У березні 2023 року вийшла потужна стаття Баррі Адамса, незалежного SEO-консультанта для новинних ЗМІ, співзасновника конференції NESS (до речі, серед клієнтів Баррі — найбільші світові медіабренди, зокрема News UK, The Guardian, FOX, Future Publishing, Euronews і Hearst). У публікації він детально розповідає про краулінговий бюджет для ЗМІ, типові помилки та особливості його оптимізації.
Ця стаття підготована Бюро перекладів для бізнесу MK: translations на основі оригінального матеріалу Crawl optimization for news publishers (with Barry Adams).
Оптимізація сканування для новинних ЗМІ
Пошукові системи використовують процес краулінгу для пошуку нового контенту, який вони включають у результати видачі. Для більшості сайтів такий перегляд сторінок не є приводом для хвилювання. Однак, оскільки ЗМІ часто мають великі та складні сайти, необхідно докласти певних зусиль, щоб пошукові боти на кшталт Googlebot могли легко знаходити ваш контент.
Оптимізація сайту для сканування дозволяє Google легко знаходити свіжі матеріали. Це означає, що він може швидко проіндексувати статті й почати показувати їх у результатах пошуку, включаючи каруселі головних подій та інші функції ранжування, притаманні саме новинам.
Можливості Googlebot обмежені, тому видавці мають оптимізувати свої сайти для сканування. Краулінговий бюджет — це загальний обсяг роботи, яку пошукова система витрачає на сканування вашого сайту. Існує багато способів витратити краулінгові бюджети на URL-адреси, які не підвищують ефективності сайту при пошуку.
Для оптимізації краулінгового бюджету, спочатку потрібно подивитися, на що він витрачається. Звіт Crawl Stats, доступний в Google Search Console, надає багато інформації щодо сканування вашого сайту пошуковим ботом Googlebot.
Давайте детально розглянемо його.
Crawl Stats
Цей звіт у Search Console можна знайти в Налаштуваннях ліворуч. Натисніть «Відкрити звіт», після цього відкриється інформаційна панель, яка показує високорівневі показники сканування вашого сайту:
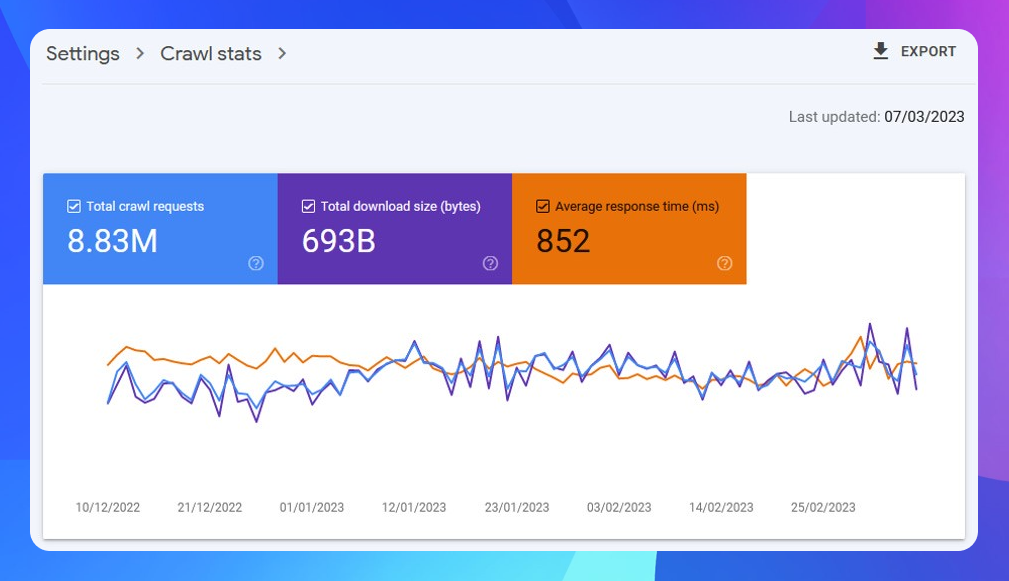
Найважливішим показником є середній час відгуку (мс). Це показник того, як швидко ваш сайт передає URL-адреси Googlebot. Час відгуку сервера має бути досить швидким, оскільки сканування повільних сайтів теж відбувається набагато повільніше.
