Іноді легко піддатися спокусі й повністю довірити аналіз сайту алгоритмам штучного інтелекту. Проте автоматичні звіти часто пропускають контекст, який бачить лише досвідчений спеціаліст під час системного аудиту.
Я підготувала цю статтю, щоб допомогти вам налаштувати власний процес самостійної перевірки, який не забиратиме весь вільний час. Розберемо, як поєднати перевірену роками базу з новими методами обробки даних: де працювати руками, а де делегувати AI.
Навіщо проводити аудити вручну, якщо є ШІ
У моменти, коли ШІ виконує багато рутинних задач та здатний автоматизувати майже кожен процес, SEO-спеціалістам (як новачкам, так і з досвідом) не варто забувати про базу, тобто аудити. Поєднання автоматичного аудиту з ручним дасть змогу отримати кращий результат.
Якщо трохи заморочитися, можна звести всі дані з різних джерел у декілька дашбордів. Але коли немає такої можливості або ж треба самостійно налаштувати такий дашборд, не зайвими стануть приклади, що і як варто перевіряти.
Темплейтів, чеклістів, гайдів можна знайти безліч. За роки роботи я вже не раз змінювала як формат аудиту, так і краулери для збору даних. Кожен обирає саме ту форму, що найбільше підходить для певного сайту в конкретний момент.
У статті я наведу приклади чеклістів, що підходять мені наразі. База завжди одна — що ми перевіряємо. І тут зміни, якщо і з'являються, то вже рідше та зазвичай саме з розвитком і змінами самої пошукової системи.
Структура SEO-аудиту: огляд основних блоків
Перед тим як заглиблюватись у деталі — короткий огляд усієї структури. Це допоможе зорієнтуватись і одразу зрозуміти, що і як перевіряємо.
8 основних факторів ранжування (Google) — база, яка практично не змінюється з часом:
|
Фактор |
Що впливає |
Як перевіряємо |
|
Технічне SEO |
Індексування, швидкість, crawlability, структура сайту |
Screaming Frog, GSC, PageSpeed Insights |
|
Контент |
Релевантність, глибина, відповідність інтенту, E-E-A-T |
GSC, Screaming Frog, ручний аналіз |
| Беклінки |
Авторитетність домену, трастовість профілю, анкорний текст |
Ahrefs, SEMrush, GSC |
|
Keyword Optimization |
Відповідність запитам користувачів, щільність і розміщення ключів |
GSC, Ahrefs, ручний аналіз |
|
User Experience |
Поведінкові сигнали, bounce rate, час на сторінці, CWV |
GA4, GSC, PageSpeed Insights |
|
Schema Markup |
Rich snippets у видачі, видимість в AIO та LLM |
Google Rich Results Test, Screaming Frog |
|
Social Signals |
Непрямий вплив через трафік і впізнаваність бренду |
GA4, ручний моніторинг |
|
Brand Signals |
Довіра до бренду, брендові запити, згадки в мережі |
GSC, Ahrefs, Google Alerts, LLM checkers |
Саме на них націлені наші аудити та стратегії. Далі розберемо кожен детально, але спершу трохи про підготовку.
Benchmarking: з чого починається будь-який аудит
Перш ніж щось «лагодити», потрібен знімок поточного стану. Інакше неможливо виміряти ефект від змін і відрізнити реальну проблему від сезонного коливання. Це точка відліку для всього іншого аудиту.
Що перевіряємо:
- органічний трафік за 6–12–16 місяців: ріст, плато, просідання, сезонка;
- топові лендінги за трафіком і продажами;
- позиції топових ключів за трафіком чи продажами;
- сторінки, що втрачають кліки або impressions;
- зміни в трафіку після апдейтів алгоритму (дізнатися, коли був алгоритм, можна тут).
🚩На що звертаємо увагу:
- незрозумілі та раптові просідання трафіку, що не повʼязані із сезоном;
- сторінки, що раніше давали трафік або ж продажі, зараз втрачають позиції / ключі / гроші;
- сторінки, що ніколи не набирають трафік;
- топові лендінги за трафіком і топові за продажами — різні сторінки, і розрив збільшується;
- сторінки, що раніше давали стабільний трафік, різко втратили impressions, але позиції ніби не змінились.
Інструменти: Google Analytics, Google Search Console, Ahrefs та аналоги (останні допоможуть визначити сезон за конкурентами, якщо у вас немає цих даних).
Що можна передати ШІ:
- звести дані з різних джерел, побудувати графіки, знайти аномалії;
- кластеризувати сторінки за темами, знайти канібалізацію;
- short executive summary тощо.
Prompt:
Analyze this GA4/GSC landing page export. Highlight significant traffic drops or gains, flag underperforming pages, identify correlations with algorithm updates.
Важливо: що більше даних хочете отримати, то детальніше має бути прописаний промпт. Для швидкої перевірки можна використати будь-яку звичну модель. Для sensitive даних краще обрати Claude. Для технічних задач та обчислень, що потребують коду, можете звернутися до Claude Code.
