На Первой SEO-конференции Collaborator Сергей Безбородов, CTO в JetOctopus, говорил о техническом СЕО для больших сайтов e-commerce. Это популярная ниша, которая сейчас в цене и широко используется. При этом не все в ней можно сделать ссылками.
Сергей — программист, при этом был постоянно связан с SEO, имеет опыт работы над агрегаторами. С 2016 года работает над развитием краулера JetOctopus.
Мы перекраулили больше 30 тысяч сайтов, проанализировали 50-60 миллиардов логов. Все о чем я буду говорить, мы видели: это делали наши клиенты.
Сегодня в докладе разберем 5 основных частей, которые пригодятся в техничке любого большого сайта. Мне бы очень хотелось рассказать о каких-нибудь фишках, которые можно сделать одной кнопкой, но мы будем говорить о банальных вещах, которые, вероятнее всего, вы знаете.
Идея доклада в том чтобы, не пересматривая видео, вы просто сохранили себе эту презентацию и когда надо смогли по ней пробежаться.
Кит 1. Анализ ситуации и сбор данных: что вообще происходит?
Часто, когда мы приходим на большой проект, где миллионы страниц, тонны трафика, возникает непонимание. Вы смотрите Google Search Console и Google Analytics, но как понять реальную картину? Потому что любой большой сайт — это сотни, а иногда и миллионы страниц, и где-то будет все хорошо, а где-то плохо.
Для мониторинга текущей ситуации рекомендую сделать одну табличку, куда нужно собрать данные из нескольких источников. Так как сайты большие, за редким исключением у вас будет четкая структура по урлам. Вы берете разбивку по директориям 1-го уровня и считаете, какое у вас количество страниц, процент страниц, открытых к индексации и т.д. В итоге получается таблица, глядя на которую вы с первого взгляда можете понять состояние сайта. То есть, какие у вас есть папки, категории, бренды, продуктовые страницы или разделы.
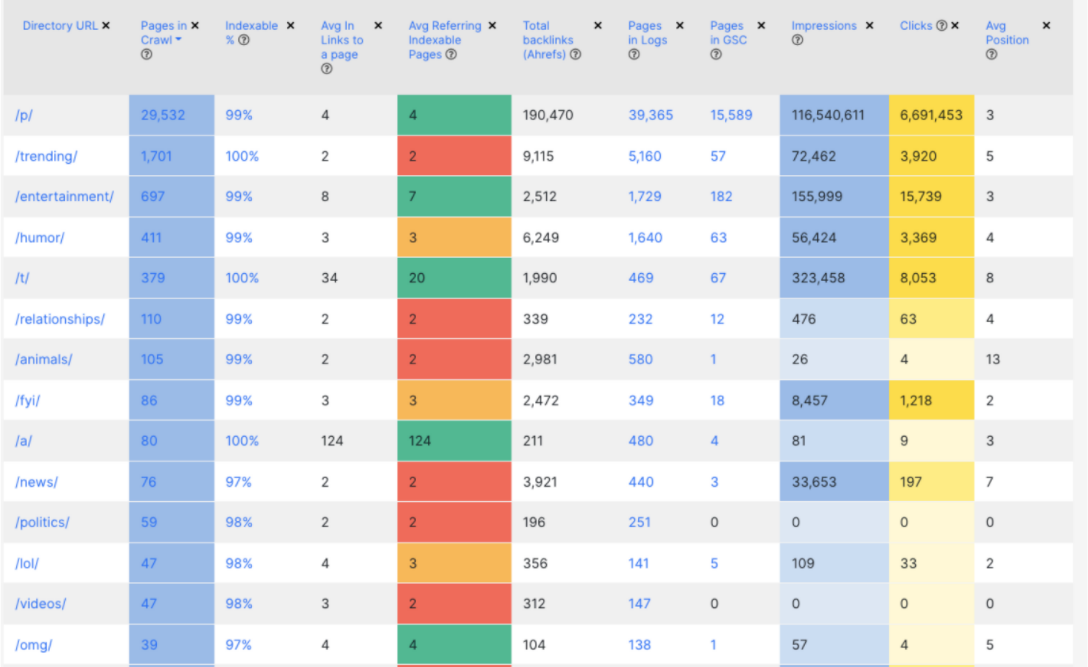
Мы такую же таблицу делаем в JetOctopus. Это очень удобно. У вас может быть миллион страниц, из которых к индексации будет открыто 100 тысяч, а impression они будут приносить 10 тысяч. По моему опыту, эта таблица — ваш первый шаг к техническому SEO. С ней вы с первого взгляда сможете понять, что у вас работает и реально приносит трафик, конверсии, продажи и деньги.