Існує чітка зворотна кореляція між часом відгуку та кількістю запитів: якщо час відгуку збільшується (тобто сайт стає повільнішим), то кількість запитів зменшується. Це пов'язано з тим, що краулінговий бюджет — це концепція, заснована на часі: Googlebot проводить певний час на вашому сайті. Чим довше сайт реагує на запит, тим менша кількість сторінок буде просканована.
Перше, що потрібно зробити для оптимізації сканування — покращити середній час відгуку. Цю просту, на перший погляд, рекомендацію важко втілити на практиці. Час відгуку сервера залежить від різних технічних факторів, багато з яких нелегко оптимізувати.
Загалом, час відгуку покращується завдяки агресивному кешуванню на стороні сервера та збільшенню пропускної здатності хостингу, а також ефективному використанню CDN, щоб упевнитися, що Googlebot не доведеться обійти весь світ, щоб просканувати ваш сайт.
Порада від професіонала: Googlebot в першу чергу сканує з центрів обробки даних Google, що розташовані в Каліфорнії.
Точний цільовий показник часу відгуку досі є предметом дискусії. Ідеальний показник — 200 мс або швидше, але для більшості сайтів цього дуже важко досягти. На мою думку, буде достатньо поставити за мету 600 мс або швидше. Все, що перевищує час 600 мс — занадто повільне й потребує оптимізації.
Коди відповідей
Розглянемо наступну частину звіту Crawl Stats — це таблиця кодів «За реакцією»:
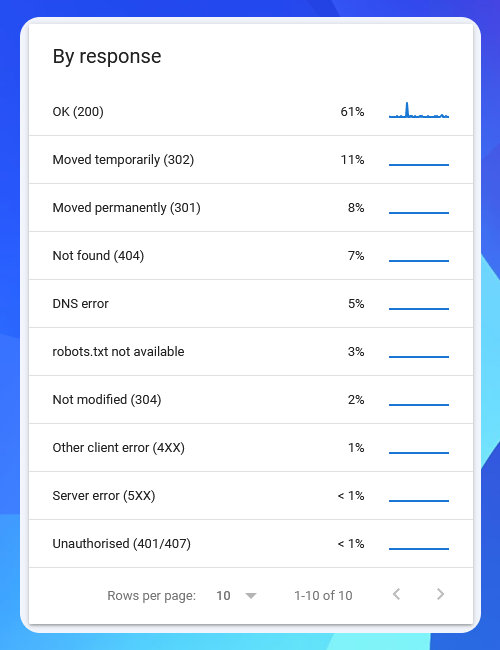
Цей звіт відображає відповіді вашого сайту на запити сканування Googlebot. Перше, що робить сайт після запиту відкрити сторінку — відповідає кодом стану HTTP. Цей код стану повідомляє Google (і браузерам), яку відповідь він отримує.
Google має гарну документальну базу щодо кодів стану HTTP і процесу їхньої обробки системами сканування та індексування.
Більшість ваших кодів стану HTTP має бути 200 (OK). Якщо звіт Crawl Stats вашого сайту показує великий відсоток інших відповідей — особливо перенаправлень 301/302 та серверних помилок 5XX — це може означати, що є проблеми з краулінговою оптимізацією, які необхідно розв’язати.
Натисніть на кожен рядок цієї таблиці, щоб отримати список прикладів URL-адрес для кожного HTTP-відгуку, і ви зможете побачити, які URL-адреси є потенційно проблемними.