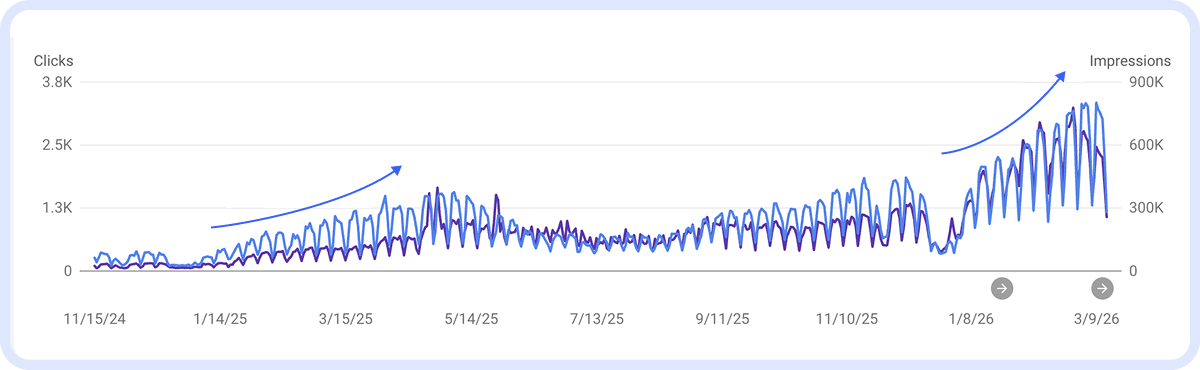
Примітка. Сезонні коливання виглядають саме так: clicks і impressions ростуть і падають синхронно, повторюючи один і той же патерн рік за роком. Загальний тренд при цьому — вгору:
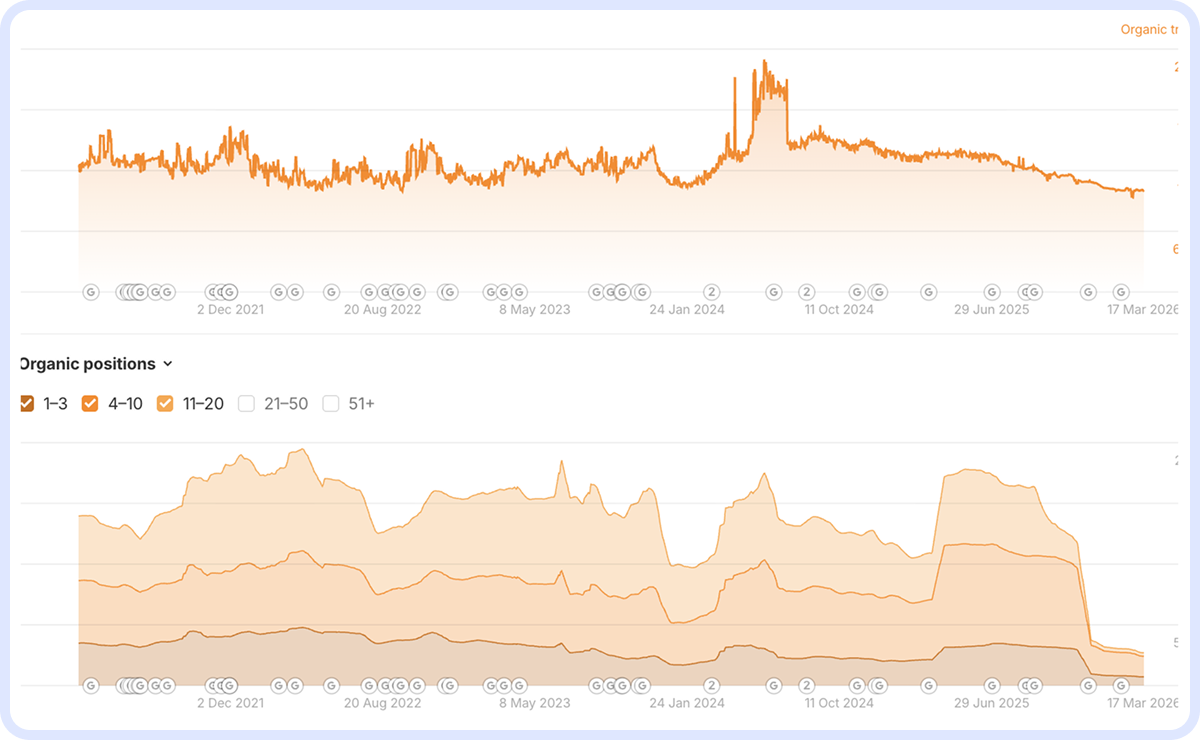
Різке падіння після стабільного плато — класичний слід алгоритмічного апдейту. На відміну від сезонки, трафік не відновлюється після спаду. Те саме падіння в розрізі позицій: частка ключів у топ 1–3 і 4–10 різко скорочується, сторінки «провалюються» у нижні діапазони або зникають з видачі повністю:
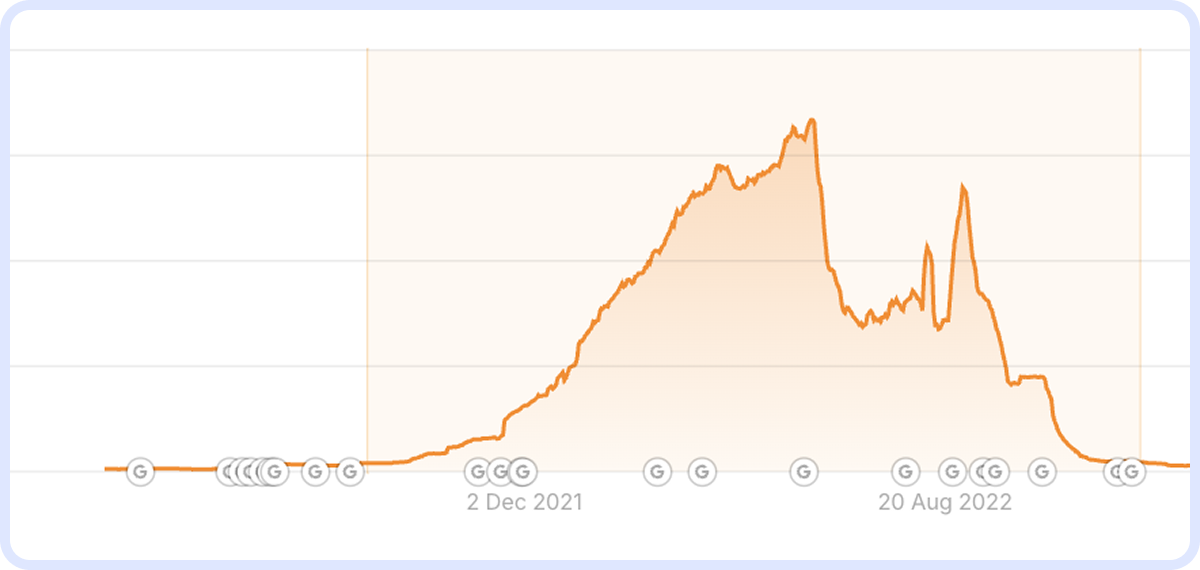
Так виглядають санкції: різкий пік — і потім обвал практично до нуля. Відновлення після санкцій — окрема і набагато складніша робота, ніж після апдейту, яка не завжди закінчується успіхом. На скриншоті нижче — приклад санкцій за неунікальний контент:
Технічне SEO — основа основ
Якщо бот не може зайти на сторінку, її не можна проіндексувати — решта не має значення. Технічний блок об'єднує 4 структурні елементи: сканування та індексування, структура сайту та внутрішнє перелінкування, метадані та структуровані дані, Core Web Vitals і швидкість. Також важливими є мобільність і безпека. Далі — детально по кожному з них.
Crawlability & Indexing
Щоб вас знайшов користувач, першим це має зробити саме бот: зайти на сторінку, передивитися вміст і додати до індексу. Лише тоді сторінка може ранжуватись. Одна помилка в robots.txt або noindex-тег може «вимкнути» цілий розділ сайту з результатів пошуку.
Що перевіряємо:
- robots.txt — чи не заблоковані важливі розділи, wildcard-правила, crawl-delay;
- Sitemap.xml — наявність, коректність URL, відповідність канонікам, відсутність редиректів і 404;
- Meta robots / X-Robots-Tag — noindex / nofollow на важливих сторінках;
- Canonical-теги — self-referencing, змішані сигнали, конфлікти;
- GSC Pages — «Crawled but not indexed», «Discovered but not indexed», soft 404, серверні помилки;
- статус-коди: 4xx, 5xx, нестабільні сторінки (Log Files + GSC Crawl Stat);
- Redirect-ланцюжки та петлі — мінімізувати кількість кроків;
- який бот аналізує сайт і які сторінки відвідує найчастіше (Log Files);
- який відсоток логів витрачається на сторінки, закриті для індексування;
- сторінки, які бот не міг обробити тривалий час;
- Render-blocking: чи не заблоковані важливі CSS/JS/images у robots.txt.