Кит 2. Техническое SEO
Следующий кит — это самая банальная и простая техничка. Я ее разбил на 2 части:
- техничка с Javascript,
- техничка без него.
Если у вас на сайте нет Javascript, я вас искренне поздравляю. Вам очень повезло, и у вас пока еще нет большого пласта проблем.
Самое первое, что мы начинаем смотреть в техничке — как мы управляем индексацией:
- как именно закрываются страницы meta, non canonical, robot.txt
- соответствует ли это вашим ожиданиям
Пример: вы прокраулили с помощью Screaming Frog 100 тысяч страниц. Больше у вас не получилось и закрываете страницы noindex. Но когда вы начинаете заходить дальше до каких-то далеких категорий оказывается, что canonical полез. Получается, что это не соответствует вашим ожиданиям. Поэтому то, как вы управляете индексацией, это стартовый этап.
Читайте подробнее, как проверить индексацию сайта в Google.
Следующее — отслеживаем дубли title, meta-тегов. Это есть в любом списке аудитов, но это не отменяет их важность. Meta-описание вторичный вопрос, но дубли title — это критическая проблема для открытых к индексации страниц. Их нужно фиксить и разбирать. Есть некоторые SEO-специалисты, которые думают, что дублируется ну и ладно, страница-то ранжируется. Это одна из самых простых вещей, которую вы можете поправить, и которая принесет вам результат.
Тут важно:
- какой % title задублирован,
- приносят ли эти страницы трафик;
- поменял ли гугл в них тайтлы;
- не можете сделать нормально описание — удалите тег в качестве эксперимента и проследите, что получится. Я не раз общался с клиентами, которые это проделывали. Во многих случаях это не ухудшало, а наоборот улучшало CTR и даже в какой-то части ранжирование.
Третий момент — страницы пагинации, которые есть на любом каталожнике. Кажется, что это просто пагинация: пользователь туда ходит, а боту туда ходить не надо. Но исторически так сложилось, что все закрывают страницы пагинации от индексации. И здесь у меня возникает такой вопрос: когда у вас с перелинковкой не все хорошо и товары находятся на второй, третьей странице и так до десятой, то, как боту найти ссылки на эти товары?
Всегда существует вера, что бот всесильный, и он все видит. Но он не сможет найти ссылки на товары со второй, третьей, десятой страницы, даже если туда ходит пользователь. Когда у вас таких товаров будут идти десятки и сотни тысяч, то вам априори нужно сделать нормальные ссылки.
Есть разные взгляды на то, что делать со страницами пагинации. Я всегда советую провести эксперимент. Не надо делать на всем сайте, сделайте на каких-то выборочных категориях. Например:
- есть non-canonical, уберите его,
- закрываете от индексации – уберите этот тег, попробуйте открыть к индексации.
Google уже весьма умный и хорошо это понимает.
Одним из самых явных факторов того, что возможно это стоит сделать: у вас страницы закрыты non-canonical, вы идете в Google Search Console и видите трафик на этих страницах. То есть Googlebot проигнорировал ваш non-canonical, он считает эти страницы полезными. Если они реально приносят трафик и отвечают на запрос пользователя с поиска, то это нормально. Просто посмотрите на страницы пагинации с другой стороны.
Техничка. Custom Extraction
Небольшое отступление, потому что это понадобиться в следующем слайде. Мы стандартно краулим страницу, сам краулер извлекает тайтл, мета, ссылки и т.д.