Типи файлів
Далі розглянемо таблицю типів файлів. Тут бачимо, які типи файли Googlebot сканує на вашому сайті:
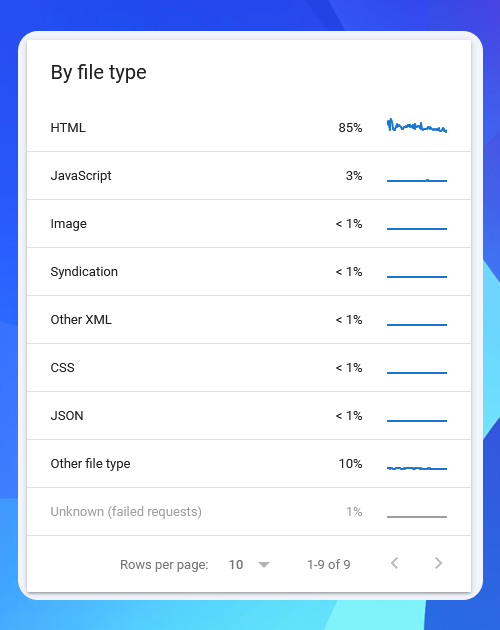
Оскільки в ЗМІ більшість сторінок, які повинні скануватися, індексуватися та з’являтися в результатах пошуку, доступні у вигляді HTML-файлів, то важливо, щоб саме HTML був найбільш запитуваним типом файлів.
Якщо на сканування інших типів файлів — JavaScript, JSON, файли шрифтів (у розділі Інший тип файлів) витрачається багато зусиль, це може означати, що Google має менший краулінговий бюджет для сканування сторінок вашого сайту.
Мета сканування
Далі розглянемо звіт «За призначенням». Він показує, скільки витрачається ресурсів на сканування відомих URL-адрес, які Google сканує повторно (Refresh), і на нові URL-адреси, які скануються вперше (Discovery):

Співвідношення між показниками Refresh і Discovery може відрізнятися у різних ЗМІ залежно від того, наскільки великим є їхній сайт і скільки нових статей вони публікують щодня.
Для більшості відомих ЗМІ показник Discovery понад 10% (відповідно, показник Refresh менш як 90%) є приводом для занепокоєння, оскільки це означає, що Googlebot знаходить багато нових URL-адрес для сканування. І, можливо, втрачає час дарма на ті URL-адреси, які не варті уваги.
Натисніть на будь-який рядок таблиці, щоб отримати приклади URL-адрес для обох типів сканування.
Типи Googlebot
Нарешті, звіт про типи Googlebot показує, які типи пошукових роботів сканують ваш сайт і який краулінговий бюджет споживає кожен з них:

Googlebot має багато різних сканерів, кожен з яких призначений для різних цілей. Оскільки Google здебільшого використовує мобільний підхід до сканування та індексації, бот, орієнтований на смартфон, має бути найбільш використовуваним. Google також перевіряє контент сайту для ПК (щоб переконатися, що він не відрізняється від того, що ви надаєте користувачам мобільних пристроїв), тому звіт може показати, що Googlebot для ПК витрачає значну частину краулінгового бюджету.
Поширеною проблемою є велика кількість зусиль сканування, що витрачається на завантаження ресурсів сторінки, тобто Googlebot витрачає багато часу на сканування елементів сторінки, які не є HTML. Це можуть бути файли JavaScript, JSON-пакети, файли CSS та файли шрифтів — всі вони необхідні для відображення повного візуального вигляду вебсторінки користувачам у браузері.
Щоб скоротити час, який Google витрачає на ресурси сторінок, створюйте легкі, не захаращені вебсторінки. Такі сторінки завантажуються швидше, забезпечують кращу взаємодію з користувачем і допомагають оптимізувати краулінговий бюджет.
Ще однією потенційною проблемою є ситуація, коли AdsBot — бот, який використовується для динамічних пошукових рекламних кампаній, — витрачає великий відсоток краулінгового бюджету. Іноді AdsBot може вийти з-під контролю і витратити весь ваш краулінговий бюджет. Порадьтеся зі своєю рекламною командою, щоб переконатися в можливості стиснути кампанії, якщо ви побачите, що на них витрачається великий відсоток краулінгового бюджету.