🚩На що звернути увагу:
- більше 20% сторінок у GSC зі статусом «Crawled but not indexed»;
- у Sitemap є URL, які повертають 404 або редиректи — бот витрачає бюджет на мертві адреси;
- значна частина краулінгового бюджету витрачається на сторінки, закриті для індексування.
Інструменти: Screaming Frog, GSC (Pages, Crawl stats), SEMrush / Ahrefs Site Audit, Sitebulb, Log File Analyser.
Що можна передати ШІ:
- завантажити повний crawl export (URL, status code, indexability, canonical, meta robots, inlinks) → знайти заблоковані важливі сторінки та orphan-сторінки;
- відфільтрувати запити від Googlebot, порахувати краулінговий бюджет і знайти «сміттєві» сторінки, які скануються занадто часто (за допомогою Claude code);
- порівняти sitemap vs індексовані сторінки, знайти розбіжності у великих таблицях.
Prompt:
Analyze this crawl export. List URLs blocked by robots.txt, tagged noindex, or with 4xx/5xx errors. Identify orphaned pages and inconsistencies between sitemap and indexed pages.
Примітка. В Google Search Console можна перевірити, на які сторінки та коди бот витрачає час:
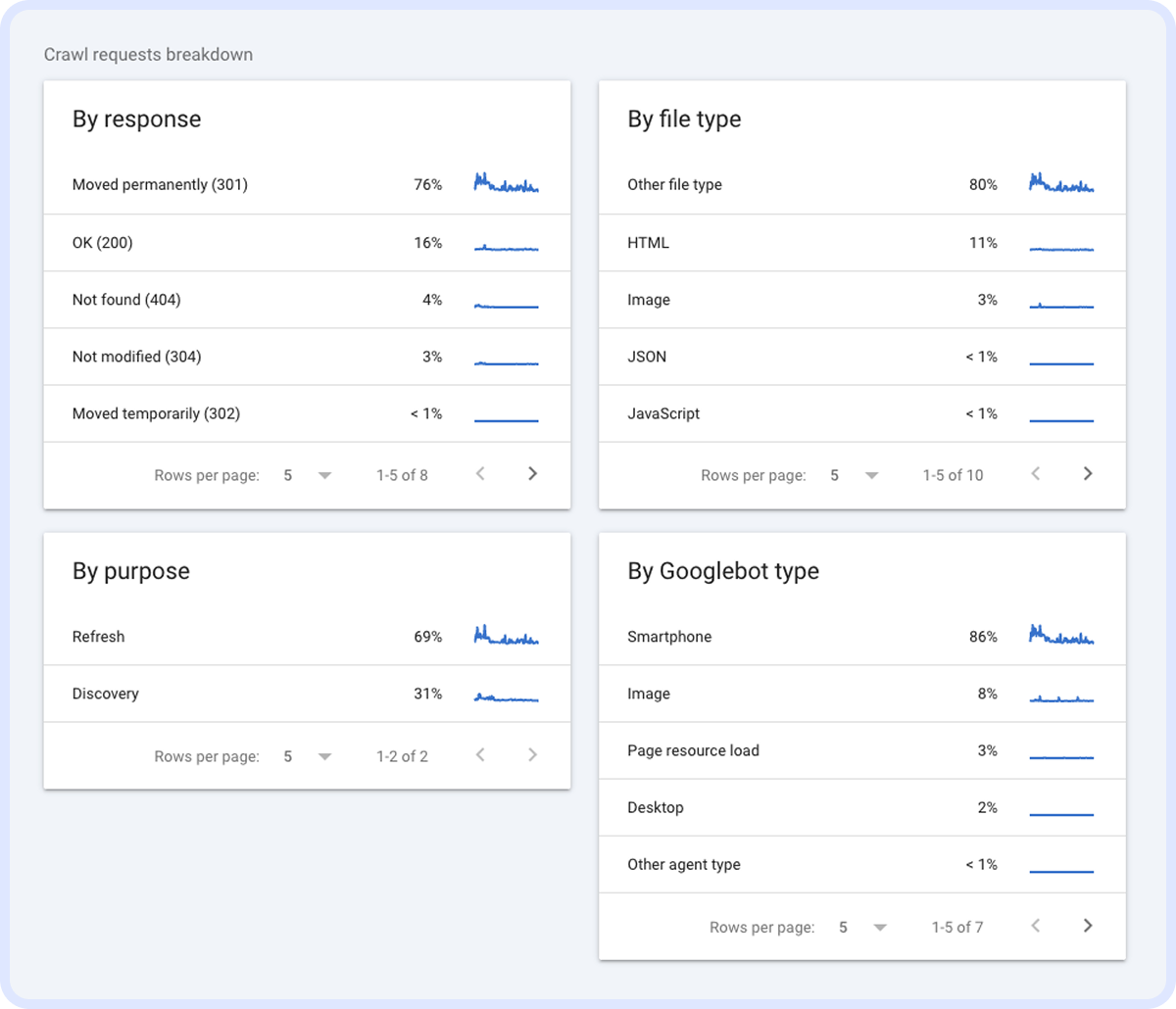
Тут — яка динаміка індексу/неіндексу:
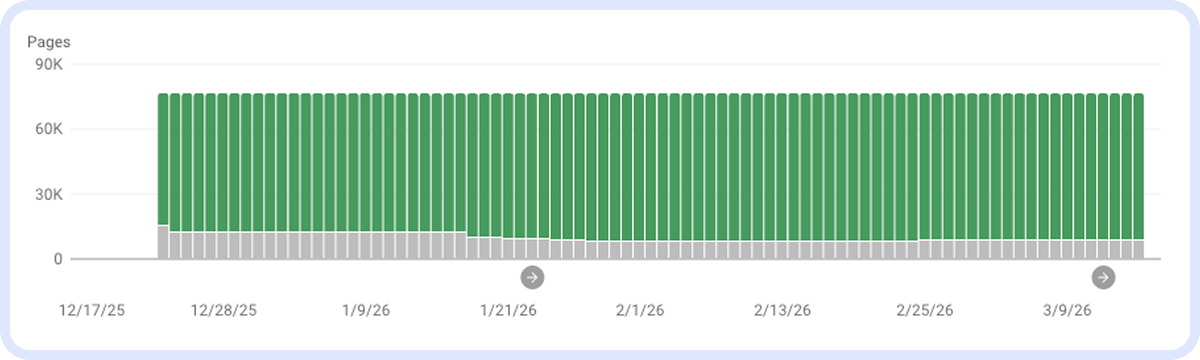
Також в GSC можна переглянути, які сторінки непроіндексовані та чому, або, навпаки, чи потрапили в індекс непотрібні сторінки й інші помилки:
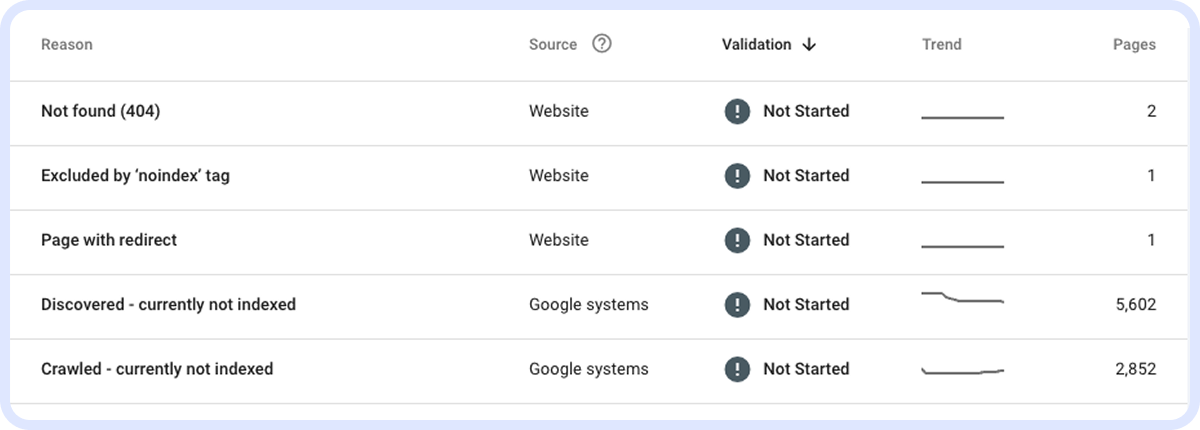
Структура сайту та внутрішнє перелінкування
Правильна архітектура допомагає ботам розуміти ієрархію сайту й розподіляти «вагу» між сторінками. Одне внутрішнє посилання з авторитетної сторінки на слабку може помітно рухати позиції.
Що перевіряємо:
- логічна ієрархія URL — без надмірної вкладеності й випадкових рядків;
- глибина сторінок — ключові доступні не глибше 3–4 кліків від головної;