Custom Extraction – это нереально крутой инструмент. Я считаю, что каждый сеошник должен иметь его в своем арсенале. Его суть состоит в том, что вы со страницы вытягиваете какие-то данные.
Допустим, есть страница каталога. Что мы можем взять:
- количество товаров,
- количество фильтров,
- наличие блока перелинковки,
- размер SEO-текста, если он там есть, количество символов в нем.
С помощью этой информации вы в дальнейшем сможете эффективно очистить мусор, пустые страницы и шлак. Рекомендую использовать JetOctopus, Screaming Frog, Sitebulb.
Читайте подробный гайд по работе с Screaming Frog Seo Spider.
Техничка — без JavaScript. Todo
Плавно переходим к тому, что мы можем сделать с Custom Extraction:
- Найти пустые страницы каталогов. Понятно, что сайты разные, логика системы генерации страниц у всех тоже разная. Но это не редкость, когда у вас 30-40% каталогов пустые. То есть на них когда-то были айтомсы, но сейчас их нет. Это нормально для агрегаторов, интернет-магазинов. Очень важно понимать их объем, чтобы в дальнейшем предпринимать какие-либо действия: либо закрывать, либо пытаться наполнить. Можно ничего не делать, если вы спарсили и увидели, что пустых каталогов у вас только 5%. В этом случае лучше заняться чем-то более приоритетным.
- Найти товары без описания: определить объем этой проблемы и насколько вы можете доработать, улучшить это описание либо его спарсить, сгенерировать.
- Определить блоки перелинковки и количество ссылок в них. Всегда живите с мыслью, что где-то отвалился блок с перелинковкой. Вы должны с этой мыслью засыпать и просыпаться. Я не просто пугаю, это опыт. Когда у вас что-то генерируется по определенным условиям, формула сломалась. И у вас нет перелинковки. Это можно и нужно делать с помощью Custom Extraction. Просто мониторьте, что у вас все на месте, есть ссылки в том количестве, которое вы ожидаете.
Техничка — JavaScript
JavaScript – это большая проблема. Ключевой момент в том, что у нас html страница — это документ, и браузер взаимодействует с ним как с документом, он его читает. У вас этот документ может не полностью загрузиться. HTML изначально разрабатывался с учетом того, что он может работать на медленном интернете. То есть полстраницы прогрузилось, но она уже работает, и вы с ней можете взаимодействовать.
С JavaScript это, к сожалению, ни так. С JavaScript оно либо работает, либо нет. JavaScript в этом плане бинарный. Здесь нет какой-то золотой середины. Поэтому у нас теперь добавляется еще одна задача – следить, чтобы все не «поломалось» именно с точки зрения SЕО. Например, страница не может быть нормально отренжерена Googlebot-ом, или он не видит весь контент, который есть на странице.
Я рекомендую всем начать углубляться в JavaScript. На Западе про это очень активно говорят уже года два. Поэтому самоучитель JavaScript открыть определенно стоит хотя бы для того, чтобы понимать, что там что значит, потому что вы с ним рано или поздно столкнетесь.
Техничка — JavaScript. Todo
Что делать:
- Проверить наличие JS ошибок: открыть «сайт — developer tools» в Chrome или Firefox и смотрим то, что отмечено красным. По ходу вы уже начнете понимать, что одно дело, когда у вас там фейсбучный скрипт не подгрузился, другое дело, когда вы там видите Fatal error и прочее в таком стиле.
- Определить наличие критических JS ошибок. Это уже немного сложнее. Вы должны походить по сайту, по основным страницам. Походить с AdBlock и без. Или с какими-то популярными плагинами, потому что они тоже могут «ломать» ваш JS код.