Поза межами Crawl Stats
Яким би корисним не був звіт Crawl Stats, він не відображає повної картини. Ваш сайт може витрачати краулінговий бюджет й іншими способами.
Проблеми з дублюванням контенту. Однією з поширених проблем дублювання контенту є ситуація, коли сайт приймає URL-адреси зі слешем в кінці та без нього. Наприклад, стаття може мати дві такі URL-адреси:
- www.example.com/news/article-url-here
- www.example.com/news/article-url-here/
Коли сайт відображає одну й ту саму статтю на обох цих URL-адресах з кодом статусу HTTP 200 OK, Googlebot це розцінить як два різних запити сканування з кодом статусу 200 OK. Звіт Crawl Stats в Search Console розпізнає це як проблему.
Таким чином це може означати, що кожна сторінка на вашому сайті має дублікат, який теж можна сканувати. Googlebot сприймає це як подвійний обсяг для сканування.
Існують прості способи переконатися, що Google вибирає для індексації тільки одну з цих URL-адрес — за допомогою канонічного метатега або перенаправлення 301 з однієї версії на іншу, але ці корективи вирішують тільки проблему індексації. Вони не розв’язують основну проблему краулінгового «сміття».
Використовуйте SEO-сканер для сканування вашого сайту і виявлення цих проблем. Всі інструменти SEO-сканування мають вбудовані звіти, які показують проблеми краулінгового «сміття», пов'язані з дублюванням контенту, внутрішніми перенаправленнями та іншими недоліками.
Мій фаворит — SEO-сканер Sitebulb, оскільки це, мабуть, найдосконаліший технічний SEO-сканер з усіх доступних. Screaming Frog, Lumar, Botify, JetOctopus та багато інших — хороші альтернативи.
Запитання щодо краулінгової оптимізації
Оскільки краулінгова оптимізація — це широка тема, я спробую відповісти на деякі з найбільш поширених запитань:
- Коли слід непокоїтися щодо краулінгового бюджету?
Для більшості сайтів краулінговий бюджет не є приводом для занепокоєння. Якщо ваш сайт має менш як 100 000 URL-адрес, малоймовірно, що у вас є проблеми зі скануванням.
У сайтів, які мають від 100 000 до 1 мільйона URL-адрес, можуть виникати деякі проблеми з краулінговим бюджетом, які варто виправити.
Якщо сайт має більше мільйона URL-адрес, обов'язково треба регулярно переглядати свій краулінговий бюджет, щоб не допустити серйозних проблем зі «сміттям».
- Наскільки важливим є краулінговий бюджет для ЗМІ?
ЗМІ мають приділяти більше уваги краулінговому бюджету, ніж інші сайти, що не пов'язані з новинами. Новини швидко змінюються, сюжети швидко розвиваються, і люди очікують побачити найсвіжіше в Google News і Top Stories.
Видавці мають переконатися, що статті можна сканувати, а потім індексувати, щойно вони будуть опубліковані. Забезпечення ефективного сканування вашого сайту без серйозних проблем з краулінговим «сміттям» є ключовим аспектом успішного SEO у сфері новин.
- А як щодо XML-карт сайту?
Хоча XML-карти сайтів дуже корисні, і я завжди рекомендую їх мати, вони не є основним механізмом Google для пошуку нового контенту.
Google регулярно перевіряє карти вашого сайту, особливо карту сайту Google News, але сканування — це основний метод, який Google використовує для пошуку нових статей. Таким чином, XML-карти не замінять ефективно просканований сайт.
- Як краще використовувати robots.txt?
За замовчуванням Google вважає, що може сканувати кожну URL-адресу сайту. Ви можете визначити так звані правила заборони у файлі robots.txt вашого сайту, які вказують Google на заборонені для сканування URL-адреси. Googlebot є, так би мовити, ввічливим сканером, буде дотримуватись ваших правил заборони.