- orphan-сторінки — є в сайтмапі, але без жодного внутрішнього посилання;
- анкор — описовий чи generic («click here», «читати далі»), чи не пропущена можливість додати анкор-ключ;
- broken internal links — ведуть на 404 або в redirect-ланцюжки;
- дублі сторінок;
- сторінки без внутрішнього перелінкування, але з беклінками;
- пагінація — коректно налаштована.
🚩На що звернути увагу:
- пріоритетна сторінка має менше 3 внутрішніх посилань;
- є сторінки з беклінками, але без жодного внутрішнього посилання — вага іде в нікуди;
- анкори внутрішніх посилань без ключових слів.
Інструменти: Screaming Frog, Ahrefs Site Audit, GSC (Links report), Netpeak.
Що можна передати ШІ:
- завантажити crawl export (URL, depth, inlinks, outlinks, anchor text, status) → знайти «глибокі» сторінки й рекомендувати, куди додати внутрішні посилання;
- автоматизувати метадані: «Знайди всі сторінки в папці /blog, де відсутній alt у зображень або meta description, і згенеруй їх на основі контенту»;
- виправити редиректи: «Проаналізуй файл _redirects або конфіг Nginx, знайди дублікати та виправ циклічні редиректи»;
- перевірити коди відповіді, написати скрипт на Node.js/Python, який просканує список URL і видасть звіт про 404 помилки (за допомогою Claude);
- знайти в статтях згадки терміну «sampe» й додати посилання на сторінку «samples».
Prompt:
Identify pages more than 4 clicks from homepage, orphaned pages, and broken internal links. Suggest internal linking opportunities for priority pages.
Примітка. На скриншоті — реальний результат краулу 561 сторінки. Одразу видно проблему: 25 orphaned-сторінок без жодного внутрішнього посилання і 442 сторінки з мінімальним link score. Більшість сторінок не отримують внутрішніх посилань і фактично невидимі для розподілу ваги всередині сайту:
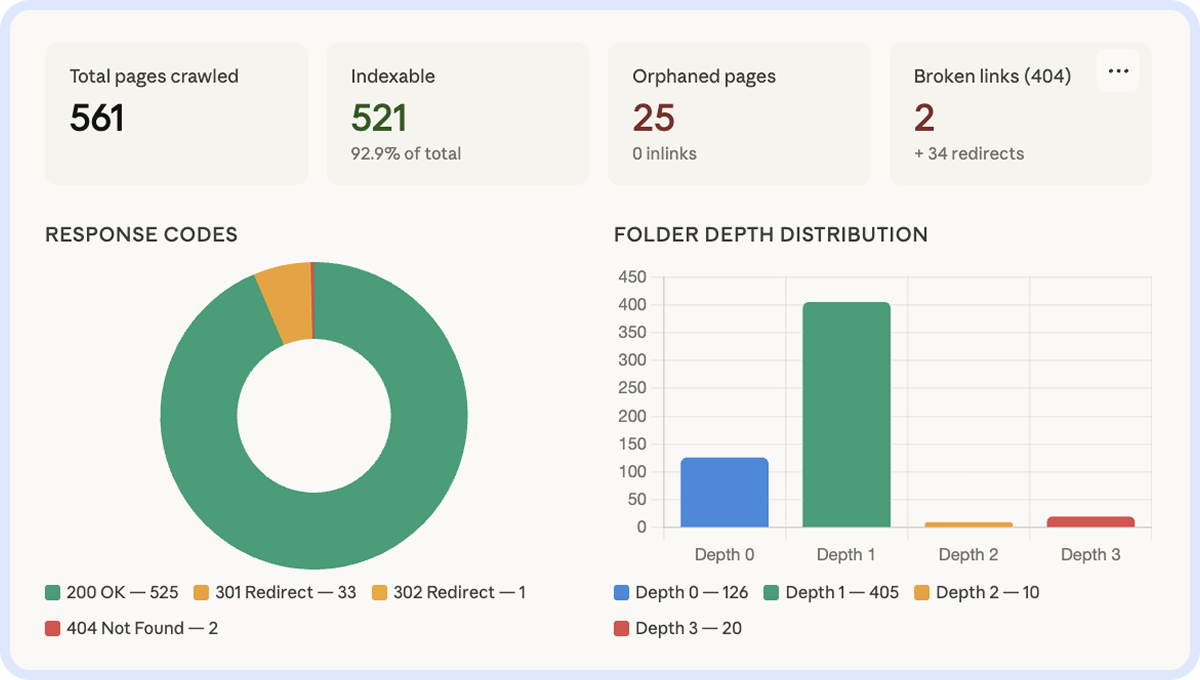
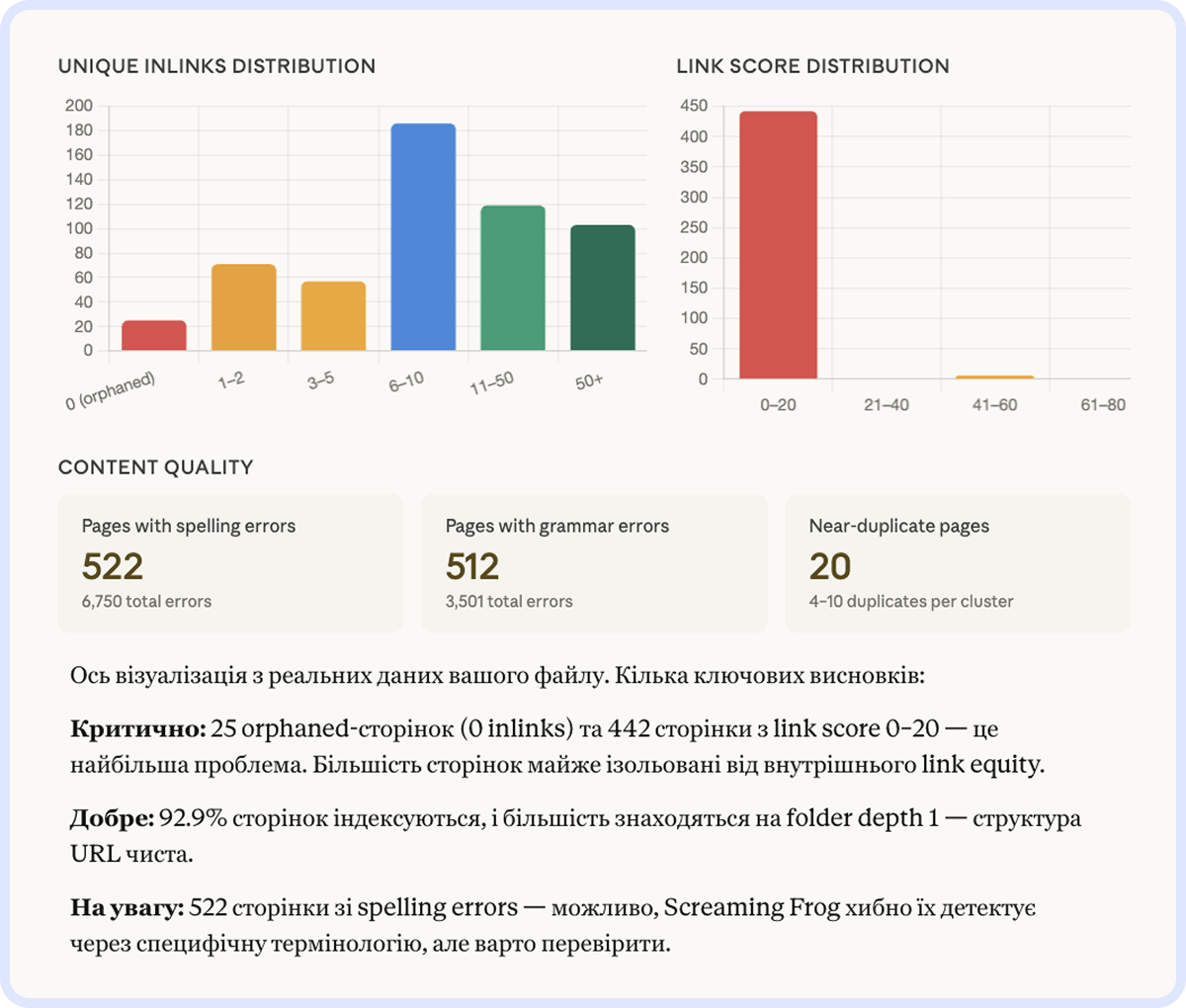
Meta & Structured Data
Title й meta description — це перше, що бачить користувач у видачі. Вони впливають на CTR, а значить — на трафік і позицію. Schema markup допомагає Google краще розуміти контент і показувати rich snippets, у тому числі для ранжування в AIO та LLM.
Що перевіряємо:
- Title — унікальний, перші 60 символів містять ключове слово;
- Meta description — унікальний потенціал для CTR;
- OG-теги / соцмережі — для коректного шерінгу;
- Schema markup — перевірка через Rich Results Test і validator.schema.org;
- max-image-preview:large — для відображення великих зображень у видачі;
- Favicon — присутній і коректний.
🚩На що звернути увагу:
- CTR нижче 1% при позиціях 1–3 — майже завжди проблема в title або description;
- більше 15% сторінок мають однакові або відсутні title;
- Schema є в коді, але Rich Results Test показує помилки — розмітка не працює.
Інструменти: Screaming Frog, Sitechecker, Google Rich Results Test, SEO META in 1 CLICK, Ahrefs.
Що можна передати ШІ:
- завантажити список title/description по всіх сторінках → знайти дублі, занадто короткі/довгі, відсутні (якщо у вас немає звіту Screaming Frog або ж ви кастомізуєте свій промпт, щоб виявити наявність ключів тощо);
- згенерувати варіанти title/description для сторінок без них або з низьким CTR;
- просканувати шаблони сторінок (наприклад, у Next.js, Blade, Liquid) та автоматично додати JSON-LD розмітку для FAQ, Product або Article, підтягуючи змінні з коду (за допомогою Claude code).
Prompt:
Review these titles and meta descriptions. Flag duplicates, missing ones, and those over 60/160 characters. Suggest improved versions for the 10 worst.