Как понять критическая ошибка или нет? Если полстраницы не отображается, то тут все понятно. Но вам нужно понимать природу этих ошибок, чтобы в дальнейшем проще на это реагировать. Поэтому лучше всего сходить к программистам, чтобы они вам объяснили, что из этого критично, а что нет. - Промониторить правильность рендеринга страницы под разными User-Agent. Уже все в курсе, что для больших сайтов нужен Server-Side Rendering. Это весьма нетривиальная техническая задача плюс недешевая. Существуют определенные оптимизации, когда программисты делают так, что ботам мы отдаем страницу с SSR (уже отрежеренный html документ), а пользователям отдается на Client-Side Rendering. Точно также происходит, когда Googlebot приходит с реальных айпишников или нет. Все делают по-разному в зависимости от своих обстоятельств. Ваша задача тоже четко знать эти условия и проверять их. То есть ходите с телефонов, под разными User-Agent и проверяете, что он работает. Я уверен, что в большом интернет-магазине есть целая армия тестеров, но SEO – это вы, и с вас потом будет спрос.
- Отследить наличие базовых тегов: title, meta, meta=robots в HTML. Они должны быть в сыром HTML, до исполнения JS. Даже если у вас выпадает Client-Side Rendering, даже если не реализован SSR. Вы открываете через View source, а не Developer Tools, потому что он отображает HTML как дом дерева уже после исполнения JavaScript. Эти теги должны быть в сыром HTML, чтобы вам там не говорили программисты. Этот пункт даже не обсуждается.
- Наличие необходимого контента и ссылок. В интернет-магазинах страницы зачастую большие, всегда максимально быстро нужно отобразить первый экран. И все блоки перелинковки, которые у вас есть, должны быть после загрузки страницы, даже при Client-Side Rendering. Здесь всегда возникает нюанс, что есть Client-Side Rendering. Этот блок прогружается только после того, как пользователь к нему подкручивается. Важный нюанс: Googlebot и в Desktop, и в Mobile рендерит страницу с очень большим по высоте экраном. Если я сижу за монитором, у которого высота пикселей 800, у Googlebot в Desktop версии будет порядка 9 тысяч пикселей, а для Mobile – больше 12 тысяч пикселей. Представьте, что ваша страница открывается на телефоне, высота которого равна 10 iPhone. Вы это можете проэмулировать. У нас в JetOctopus есть режим эмуляции. Или просто поиграйтесь с настройками, чтобы все блоки, которые прогружаются в Lazy loading, корректно отрабатывались в Viewport браузера. Это ключевой момент для того, чтобы ваша перелинковка и контент воспринимались нормально.
- Изменение title, meta после исполнения JavaScript. Это весьма распространенный момент, когда в сыром HTML у нас тайтл будет «Collaborator.pro», а после исполнения JavaScript — «Collaborator.pro Биржа прямой рекламы». Google будет воспринимать у вас нормальный тайтл и это в принципе не проблема, но зачем делать ненормально, когда сразу можно сделать нормально. Просто этот момент нужно будет пофиксить, потому что рано или поздно это вылезет. В Octopus у нас есть по этому отдельный отчет. Я специально пересматривал его, и у больших сайтов, которые с Client-Side Rendering, оно может вываливаться на 5-10% страниц. Поэтому тут все не посмотришь глазами, лучше использовать инструменты, чтобы это найти. В Screaming Frog это тоже есть.
Если вы счастливый обладатель Server-Side Rendering, то контент в SSR и JS версии должен быть одинаковым. Сверяйте его, точно также смотрите инструментами.
Кит 3. Краулинговый бюджет
Я очень рад, что краулинговый бюджет становится заезженным словом. Все уже знают, что это такое и как его увеличить.
Что делать с краулинговым бюджетом, если у вас большой сайт?
Здесь есть один нюанс, который все знают, но не все хотят в это верить: Googlebot не краулит весь сайт.
Когда у вас сайт от 100 тысяч страниц, он его не будет краулить весь по ненадобности. Googlebot это не краулер, как Jet Octopus, которому вы платите деньги за то, чтобы мы прошли весь сайт. Googlebot хочет отвечать на вопросы пользователей. Если только часть страниц вашего сайта отвечает на вопросы пользователей, а все остальное мусор, то этот мусор ему не нужен. Поэтому у вас сайт априори не скраулен весь, и в некотором контексте это даже нормально.
