEO-текст, title, description, h1. Потому что он целевой, проработанный именно под эту страницу и было бы круто его оставить. Оставляем.
Дальше решаем, хотим ли мы добавлять этот фильтр в sitemap.xml. Здесь два подхода. Пока страница работает 200-ым, мы можем добавлять фильтр в sitemap.xml. Как только она получает любой другой ответ, его можно убирать. Мы понимаем, что это коммерческая выдача и фильтр без карточек товаров ничего не значит. Нужно думать, как получить карточки товаров, если товар не в наличии.
Первое, мы можем для пользователя вывести сообщение о том, что товаров по заданным параметрам не найдено, и предложить что-то взамен. То есть потянуть какую-то часть товаров с родительской категории. Здесь важно, изменить сортировку. Например, мы можем взять товары с категории+бренд, чтобы они были более целевыми. Лучший вариант, если у нас есть архивные товары. То есть мы можем «потянуть» архивный товар и дополнительно миксовать его с товарами с родительской категории либо товары+бренд.
В итоге получается, что фильтр скрыт с сайта, но по прямому URL он доступен. Он получает ответ 200. У него полностью сохраняется текст, title, description, h1, и есть какие-то еще товары. И такая страничка не будет проседать в поисковой выдаче. Единственный фактор, которого не будет — цена. И то цену можно сохранять, и делать кнопку «купить» неактивной. Вместо кнопки «купить» можно поставить, что товар снят с производства или закончился. Так соблюдаются все коммерческие факторы, которые существуют.
Если есть понимание, что ряд фильтров никогда не получит свой товар, то с ними нужно что-то делать. Например: если фильтр потерял товары и за 3 месяца их не вернул, то ставится 302 на родительскую категорию. Получается, что фильтры, которые отдавали 200, завернутся 302 на родительскую категорию. Но вечный 302 тоже не нужен. Поэтому, если через 3 месяца по 302 нет никаких изменений, то ставится 301 редирект на родительскую категорию. Таким образом, мы решаем вопрос с мигающими фильтрами и потерей ссылочного по сайту. Плюс можно учитывать фильтра 1-го, 2-го уровня, т.е. не брать всю цепочку вложенности, а учитывать только первую и вторую.
Важный момент: если товар все-таки появился, то логика должна отрабатывать в обратную сторону. То есть мы по любому отдаем ответ 200, он отображается на сайте и т.д. В принципе это микрооптимизация этого кейса.
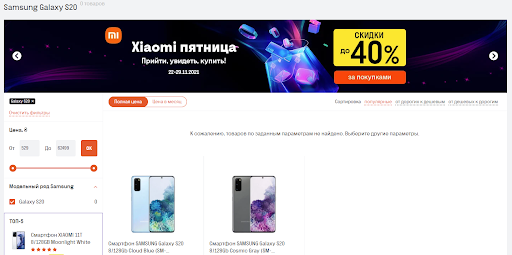
Пример того, как может выглядеть мигающий фильтр. Мы потеряли Samsung Galaxy S20, вывели пользователю сообщение, что товар не найден, вывели архивный товар, все title, description сохранились. В итоге страничка отрабатывает кодом 200, 3-4 месяца она может жить без этого товара.
Архивные товары – срок жизни
Проблема
Архив из года в год содержит все больше товаров, по которым нет остатков и мы отдаем какой-то вес сайта в этот архив.
Что с ними делать? Фокстрот, например, как большой магазин, может собирать в сотнях тысяч архивы. Они не все полезны. Зачастую на каких-то мануалах можно услышать, что ребята не удаляйте архив, вы можете с него собирать трафик и пытаться его как-то конвертировать. Да, с этим можно работать, но давайте разберем это пошагово.
Страхи SEO-шников
- если удалю, потеряю трафик
- если удалю, потеряю ссылочную массу
Решение
Максим советует придерживаться такой логики действий:
- Оптимально записывать дату когда товар ушел в архив. Это нужно для того чтобы могли проводить какую-то статистику измерения.
- Просим выгрузить разработчиков товары которые в архиве больше 1 года.
- Делаем срез по Analytics и Ahrefs. По Analytics получаем данные о трафике по этим URL, а по Ahrefs можем посмотреть, есть ли там какая-то ссылочная масса.