Примітка. Приклад виводу: 143 title обріжуться у видачі, бо довші за 60 символів, 177 meta description — довші за 160. Окремо — 36 сторінок взагалі без title і 48 без meta description. AI пріоритизує fixes і одразу дає варіант переписаного title і description для кожної проблемної сторінки:
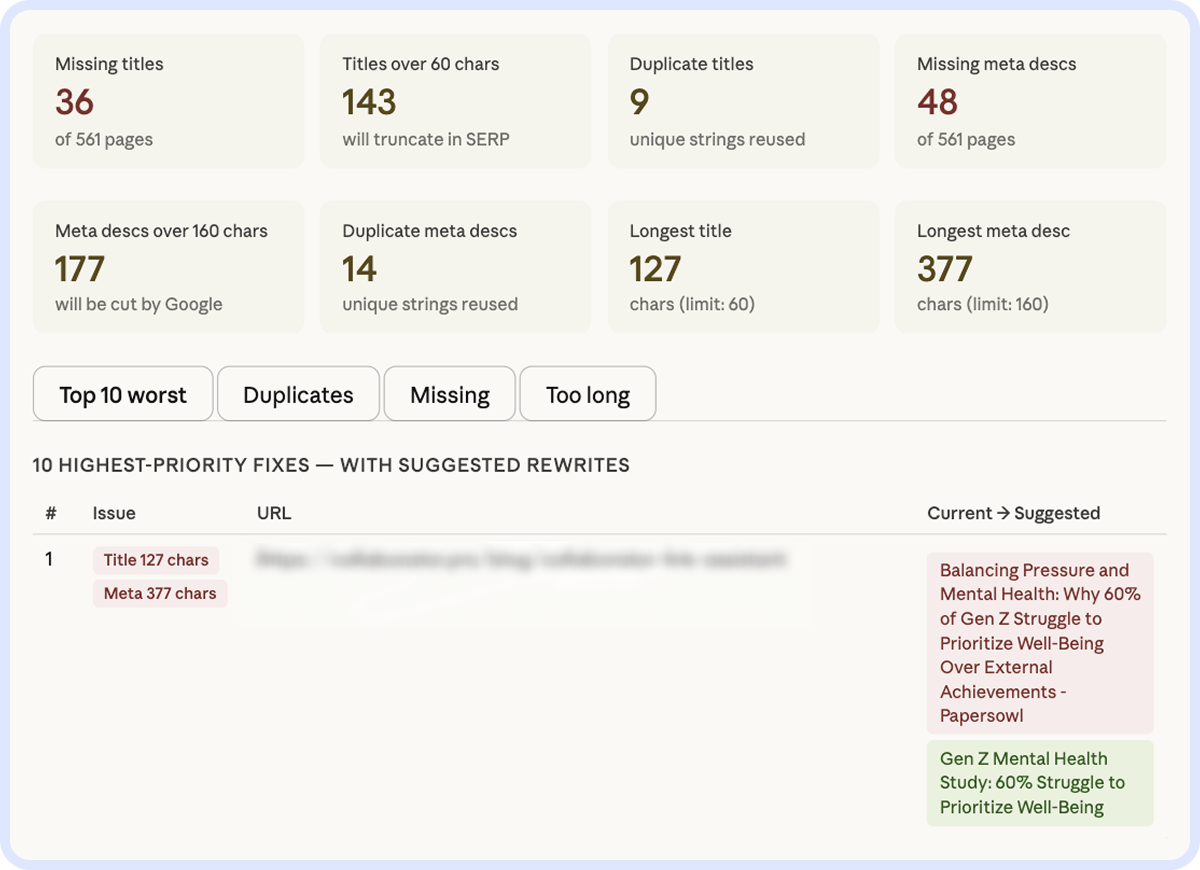
Core Web Vitals і швидкість
Google використовує CWV як фактор ранжування. Повільний сайт = гірший UX = вищий bounce rate = менше конверсій. Особливо критично для мобільних пристроїв.
Що перевіряємо:
- LCP (Largest Contentful Paint) — ціль: < 2.5 сек;
- INP (Interaction to Next Paint, замінив FID) — ціль: < 200 мс;
- CLS (Cumulative Layout Shift) — ціль: < 0.1;
- TTFB (Time to First Byte) — час до першого байту від сервера;
- Mobile vs Desktop — перевіряємо обидва окремо;
- Render-blocking CSS/JS — що затримує завантаження;
- важкі елементи: зображення без оптимізації, сторонні скрипти, unnecessary plugins.
Інструменти: PageSpeed Insights, GSC (Core Web Vitals report), Lighthouse, WebPageTest.
Що можна передати ШІ:
- завантажити PageSpeed Insights JSON export → розставити пріоритети за fix-ам, виходячи з Impact Score;
- перетворити сухий звіт у конкретні завдання для розробників з поясненням, чому це важливо.
Prompt:
Here are Core Web Vitals results for our top 20 pages. Prioritize the fixes by potential traffic impact and group by issue type.
Примітка. Приклад output:

Мобільність і безпека
Google використовує mobile-first indexing: саме мобільна версія є основою для ранжування. Проблеми з безпекою (hacked content, відсутність HTTPS) можуть призвести до manual action або попереджень у браузері.
Що перевіряємо:
1. Мобільність:
- Google Mobile-Friendly Test — базова перевірка;
- Responsive design — контент і посилання збігаються з desktop;
- Паритет контенту mobile/desktop — однакові тексти, заголовки, посилання.
2. Безпека:
- HTTPS — правильно налаштований на всіх сторінках;
- HSTS — підтримка;
- Відсутність hacked content, malware — перевірка в GSC (Security Issues).
- Відсутність security issues у GSC або моніторингових інструментах.
Інструменти: Google Mobile-Friendly Test, GSC (Mobile Usability + Security), Lighthouse.
Що можна передати ШІ:
- завантажити список Mobile Usability errors із GSC → класифікувати за типом і пріоритизувати виправлення.
Контент-аудит
База одна — якість, унікальність, відповідність інтенту та EEAT-факторам. Але навіть якісний контент треба регулярно переглядати.
Текстовий контент
Застарілий контент втрачає позиції. Сторінки з низьким трафіком можуть розмивати crawl budget. Контент-гепи — це готові можливості для росту, які конкуренти вже використовують.
Що перевіряємо:
- база всіх сторінок сайту з датами створення й оновлення;
- сторінки з низьким трафіком — оновлювати, об'єднувати або видаляти;
- Low-hanging fruit keywords — позиції 4–15, де невеликий push дасть результат;
- контент-гепи з конкурентами — чого у вас немає, а в них є;
- Featured snippet та AIO-можливості;
- дублі контенту — GSC («Duplicate without user-selected canonical»), Near Duplicates у Screaming Frog;
- E-E-A-T сигнали — автор, дата публікації / оновлення, довіра до джерела;
- кількість сторінок із високим і середнім рівнем AI перевіряємо на відповідність Google Quality Guidelines;
- граматика, читабельність контенту;
- Intrusive interstitials і heavy ads above the fold — шкодять UX і ранжуванню.
🚩На що звертаємо увагу:
- сторінка не оновлювалась більше 12 місяців і стабільно втрачає позиції;
- більше 30% сторінок сайту мають менше 10 візитів на місяць — розмивають crawl budget;
- кілька сторінок ранжуються за одними і тими ж ключами — канібалізація з'їдає позиції обох.
Інструменти: GSC, Screaming Frog, Sitechecker, Ahrefs (Content Gap, Site Audit) та аналоги.
Що можна передати ШІ:
- завантажити список всіх URL із трафіком і датами → класифікувати контент на: «оновити», «об'єднати», «видалити», «залишити»;
- Content gap аналіз: знайти прогалини між вашими темами і темами конкурентів, запропонувати пріоритети для нових матеріалів;
- перевірити структуру статей на наявність ознак авторства, дат, джерел за вашим E-E-A-T-чеклістом (приклад).