Единственный нормальный способ работать с краулинговым бюджетом – это логи. Google сделал великолепный инструмент по Crawl Stats. Но краулинговый бюджет — это не только визиты бота, а также страницы, которые посещает боты и то, как часто он на них ходит.
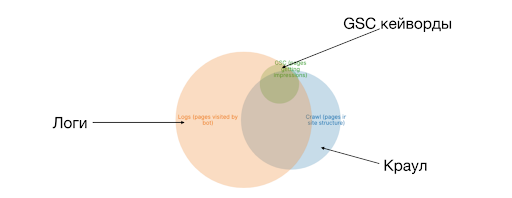
Один из способов графической интерпретации краулингового бюджета — это совместить его с краулом. Это называется круги Эллера. У нас есть три круга – логи, Crawl, GSC. Туда можно добавить ссылки с Ahrefs. На скрине выше вы видите пересечение логов (краулингового бюджета) с краулом. Это то, насколько эффективно используется ваш краулинговый бюджет. Эффективно в контексте того, что это в структуре сайта. Допустим, вы нашли каталоги, которые пустые, т.е. тысяч 20 страниц, которые вам не нужны, и вы хотите их удалить или закрыть от индексации. Вы убрали на них ссылки: ни пользователь, ни краулер не может найти эти 20 тысяч страниц. Но бот про них знает, помнит и будет по ним ходить. Область, которая находится вне краула, по ней ходит бот. И вы не знаете нормальные там страницы или нет.
Краулинговый бюджет. Todo
Ключевые метрики при работе с краулинговым бюджетом:
- какой % сайта у вас посещается ботом. Именно процент сайта из структуры. Если сайт 100 тысяч страниц, а бот посещает 200 тысяч. Вы думаете, что это огонь, удвоили краулинговый бюджет в 7 раз, но не забывайте о структуре сайта. 100 тысяч – это те страницы, которые вы создали, а оставшиеся 100 тысяч – нужно разбираться, что это.
- какие директории и разделы посещаются ботом. Есть разделы которые более важные и денежные. Есть то, что просто набивается контентом и т.д.
- сколько страниц бот краулит вне структуры. Разбивка по директориям или вашим сущностям – это следующий этап для понимания и распределения краулингового бюджета. И то, что бот краулит вне структуры, особенно на сайтах с историей (от 5 лет и старше), это будет очень большой объем страниц. Поэтому вам нужно на них смотреть.
- % бюджета, уходящий на мусор, баги. Совместили одни страницы с другими, выгрузили и просто пробегаете по этим страницам глазами, т.е. мусор это или нет. Скорее всего, там будут какие-то паттерны, директории. Если их все равно остается много, например, у вас осталось тысяч 70 непонятных страниц, то вы берете эти страницы, закидываете в краулер, настраиваете Custom Extraction по количеству товаров, наличие контента и т.д.
- % бюджета, который расходуется оптимально. Это будет одним из наших KPI, говорящий о том, как вы его оптимизируете, что с ним происходит.
Краулинговый бюджет — управление
Как управлять краулинговым бюджетом — тезисы Сергея Безбородова:
- meta robots=noindex не помогает для краулингового бюджета. Ведь чтобы боту увидеть meta тег, ему нужно скраулить страницу. Боту нужно периодически проверять страницу, чтобы понимать, что вы его не убрали.
- non-canonical страницы убивают краулинговый бюджет. На мой взгляд, единственный правильный способ использования тега canonical, это использовать его как self-canonical. Это когда у вас простой канонический урл и тег canonical равен этому урлу. Это позволяет защититься от каких-то трекинговых хвостов, которые любят ставить аналитики. Худшее решение закрыть страницы фильтров + сортировки в non-canonical.
- robots.txt работает. Googlebot реально соблюдает. Если это не так - проверьте все инструментами, а не глазами.
Кит 4. Перелинковка
Все о ней говорят, но никто не делает.
Простой постулат перелинковки гласит: важные страницы сайта должны иметь больше входящих внутренних ссылок.