- Если товар без ссылочного и трафика — удаляем.
- Если товар с трафиком — оставляем.
- Если товар без трафика, но со ссылочным — клеим 301.
Нет смысла хранить огромные ссылочные массы, потому что по факту это мусорные страницы. Такого запроса уже не существует, его люди не запрашивают. Тогда зачем вам хранить 100 тысяч страниц, которые никому не нужны?
Медленная скорость загрузки сайта
Следующий наш частый кейс – как же сделать скорость загрузки. Зачастую разработчики говорят, что если у вас большой дом дерева (6-7 тысяч), то сайт никогда не будет быстро работать. Плюс это проблемы верстки и под. Рассмотрим несколько вариантов.
Web Vitals, или на что смотреть
Начнем с первой истории от Google. Когда появился Web Vitals, то все начали анализировать все подряд. Но Google сразу дает уточнение в PageSpeed, что в Web Vitals он учитывает только FID, LCP и CLS. Это легко заметить по синему флажку, который отображен в PageSpeed.

Это — своеобразная подсказка от Google: сначала выровняйте эти показатели, и у вас будет все хорошо в плане этой оценки, потому что Google не учитывает абсолютно все факторы, которые есть.
Chrome UX Report Compare Tool
Еще один момент, который почему-то многие не учитывают. Большинство людей смотрит скорость в PageSpeed. То есть мы закинули страничку, посмотрели синтетику и рассчитываем, что если придет запрос, например, из Амстердама на Украину, то у нас будет классный показатель скорости. Зачастую показатель скорости будет ниже, потому что есть какие-то задержки по серверу и здесь еще важно, как сервер отработал именно в эту секунду. Поэтому Google, в основном, учитывает данные пользователей из Chrome. Тут возникает вопрос, на который пока мне еще никто не ответил: Как посмотреть скорость загрузки у пользователя?
Существует особый отчет, который называется Crux (Chrome UX Report).
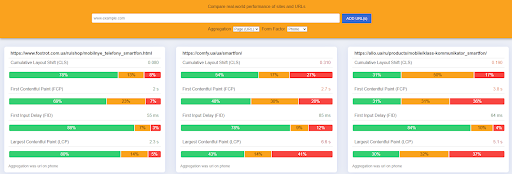
Там мы можем посмотреть, как страничка ведет себя непосредственно у пользователей.
Есть специальный сервис, с помощью которого эту тему можно масштабировать. В нем можно сравнивать свою страничку с конкурентами по ключевым метрикам, которые сейчас учитывает Google, или посмотреть, есть ли какие просадки.
Как посмотреть LCP по странице
Как сделать сайт быстрее.Фокстрот — большой интернет-магазин, SEO-специалистам здесь важно не только то, чтобы в Google все было хорошо, но чтобы и у реальных пользователей со скоростью все было нормально. Поэтому посмотрим, как на это можно влиять.
Есть LCP и CLS, как их посмотреть. Большинство людей начинают просто высматривать какие-то отрывки PageSpeed. Но если взять консоль разработчика, выбрать вкладку «Performance», включить скриншот и Web Vitals, выбрать мобильную версию и перезагрузить, то мы можем посмотреть, как ведет себя LCP на странице.
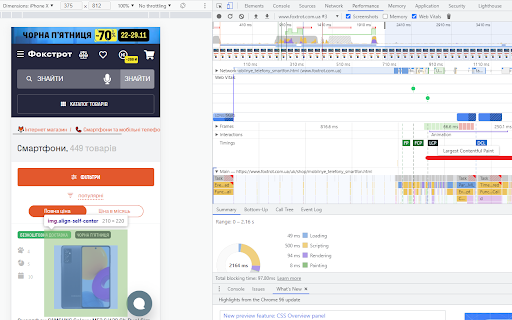
В отчете видно, какая картинка на экране учитывается как самая большая, почему она смещается. Мы даже можем сделать замедление в несколько раз и посмотреть, как быстро он прилетает. По CLS вы можете увидеть, как происходит сдвиг макета по этой страничке. То есть в реальном времени отслеживается каждый элемент и находятся проблемные точки — что и где сдвигается.
Скорость загрузки — как повлиять
Как раскачать сайт и для пользователей, и для бота?
