Что такое метатег robots и как его использовать
Метатег robots нужен для управления индексацией сайта роботами поисковиков. Способ реализации: meta robots указывают в html-коде страницы.
Процесс индексации сайта состоит из нескольких этапов: загрузки контента, его анализа и добавления в базу роботами поисковой системы. Информация, попавшая в индекс, начинает отображаться в выдаче.
Не стоит путать метатег robots с файлом robots.txt. В данном материале рассмотрим управление индексацией с помощью метатега robots.
Зачем нужен метатег robots для SEO
Рассмотрим, когда стоит использовать данный тег и как это помогает оптимизировать сайт.
1. Управление индексацией страниц.
Не все страницы сайта полезны для привлечения органического трафика. Индексация некоторых из них, например, дублей, может и вовсе навредить видимости ресурса. Поэтому с помощью команды noindex обычно скрывают:
- дубликаты страниц;
- страницы сортировки и фильтров;
- страницы поиска и пагинации;
- служебные и технические страницы;
- сервисные сообщения для клиентов (об успешной регистрации, заказе и т.д.);
- посадочные страницы для рекламных кампаний и тестирования гипотез;
- страницы в процессе наполнения и разработки (лучше закрывать паролем);
- информацию, которая пока не актуальна (будущая акция, запуск новинки, анонсы запланированных мероприятий);
- устаревшие и неэффективные страницы, которые не приносят трафик;
- страницы, которые нужно закрыть от некоторых видов ботов.
2. Управление индексацией файлов определенного формата.
От робота можно скрывать не только html-страницы, но и документ с другим расширением, например, страницу изображения или pdf-файл.
3. Сохранение веса страницы.
Запрещая роботам переходить по ссылкам с помощью команды nofollow, можно сохранить вес страницы — он не будет передаваться сторонним ресурсам или другим страницам сайта, которые не приоритетны для индексации.
4. Рациональный расход краулингового бюджета.
Чем больше ресурс, тем важнее направлять робота только на самые важные страницы. Если поисковики будут сканировать все подряд, краулинговый бюджет исчерпается до того, как робот начнет сканировать ценный для пользователей и SEO-контент. Соответственно, эти страницы не попадут в индекс или окажутся там с опозданием.
Директивы метатега robots
Этот метод управления индексацией отличается синтаксисом и способом внедрения от метатега x-robots. Метатег robots размещают в html-коде страницы и заполняют его атрибуты — параметры с именем робота (name) и командами для него (content). Тег x-robots добавляют в файл конфигурации и атрибуты в этом случае не используют.
Запрет индексации контента роботом Google с помощью метатега robots выглядит так:
<meta name=«googlebot» content=«noindex» />
При этом у метатегов robots и X-Robots-Tag общие директивы — команды для обращения к роботам поисковиков. Рассмотрим список актуальных директив для разных поисковых систем и их функции.
Функции директив и их поддержка разными поисковиками
|
НАЗВАНИЕ |
ФУНКЦИЯ ДИРЕКТИВЫ |
|
YANDEX |
BING |
YAHOO! |
|
index/noindex |
Разрешение/запрет индексации текста. Чаще всего используют noindex, чтобы скрыть страницу из результатов выдачи. |
+ |
+ |
+ |
+ |
|
follow/nofollow |
Разрешение/запрет перехода роботом по ссылкам на странице. |
+ |
+ |
+ |
+ |
|
archive/noarchive |
Разрешение/запрет показа в поиске кэшированной версии страницы. |
+ |
+ |
+ |
+ |
|
all/none |
Сочетает в себе две директивы, отвечающие за индексацию текста и ссылок. all — эквивалент index, follow (используется по умолчанию). none — эквивалент noindex, nofollow. |
+ |
+ |
– |
+ |
|
nosnippet |
Запрет отображения сниппета (фрагмента текста) или видео в результатах поиска. |
+ |
– |
+ |
– |
|
max-snippet |
Ограничивает размер сниппета. Формат директивы: max-snippet:[number], где number — количество символов. |
+ |
– |
– |
+ |
|
max-image-preview |
Задает максимальный размер изображений для показа страницы в поиске. Формат директивы: max-image-preview:[setting], где setting может иметь значение none, standard или large. |
+ |
– |
– |
+ |
|
max-video-preview |
Ограничение длительности видео, которые отображаются в поиске. Значение указывают в секундах. Также можно задавать статическое изображение (0) или снимать ограничения (-1). Формат директивы: max-video-preview:[значение] |
+ |
– |
– |
+ |
|
notranslate |
Запрет перевода страницы в выдаче. |
+ |
– |
– |
– |
|
noimageindex |
Запрет индексации изображений страницы. |
+ |
– |
– |
– |
|
unavailable_after |
Запрет показа страницы в поиске после определенной даты. Директиву указывают в формате unavailable_after: [дата/время]. |
+ |
– |
– |
– |
|
noyaca |
Запрет применения описания из Яндекс.Каталога в сниппете. |
– |
+ |
– |
– |
В таблице приведены как запрещающие, так и разрешающие команды. Однако индексация «открытого» содержимого сайта происходит по умолчанию и директивы вроде index и follow можно не прописывать.