Звучит максимально просто. Но когда дело доходит до практической реализации это очень сложно технически.
Как делать внутреннюю перелинковку на сайте, мы писали в материале.
Как понять, что происходит с перелинковкой на сайте: с помощью краулинга. У вас есть URL страницы и количество входящих ссылок на эту страницу. Вы загоняете эти данные в Excel (в Octopus для этого есть встроенный инструмент) и группируете:
- сколько страниц вообще не имеет ссылок (они только в Sitemaps),
- сколько имеет 1 ссылку,
- сколько от 1 до 10.
Таким образом, вы получаете группы страниц.
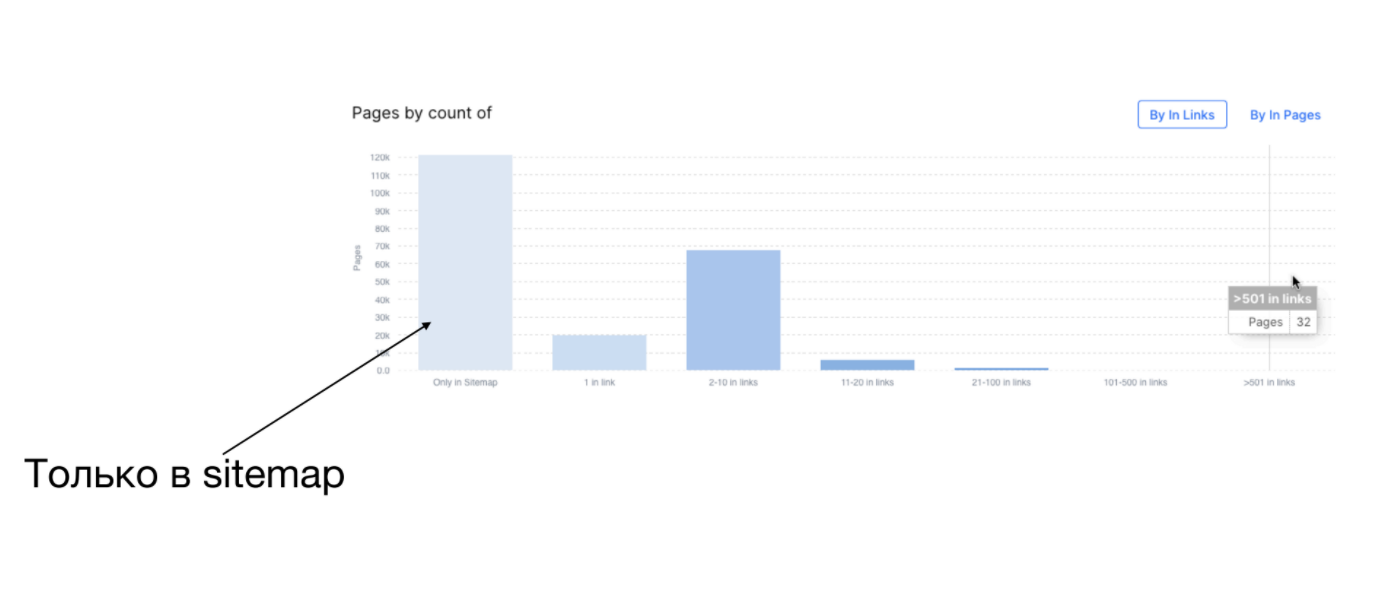
На скрине выше видно, что на большом сайте хорошо залинковано только 32 страницы, а остальные имеют от 1 до 10 ссылок.
Перелинковка – это важный фактор для краулингового бюджета. Чем больше ссылок ведет на страницу, тем она считается важнее и возрастает вероятность того, что Googlebot придет на нее. Но это не единственный фактор. Не думайте, что если вы наставите на страницу кучу линков, то краулинговый бюджет сразу улучшиться. Такой график — это ваш стартовый этап для того, чтобы понять, что у вас происходит с перелинковкой.
Из таблицы видно, как у вас распределяются внутренние ссылки и насколько у вас есть перекосы.