Картинки
Хороший пример: у нас баннер на мобильной версии и баннер на ПК версии. Между ними есть небольшая разница: для мобильной версии не нужен баннер как билборд. Для mobile есть разрешение мобильного телефона, которого хватает, например, на 425х300 пикселей. Из-за разрешения картинки мы сразу экономим n-ное количество килобайт. Поэтому не стоит использовать одинаковые картинки и там, и там. Если вы разделите, то сразу получите дополнительный плюс в скорости.
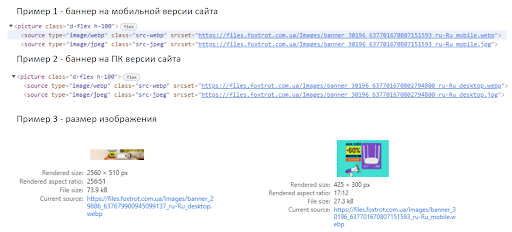
Для чего нужен srcset
Классно использовать новые форматы. Например, мы используем web, плюс которого в том, что для Google это дружественный формат и он лучше сжимается. Мы можем сжать картинку сильнее без потери качества.
Есть еще один момент, который многие люди не учитывают, это srcset. Можно выдавать пользователям картинку в зависимости от разрешения браузера. Например, если человек заходит с монитора 4k, то ему выдается одна картинка, с 2k монитора – другая, с планшета – третья.

Благодаря такой простой настройке мы можем выдавать разные изображения пользователю. Из-за этого показатель в отчете Crux будет намного лучше.
Как оптимизировать картинки для сайта:
- Использовать компрессию, сжимать картинки. Лучше это поставить на поток, потому что ваши картинки будут грузить с интернета и они, вероятнее всего, будут не оптимизированы. Поэтому все картинки лучше сжимать сразу на ходу.
Сервисы для Wordpress: Imagify, Smush, TinyPNG и прочие.
Как сделать в Photoshop: Сохранить для Web / выбрать уровень сжатия / Сохранить картинку в оптимально минимальном весе. - Настроить кэширование изображений. Большинство упускает эту историю, но многие картинки не являются большой динамикой. Например, вы загрузили карточку товара, где картинки не будут часто меняться. У вас есть контент и слайдер с фото товара, который вы можете кэшировать до года. Вам лучше забирать кэшированную версию, чем при каждом обращении пользователя загружать картинку. Кэшированная версия будет работать быстрее. При этом если нужно будет заменить изображение, то просто переименуйте картинку, дайте ей новый адрес. Она не будет в кэше и легко заменится. Таким образом, вы решите проблему с заменой контента.
- Lazy load для изображений. Важный момент: для большой картинки на первом экране лучше не использовать Lazy load, потому что нам важно, чтобы при ее загрузке не возникало никаких задержек. Поэтому Lazy load лучше использовать для остальных изображений.
- Внимание к SVG. Они кажутся очень легкими, но все имеют встроенные фильтры. Например, фильтр сглаживание. SVG может создавать нагрузку на процессор. Если у вас есть проблемная SVG, микроиконочка, она может вам нагружать процессор.
- Новая ветвь – это HTTP2. Если ее сравнивать с HTTP1, то раньше все запросы шли от сервера до браузера js к js, css к css, картинка к картинке, а в HTTP2 все это можно отправить одним запросом. Просто маленькая скорость на коннектах.
- Отложенная загрузка для скрытых изображений. Пример: есть баннер в ПК меню, который не используются на мобильной версии сайта. Если мы их не убрали с кода, и они прилетают оттуда, то лучше, чтобы на них стояла какая-то отложенная загрузка по скрытому изображению. Потому что в мобильной версии этого баннера априори нет, его никто не увидит.