Сравнение директив Google и Яндекс
Как видно в таблице выше, у Google и Яндекса есть как общие, так и уникальные команды. В Google это nosnippet, max-snippet, max-image-preview, max-video-preview, notranslate, noimageindex, unavailable_after. В Яндексе — noyaca.
Теперь рассмотрим, какие из директив можно использовать в метатеге robots, чтобы его понимали боты Яндекса и Google.
|
Директива |
Метатег robots Google |
Метатег robots Yandex |
|
noindex |
+ |
+ |
|
nofollow |
+ |
+ |
|
noarchive |
+ |
+ |
|
index/ follow/ archive |
+ |
+ |
|
none |
+ |
+ |
|
all |
+ |
+ |
|
nosnippet |
+ |
– |
|
max-snippet |
+ |
– |
|
max-snippet |
+ |
– |
|
max-image-preview |
+ |
– |
|
max-video-preview |
+ |
– |
|
notranslate |
+ |
– |
|
noimageindex |
+ |
– |
|
unavailable_after |
+ |
– |
|
noyaca |
– |
+ |
Выполнение противоречивых команд
При комбинации директив могут возникать конфликты, когда команды противоречат друг другу, одновременно разрешая и запрещая индексацию определенного фрагмента контента. Результат обработки противоречивых директив зависит от поисковой системы: робот Google выполнит запрещающую команду, а Яндекс — разрешающую.
Рассмотрим примеры.
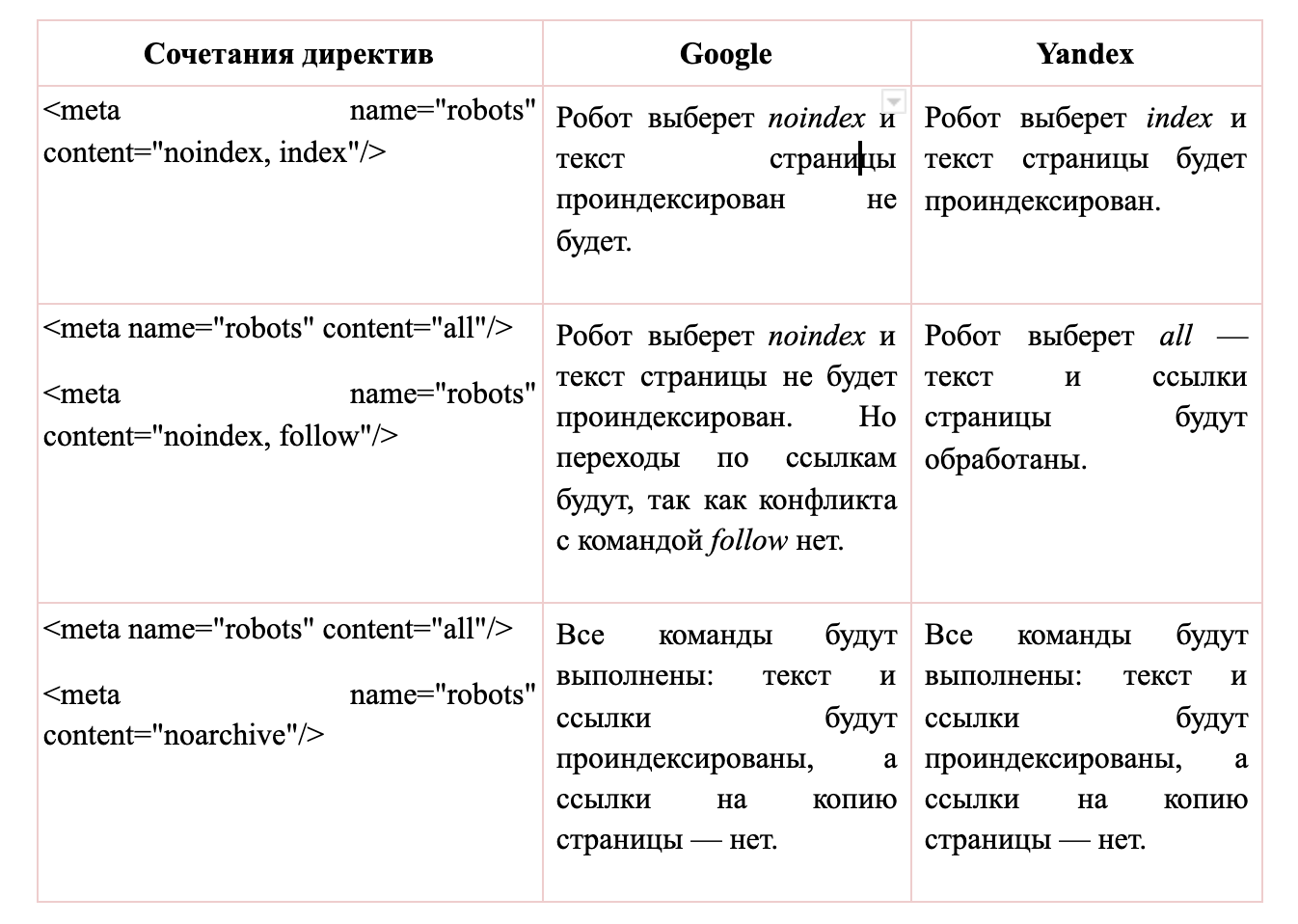
Как правильно писать метатег robots: синтаксис
Напомним, что метатег robots — это информация для робота в html-коде. Этот тег размещают в верхнем разделе <head> в html-документе и у него неизменно есть два атрибута — name и content, в которых указывают название робота и директивы для него. Атрибуты метатега всегда должны быть заполнены. В упрощенном виде он выглядит так:
<meta name=«robots» content=«noindex» />
Атрибут name
Этот параметр определяет тип метатега в зависимости от данных страницы, которые он передает поисковым системам. Например, meta name=»description» — краткое описание страницы в сниппете; meta name=»viewport» нужен для оптимизации сайта для мобильных устройств; meta http-equiv=»Content-Type» задает тип документа и его кодировки.