В 2019 году на Коллабораторе был вебинар по перелинковке, он все также актуален, и я его рекомендую пересмотреть.
Ключевой момент в том, что вы делаете перелинковку не для ботов, а для человека. Поставьте себя на место пользователя. Перелинковка, которая реально работает, должна быть видима. Ее должен видеть пользователь на основном экране. Серый текст внизу страницы не работает.
Перелинковка. Todo
Чек-лист по перелинковке:
- Мониторить с помощью Custom Extraction наличие блоков перелинковки на каталогах, товарных страницах.
- Проверять наличие блоков перелинковки в raw HTML. Она должна быть в HTML сразу, не после прокрутки страницы, не после клика в верхний левый угол в нечетную секунду😃
- Анализировать перелинковку в разрезе разделов/каталогов сайта. Ведь любой большой сайт неоднороден. И если все хорошо в одном каталоге, не значит, что аналогичная ситуация в других метсах.
- Проверять min, max, median по количеству внутренних ссылок на каталоги. Это вам позволит приоритезировать действия. У вас могут быть какие-то плохо залинкованные разделы, но нельзя все сделать идеально.
Кит 5. Google Search Console Keywords
В Google Search Console есть Keywords. Хотя GSC в целом не самый удобный и легкий инструмент, GSC Keywords – это очень хороший тул по трем причинам:
- дает динамику по времени. Вы можете делать выборку по-недельно, по-дневно.
- тут теплые данные. Это ваши данные, которые реально ранжировались. Были получены импрешены, клики.
- с помощью API вы можете легко работать с этим.
Читайте ответы на актуальные вопросы по работе с Google Search Console в нашей Базе Знаний.
GSC Keywords. Todo
В GSC очень большое пространство для оптимизации.
Что можно проанализировать с помощью GSC Keywords:
- Какие страницы имеют impressions и clicks. Потому что у нас миллион страниц и всегда есть внутреннее ощущение, что половина из них нам должна приносить трафик. Вы будете очень удивлены тому, сколько реально страниц вам приносит трафик.
- Какой объем запросов канибализирован. Когда у вас за один и тот же Keyword конкурируют разные страницы. Это могут быть дубли, какие-то смежные страницы, которые очень похожи по интенту. На это число нужно смотреть с осторожностью. В плане того, что вы должны отсекать запросы на региональность. Потому что «купить iPhone в Киеве» это одна страница, а в «купить iPhone в Одессе» — другая.
- Какие кейворды мигающие – которые ранжируются не весь период времени. То есть один месяц один, в следующий – другой, и они между собой начинают мигать. Это довольно частая проблема, на которую стоит обратить внимание.
- Какие позиции приносят вам трафик. В зависимости от ниши трафик может быть или на 1 позиции или топ 3, или вы можете работать до топ 10.
- Где PPC перебивает SEO. PPC это тоже классные ребята, и может легко убить вам CTR. Вы находитесь на топ 1, топ 3, а CTR у вас нет. Все потому, что там есть реклама. Такое бывает для низкочастотных запросов. Возможно, надо провести эксперимент и просто их отключить.
Кого смотреть, читать, учиться в SEO: рекомендации Сергея Безбородова
Здесь список великолепных специалистов, с которыми я очень давно знаком и рекомендую везде на них подписаться и читать:
- курсы Игоря Баньковского (его доклад о профессиональной внутренней оптимизации больших сайтов читайте в Блоге Коллаборатора)
- Влад Моргун
- Стас Дашевский
- Гена Сивашов
В блоге Коллаборатора ранее делали подборку книг для SEO-специалиста, а также собрали базу SEO-школ, где можно обучаться оптимизации.
Выводы
Не обязательно изобретать «ракету» или использовать что-то сложное, начинать лучше всегда с простого.
SEO больших сайтов — это много данных. Excel виснет , CSV всегда большая. Поэтому если вы используете Linux, то освойте пару консольных команд. Это очень поможет в работе.