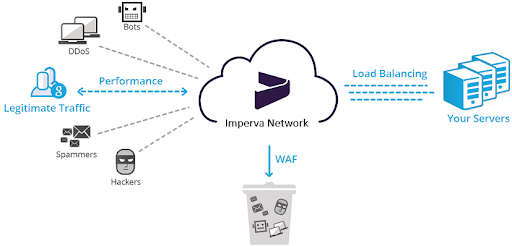
Ошибки на Imperva и сервисы IT-аналитики
Ошибка на Imperva может быть на клоудфлейере. Imperva – это CDN-сервис, у которого есть Web Application Firewall, защищающий сайт от DDoS, спама и т.д. В случае низкой скорости загрузки такой тест может помочь. Пример Фокстрота:, у нас появился мусорный скрипт, который создавал нагрузку на процессор в 2000 миллисекунд. Мы протестировали модуль Advanced Bot protection на Imperva. Модуль включили/выключили, определенные скрипты не потушились, начали сбоить и давать эту нагрузку. Поэтому на такие сервисы тоже обращайте внимание и в случае каких-то спорных моментов, тестите их модули. Нам, например, помог просто перезапуск модуля, чтобы все заработало.
Сервисы IT-аналитики, например, AppDynamics, Dynatrace и т.д. Благодаря этим сервисам можно чуть ли не до строчки кода разобраться, где и на каком моменте была проблема. Но загвоздка в том, что они дают большую нагрузку на TTFB и обычно под такие сервисы нужна отладка именно под ваш сайт. Например, у Фокстрота TTFB был в потолок просто за счет того, что мы прикрутили дополнительную утилиту сверху.
Скрипты
Скрипты опасны тем, что разработчики с ними ничего не могут сделать.
Варианты:
- если скрипт не нужен для отрисовки первого экрана, можем переместить в footer, ведь интересен первый экран.
- настроить асинхронную загрузку скриптов.
- проверить, чтобы на странице не было лишних скриптов. Например, у вас было много агентств, каждое из которых поставило свою аналитику, фейсбуковские пиксели. Они вам будут нагружать сайт просто набором шлака, который вы не используете.
- сжимать скрипты, используя любой Minify.
Если вы все сделали, а скрипт при этом все равно очень тяжелый, то пробуем оптимизировать сам код. Может быть такое, что ваш скрипт писали жители Индии. Например, есть точка А и точка В, а у вас еще перед А идет C, D, E. Поэтому может быть, что у вас не самый оптимальный путь, и он не так быстро работает, как хотелось бы.
Дальше можно оптимизировать запросы в базу данных. Но бывает так, что вы это сделали, но скрипт по-прежнему огромный. В случае Фоктрота так и и было, потому что система фильтрации тут очень тяжелая. Она большая и долго грузиться. У нас есть Elastic, который имеет кэшированные данные по сайту. Мы с Elastic забираем данные о фильтрах и отображаем на сайте. Почему мы можем использовать кэшированные данные? Потому что фильтр это не та история, которая ультрадинамична. Да, она меняется, что-то добавляется, но мы понимаем, что не каждую секунду нужно отдавать правильный фильтр. Мы можем сделать диапазон в 1 час, в 2 часа и использовать кэшированные данные для уменьшения нагрузки, например, по фильтру. Можно использовать кэш определенных элементов. Не обязательно кэшировать всю страницу, определенные элементы можно забирать с кэша и снижать нагрузку с сайта.
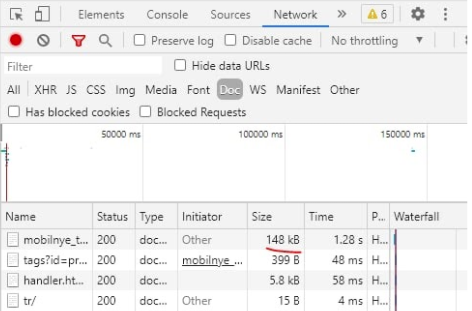
Включите сжатие
Самые популярные истории у нас это gzip, brotli, deflate. У gzip в IIS (это майкрософтовские серверы) у Фокстрота было неконтролируемое сжатие сайта. По нашим исследованиям вышло так, что в зависимости от нагрузки на сервер у нас менялся уровень сжатия. То есть чем меньше нагрузки, тем меньше он сжимал. Мы потом перешли на Brotli. Это немного другое инфраструктурное решение. Главный момент: долго не могли понять, почему одна и та же верстка на похожих инфраструктурах работает совершенно по-разному. Например, она у нас весила 148 кбайт при том, что нормальный вес 50-60 кбайт. Оказалось, что у нас включен был Brotli, но стояла минимальная компрессия в единичку. Поэтому нужно контролировать этот момент и, например, поставить 4 и тогда все заработает.