Це означає, що правила заборони robots.txt є дуже дієвими, тому їх слід ретельно продумати. Бо можна помилково заборонити Google сканувати потрібні сторінки вашого сайту. Протестувати зміни можна у файлі robots.txt за допомогою robots.txt tester від Google, що я завжди рекомендую перед тим, як вносити будь-які зміни до вашого файлу robots.txt.
Майте на увазі, що нове правило заборони в robots.txt не означає, що краулінговий бюджет буде спрямований на інші області сайту. Google опублікував детальний посібник з управління краулінговим бюджетом, в якому йдеться про те, що коли ви забороняєте розділ вашого сайту, краулінговий бюджет, пов'язаний з цим розділом, витрачається даремно — він фактично випаровується:
«Не використовуйте robots.txt для тимчасового перерозподілу краулінгового бюджету на інші сторінки; використовуйте файл robots.txt для блокування сторінок або ресурсів, які не потрібно сканувати взагалі. Google не буде перерозподіляти цей краулінговий бюджет на інші сторінки, якщо тільки він вже не досяг ліміту сканування вашого сайту».
Після впровадження нового правила заборони в robots.txt, Google може знадобитися кілька тижнів або місяців, щоб наново вивчити URL-адреси вашого сайту, які підлягають скануванню, і перемикнутися на сторінки, до яких йому дозволений доступ.
- Як помилки 404/410 впливають на сканування?
Якщо на вашому сайті багато кодів статусу HTTP 404 Not Found або 410 Gone, це не дуже сильно впливає на краулінговий бюджет.
Як тільки Googlebot бачить код статусу 4XX будь-якого типу, він завершує запит на сканування і переходить до наступної URL-адреси.Тобто не витрачає більше часу на 404/410 або інші 4XX сторінки, тому сума витраченого бюджету сканування мінімальна.
Проте періодично перевіряти сайт на наявність помилок 404/410 все ж необхідно, оскільки внутрішні посилання, що вказують на сторінки Not Found, створюють негативний досвід користувача. Крім того, якщо раніше на URL була активна сторінка, а зараз вона видає помилку 404, SEO-вартість цієї сторінки може бути втрачена, тому вам, можливо, знадобиться задіяти перенаправлення 301 на заміну сторінки.
- Чи використовують перенаправлення 301/302 краулінговий бюджет?
Так. На відміну від кодів статусу 4XX, Google потрібно докласти певних зусиль для сканування, щоб слідувати за перенаправленнями 301 і 302. Отже, це один з аспектів вашого сайту, який бажано мінімізувати.
Але перенаправлення дуже важливі. При зміні URL-адреси перенаправлення передають налаштування SEO новій сторінці. Перенаправлення необхідні, їх не можна уникнути, але вони не повинні витрачати занадто велику частину краулінгового бюджету.
Варто регулярно перевіряти внутрішні посилання вашого сайту (за допомогою SEO-сканера), щоб переконатися, що всі вони вказують безпосередньо на кінцеву URL-адресу без будь-яких перенаправлень.
Дізнатися більше
Про краулінгову оптимізацію можна ще багато говорити, і у кожного сайту можуть виникати власні унікальні проблеми, коли йдеться про максимізацію роботи Google-бота.
Я вже згадував документацію Google, але я ще раз наведу перелік, оскільки це неймовірно корисні джерела інформації:
- Посібник з управління краулінговим бюджетом для власників великих сайтів
- Як коди стану HTTP, помилки мережі та DNS впливають на пошук Google
- Знайомство з robots.txt
Сподіваюся, ці основи краулінгової оптимізації були корисними, і ви знайшли кілька цінних порад, які зможете застосувати у своїй SEO-діяльності.
Дякуємо нашим друзям із MK: translations за переклад потужного матеріалу 💙
Нагадаємо, у блозі Коллаборатора є безліч крутих статей, що допоможуть прокачати професійні скіли та поповнити знання.
Нещодавно ми розповіли, як написати пресреліз та чому він вважається ефективним інструментом підвищення впізнаваності бренду й розповсюдження інформації про важливі події.
А про важливі апдейти дізнавайтесь на наших сторінках у Фейсбук, Телеграм та Інстаграм🙂