Prompt:
Here is a list of pages with traffic data and last modified dates. Classify each as: Update (declining, outdated), Merge (similar topics, low traffic), Remove (zero value), or Keep. Explain reasoning.


Зображення та відео
Зображення без alt-тегів — це втрачений трафік із Google Images і сигнал про низьку якість контенту. Важкі зображення прямо впливають на LCP і CWV. Відео зі schema — кандидати на rich snippets у видачі.
Що перевіряємо:
1. Зображення:
- Alt-теги — описові, містять ключові слова де доречно;
- висота/ширина зображень визначені — запобігає CLS;
- описові назви файлів, title, caption;
- зображення не містять важливий текст (бо бот його не читає);
- Image sitemap — для важливих зображень;
- розміри файлів — оптимізовані для швидкості.
2. Відео:
- відео розміщені на публічних індексованих сторінках;
- Video schema markup;
- Video sitemap;
- правильний HTML-тег (не Flash).
Інструменти: Screaming Frog, Sitechecker, Structured Data Viewer, Google Rich Results Test.
🚩На що звернути увагу:
- більше 30% зображень без alt-тексту;
- зображення важать більше 500KB — прямий вплив на LCP;
- відео є на сторінці, але немає Video schema — втрачаєте можливість потрапити в rich snippets.
Що можна передати ШІ:
- завантажити список URL із відсутніми або порожніми alt-тегами → запропонувати alt-тексти, виходячи з URL, назви файлу або тексту навколо зображення.
Prompt:
Generate descriptive alt text for these image filenames in context of [тематика сайту]: [список файлів].
Беклінки & Off-Page аудит
Лінки — усе ще один із найважливіших факторів просування, але не всі з них рівноцінні. Траст, трафік, місце розміщення, релевантність — усе це впливатиме на сайт і позиції.
Якісний беклінк-профіль підвищує авторитетність домену й допомагає ранжуватися за конкурентними запитами. Токсичні посилання, надмірність, штучність профілю ризикує отримати санкції від Google. Мертві сторінки з беклінками — це готові можливості для redirect і відновлення «ваги».
Що перевіряємо:
Крок 1: Збір даних
- GSC → Links → Export External Links (до 100k посилань);
- SEMrush/Ahrefs Backlink Explorer → Export Backlinks + Referring Domains;
- внутрішні сервіси відстежування лінків — об'єднати дані, прибрати дублікати.
Крок 2: Організація таблиці
- Linking Domain — звідки посилання;
- Target Page — на яку сторінку посилання;
- Anchor Text — природний чи over-optimized;
- Link Type — follow / nofollow (здоровий профіль має мікс);
- Authority Score/DR — 0–100 (SEMrush AS);
- Toxicity / Spam Score — 0–100 (вище = небезпечніше);
- Traffic;
- Keywords;
- RD/LD -> яке співвідношення ви допускаєте;
- Spam — яку кількість чорних тематик на сайті (контент, вихідні лінки) ви допускаєте;
- Relevance — чи релевантний домен до ніші;
- Index Status — активне чи зламане посилання;
- Initial Assessment — Good / Suspicious / Toxic;
- Action — Keep / Remove / Disavow.
Крок 3: Що шукаємо
- різкі зміни в кількості referring domains (ріст або падіння);
- Dead pages із беклінками → зробити 301 редирект на релевантну сторінку;
- порушення Google Link Spam Guidelines;
- Disavow-файл — чи не заблоковані важливі посилання;
- беклінки від нерелевантних або низькоякісних доменів;
- спам — чи проіндексовані проставлені вами лінки.
Інструменти: GSC, SEMrush, Ahrefs, Majestic, Sitechecker.
Важливо: дивимось не на окремі показники, а на сукупність. Відправна точка — DR менше 10 і нульовий трафік: такі домени відкидаємо одразу. Далі аналіз залежить від типу анкору. Для брендових і безанкорних посилань вимоги можуть бути менш строгими — вони природніші за профілем. Для money-анкорів планка вища: тут важливо дивитися і на релевантність домену, і на його трафік, і на те, скільки таких анкорів уже є в профілі.
Що можна передати ШІ:
- завантажити таблицю беклінків → класифікувати Good/Suspicious/Toxic із поясненням критеріїв для кожного;
- Anchor text аналіз: знайти over-optimized anchor text patterns, що можуть тригерити спам-фільтри;
- перетворити raw-дані в короткий беклінк-самарі з ключовими метриками.
Prompt:
Review this backlink list. Classify each link as Good, Suspicious, or Toxic based on: domain relevance, authority score, toxicity score, and anchor text patterns. Flag any that need disavow consideration.