Эффект на больших сайтах всегда ощутимее. Все, что вы делаете на больших сайтах, будет заметнее. Эффект от внедрений в перелинковке, контенте на большом объеме страниц будет всегда ощутимее. Или вы его вообще не увидите.
Сессия вопросов-ответов
— Под 300 миллионов, поэтому справится.
— Это исследование должны сделать вы на своем сайте. У многих наших клиентов были разные результаты. У кого-то становилось лучше, у кого-то хуже. Это не значит, что вам надо сразу что-то открывать или закрывать. У Стаса Пономаря был доклад по тому, как проводить эксперименты. Есть экспериментальная группа, есть контрольная. Берете несколько пачек похожих страниц, на одной делаете, на другой нет, и смотрите разницу. Эта разница может проявиться в том, как поменялся краулинговый бюджет на этой группе страниц. По GSC вы можете посмотреть изменение impressions и clicks. И это будет вместо тысячи слов. Просто попробуйте конкретно на своем сайте.
— Раньше я любил Last-Modified, сейчас не вижу от него особого эффекта. К тому же Last-Modified должен работать именно для HTML страницы. Там прописано как алгоритм, что Google приходит с отдельным заголовком – Last-Modified дата, которая там была. Идея в том, что Google не будет разбирать страницу, но с этим имеет смысл поэкспериментировать, если у вас очень большой сайт. Хотя бы за 5 миллионов страниц. Если меньше, то лучше не заморачиваться.
— Первым делом надо идти к программистам и спрашивать, что они сделали. Они, как обычно, скажут ничего. Поэтому вам нужно откатывать изменения от этого ничего. Был прикольный кейс у одного из больших сайтов: админ просто поменял айпишник из той же подсети, в результате чего краулинговый бюджет обвалился с десятков миллионов в ноль. В этом кейсе помогло то, что они пинганули Мюллера, который сказал, что напишите на той странице обращение в форму. Google у себя что-то изменил и краулинговый бюджет вернулся. Обвал краулиногового бюджета – это либо попадание сайта под фильтры, либо результат действий кого-то из команды, либо что-то «отвалилось». Здесь тоже нужно разбираться и искать.
— Никакой. Я становлюсь JS-ненавистником, потому что он добавил мне немало седых волос😃 Мы год назад сделали JS-краулер. Все сделали по мануалу, все настроили. Исходного кода там было очень мало. После того как пользователи начали что-то краулить, теперь у нас JS-кода да еще и с костылями море. Если вы все-таки хотите делать на JS-фреймворк, то лучший JS-фреймворк – это тот, для которого у вас есть качественные программисты. Не джуны, которые не смогут это нормально сделать. Как прокраулить JS-сайт? Любым краулером.
— Потому что есть нюансы реализации Client-Side Rendering. В чем проблема JS-сайтов? Раньше было: загрузили страницу и сразу же с ней работаем. С JS-сайтами так не бывает. После того как загрузился базовый HTML, нужно ждать пока фреймворк загрузится, пока мы сделаем куда-то 10 запросов и т.д. А это время, 10-20-30 секунд, никто не знает, сколько у Google тайм-аут стоит. Мы у себя прописали константу в 10 секунд. Я думал, что если за 10 секунд не загрузиться, то это очень долго. В итоге теперь у нас это время меняемое. Некоторые это используют даже с 60 секундами, т.е. люди считают, что 60 секунд грузится странице это нормально. У всех разные взгляды на индексацию страниц, но чем быстрее, тем лучше. Возможно, из-за этого вы не можете прокраулить в Screaming Frog.
— Никак. Не возлагайте больших надежд на Sitemaps. В Sitemaps хорошо добавлять, когда у вас , например, новые товары, которые только залили. Sitemaps должен быть маленьким и худеньким. Если вы хотите весь сайт загнать в Sitemaps, и думаете, что все будет краулиться, то нет, так не будет. Используйте Sitemaps больше в плане – удаленные/обновленные страницы, чтобы бот их быстрее переобошел. Потому что у Google очень много эвристик касаемого того, как их перезагружать.