Коннект к файлам
Зачастую сайт можно ускорить с помощью этого метода. На коннект к каждому файлу, например, js, css, мы тратим какое-то время. Можно взять css и внедрить его в код. Этим мы уменьшаем коннект к файлу. Но если мы, таким образом, внедрим весь css, это будет какое-то ужасное полотно. Можно взять мелкие css и добавить непосредственно в код страницы, а большие оставить как есть. Таким образом выиграть какое-то время на коннектах. Бывает так, что и js ставят в код, чтобы выиграть время на скорости загрузки. Но в таком случае разработчикам потом не совсем удобно будет работать с сайтом и такой метод больше гиковский. Есть шанс на то, что будет и польза, и вред одновременно.
Расположение элементов в коде
Обычная проблема – не грузиться картинка на товаре и ничего невозможно с этим сделать.
Кейс Фокстрота: когда мы поднимали SEO-тексты повыше в коде, обнаружили, что разработчики карточки товара поменяли с фильтром по месту в коде. То есть сначала шел текст, потом фильтр и лишь затем карточки товара. Поскольку бот сканирует все сверху вниз, то у нас прилетело все кроме карточек товара, потому что они самые последние в коде. Как только мы поменяли все местами, карточки товара стали прилетать быстро. Если вам нужен первый экран, то смотрите на то, чтобы все элементы на нем были выше в коде.

Дополнительные рекомендации
- Не забываем про Preload шрифтов.
- Настройте показ всего текста во время загрузки веб-шрифтов.
- Любые статистические элементы лучше кэшировать.
- Проверяем скрипты внешних подрядчиков. Нам зачастую рассказывали, что это внешний скрипт, и мы с ним ничего не сможем сделать. Наш кейс: Скрипт Приватбанка создавал очень сильную нагрузку на сайт, мы с ними списались, объяснили ситуацию, и они нам рассказали, как работает их скрипт. Оказалось, что они собирают всевозможные данные за один запрос, но мы можем делать это за несколько запросов на нескольких страницах. Нас все это устроило и мы нагрузку раз в 10 снизили, просто пообщавшись с нашим подрядчиком.
- Если есть смещение макета, то не забывайте задавать высоту и ширину по рекомендациям Google.
Сессия вопросов-ответов
— Допустим, вы ничего не настроили. Вероятнее всего, у вас мигающие фильтры будут 404-ыми. У вас два варианта: либо вы парсите сайт с помощью Screaming Frog или Netpeak Spider и обнаруживаете кучу 404-ых, либо, если разбираетесь в логах, то идите в логи. Там вы тоже можете заметить эти 404. Например, вы зашли на сайт и обнаружили 10 тысяч 404-ых, потом начинаете разбираться, почему эти фильтры выдают этот тип ошибки. Здесь понадобиться помощь разработчика, который скажет, что этот фильтр 404, потому что по нему нет товаров, и он не может его вывести, потому что нет никакого свойства, за которое можно зацепиться. Дальше у вас есть выбор: либо вы с ними что-то делаете, либо вы их просто сливаете.
Наш кейс: если мы их сливаем, то мы можем потерять ссылочную массу, позиции. У нас пик сезона, допустим, по телевизорам, а фильтры Samsung, LG, Sony скачут. Если мы их потеряем в пик сезона, то можем потом эти позиции и не восстановить.
— Если скрывать именно с фильтра, то плюс для пользователя. Пользователь может начать фильтровать страницы, а вы будете ему выдавать «Извините, товар не найден» и так постоянно. Если пользователь так будет ходить по вашему фильтру, то конверсия, вероятнее всего, у вас будет неутешительная. Мы убираем ссылку в фильтр для того, чтобы пользователь, который находится на вашем сайте, работал с товаром, который в наличии. Нужно работать с конверсией. Нам не интересно показывать пользователю страничку, которой вообще нет. Допустим, я не могу показать ему iPhone 5, но у меня есть вариант показать ему iPhone 12. Тогда зачем нам этот раздутый фильтр с непонятной ерундой? По поводу трафика, почему мы их оставляем работать. Вариант такой: если человек зайдет с поиска, вы скажите ему, что извините, этого товара нет, и дадите какие-то рекомендации (родительская категория, категория + бренд). В этом случае это может сработать, а так вы удалили эти странички, и все — трафика нет.