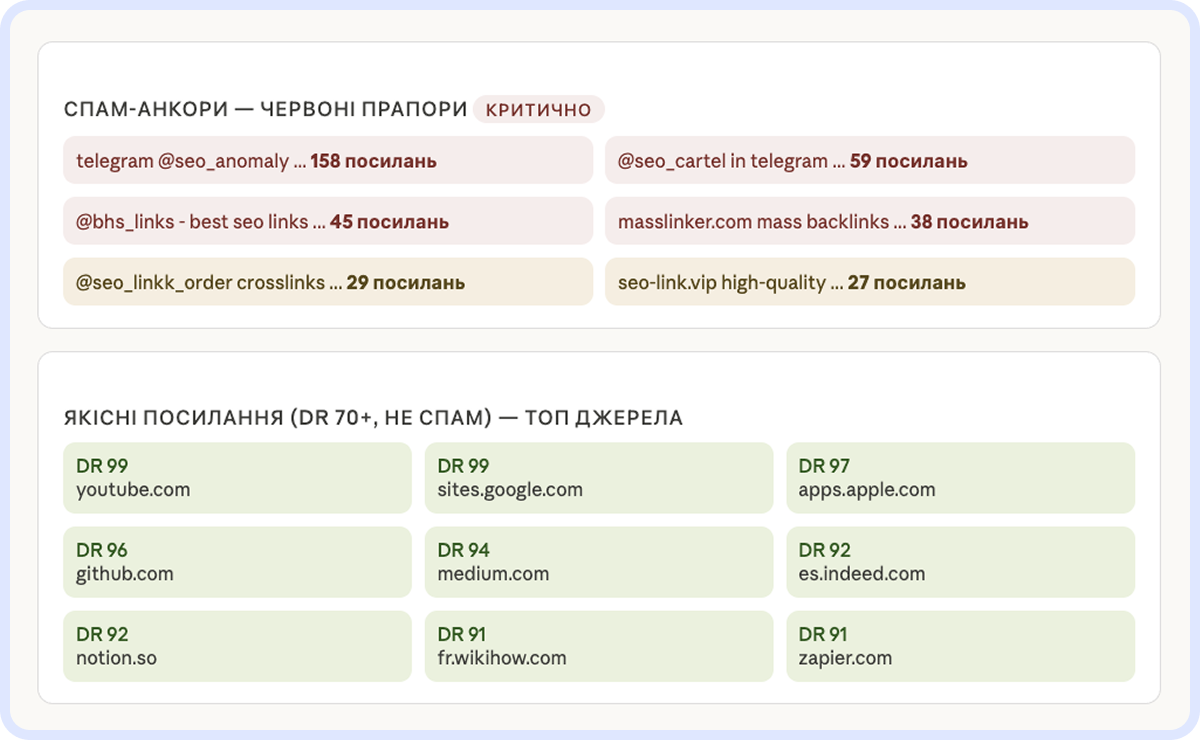
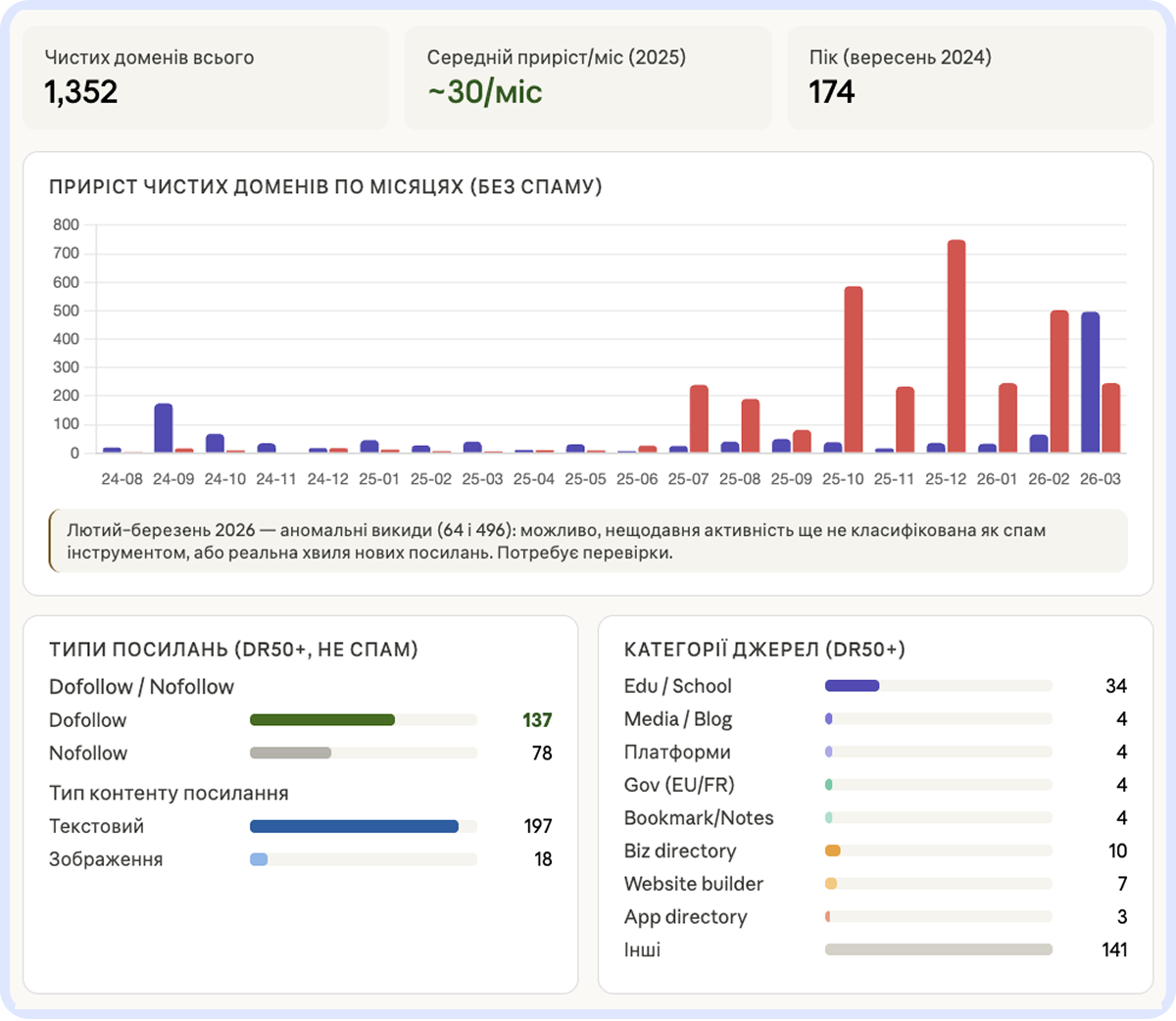
Міжнародне SEO
Неправильний hreflang може призвести до того, що Google показуватиме неправильну мовну версію в неправильній країні. Автоматичні редиректи за гео блокують Googlebot (він завжди ходить з US IP).
Що перевіряємо:
- геотаргетинг — GSC / локальні URL налаштовані;
- hreflang — валідний, двосторонній (кожна мова посилається на всі інші);
- lang атрибут у HTML — мова сторінки очевидна;
- без автоматичних редиректів за гео (бот завжди ходить із США);
- Canonical і hreflang не конфліктують між собою.
Інструменти: hreflang Tags Testing Tool, Screaming Frog, GSC.
Що можна передати ШІ:
- завантажити таблицю hreflang тегів → знайти відсутні пари, конфлікти з canonical, неправильні мовні коди.
Prompt:
Audit this hreflang implementation. Find: missing return tags, conflicts with canonicals, invalid language codes, and pages missing from any language version.
Замість висновку
Формат аудиту — справа особиста. Можна перевіряти розмітку, хрефланги, авторів, рівень AI у контенті. Можна повністю автоматизувати перевірки чи все робити руками. Перевіряти одним тулом чи декількома, підключати AI чи ні — кожен обирає форму, яка підходить для конкретного сайту в цей момент.
Для мене цілком робочою схемою стало брати повний аудит і модифікувати його під кожен сайт. Десь я викидаю пункти або окремі блоки аудиту, а десь, навпаки, додаю те, що буде актуально конкретному проєкту. Так само відрізняється й частота аудитів. Раз на місяць — швидка перевірка технічки й беклінків. Раз на квартал — контент, беклінки повністю, повний технічний аналіз.
Чи можна все передати ШІ? Як на мене, наразі штучний інтелект — це зручний асистент, який прискорює обробку даних. Він може набагато швидше проаналізувати великі файли, відобразити динаміку, шукати патерни, генерувати звіти. А ще ви можете налаштувати AI-агента, який буде за вас брати частину цієї інформації й видавати звіти. Але рішення — завжди за фахівцем.
Схожі статті