— У нас при оптимизации картинок был рост. Наш кейс: когда мы были на старой системе, мы просто сделали компрессию изображений. Мы старались сжимать изображения до адекватных показателей, потому что не хотели, чтобы была какая-то лютая зернистость и т.д. Надо чтобы картинка оставалась привлекательной для пользователя. Но когда мы перешли на web, то получили инструмент, с помощью которого мы можем очень сильно сжимать картинки. Важный момент: когда мы переходили на web, то выяснилось, что не все старые iOS устройства поддерживают этот формат. Поэтому вам надо учитывать, что если устройство или браузер не поддерживает этот формат, то им нужно давать сжатый JPEG, а тем, кто поддерживает отдавать web.
Это полезно для скорости загрузки сайта. Но зайти с 50-го места на 1-е только за счет этого показателявы не сможете. Если у вас крупный сайт, и вы получали какую-то пессимизацию за счет скорости загрузки, то 1-2 позиции вы сможете выиграть. Например, если страничка была на 3 месте, а стала на 2-ом. На большом сайте это очень значительный эффект. Поэтому у нас был позитивный выход.
— Если одна и та же картинка находится на разных страничках, если разные языки, то, вероятнее всего, у вас прописан hreflang, то есть вы сразу говорите Google, где, какая версия. В принципе, если контент у вас совпадает, и вы просто подписываете его на разных языках, то для Google это будет работать, и не будет считаться дублем. У нас, например, карточка товара на украинской и на русской версии сайта. Они имеют одни и те же изображения, и подписи у них довольно похожие. Немного отличается только написанием некоторых слов. Мы же говорим Google, что это наши языковые версии, поэтому тут никаких проблем не будет.
— Это то, про что я уже говорил. Не все устройства поддерживают web. Оптимальный вариант – не уходить полностью от JPEG, а оставлять выбор. То есть тем устройствам, которые могут работать с web, отдавать WEBP, а остальным отдавать JPEG. Тогда вы не получите никаких просадок, только буз по скорости.
— Оно так и происходит. Когда товар потерял наличие, он ушел с сайта на отображение, он отрабатывает 200-м по прямому урлу и на нем пишется «Товар снят с производства» и т.д. Например, в Фокстроте десятки тысяч товаров и ежемесячная текучка просто огромна. Допустим, за год мы получили 100 тысяч архивных товаров, за 5 лет – 500 тысяч, и часть из них на протяжении большого срока будет бессылочная и бестрафиковая. Да, кнопочка «Нет в наличии» висит, но у нас есть вес сайта и краулинговый бюджет. Здесь дело даже не столько в весе, сколько в краулинговом бюджете. То есть бот ходит по огромнейшей архивной массе, которая нам просто не нужна. Нам лучше, чтобы он индексировал какие-то новые фильтры, товары. Зачем сканить товар, который снят с производства и по нему нет запроса? Поэтому мы это дело мониторим и чистим.
— У нас есть классный пример, не самый лучший вариант по реализации, но все же. ROZETKA пошла по формату, что их странички пагинации заточены под региональность. Если вы попереходите по страницам, то увидите там, например, холодильники Харьков, потом холодильники Одесса и т.д. С этим можно работать. У нас сейчас стоит Canonical. Он не всегда работает на 100%, но мы провели один тест. Мы постоянно закрывали noindex/nofollow, потому что нас очень сильно спамил Googlebot. Он бегал даже по таким урлам, где стояли noindex/nofollow, так как это запрещает ему индексировать страницу, но не запрещает посещать. И он нам валил сервера большим количеством обращений постранично. Вышла такая история, что когда мы закрывались noindex/nofollow, у нас хуже индексировались товары и фильтра. Поэтому мы ушли к Canonical-у. Сейчас, правда, рекомендации Google говорят «убирайте Canonical, оставляйте все как есть, мы сами разберемся», но пока у нас остается Canonical. Здесь такая холиварная история, но мне пока этот метод нравиться больше.
— Есть много сервисов проверки. Вы можете проверить HTTP2, у вас будут коннекты. Либо когда проверяете ответ сервера, посмотрите, например, по картинке, какой коннект с ней идет.