В случае с метатегом meta name=«robots» атрибут name содержит имя робота, для которого действуют правила, перечисленные в атрибуте content. Его функция аналогична директиве User-agent в robots.txt, содержащей идентификатор бота той или иной поисковой системы.
Значение robots используют, если нужно обратиться к краулерам всех поисковиков. Тег meta «googlebot», «yandex» или «любой другой бот» говорит о том, что инструкции адресованы соответствующему поисковому роботу. Если краулеров несколько, для каждого создают отдельный тег.
Атрибут content
Этот атрибут содержит команды, с помощью которых управляют индексированием контента на странице и отображением его элементов в результатах поиска. В него добавляют директивы из приведенных выше таблиц.
Примечания:
1. Оба атрибута не чувствительны к регистру.
2. Если значения атрибутов отсутствуют или заполнены неверно, бот проигнорирует запрет индексации. При обращении к нескольким роботам используют отдельный метатег robots для каждого.
3. Директивы атрибута content можно перечислять через запятую в одном метатеге robots.
Правила индексации через метатег robots meta и robots.txt
При обходе сайта поисковые боты в первую очередь обращаются к файлу robots.txt. В нем они получают рекомендации по сканированию страниц и затем переходят к их обработке. Поэтому если доступ к странице закрыт в файле robots.txt, робот не сможет просканировать страницу и обнаружить в коде запрет индексации.
Если страница содержит атрибут noindex, но при этом закрыта от сканирования в robots.txt, она может отобразиться в результатах поиска — например, если робот найдет страницу, перейдя по обратной ссылке из другого источника. Содержимое файла robots.txt является общедоступным, поэтому нельзя быть уверенными, что на «закрытые» страницы не будет переходов.
Следовательно, закрывая страницу от индексации метатегом robots, стоит убедиться в отсутствии препятствий для ее сканирования в файле robots.txt. К исключениям, когда robots.txt имеет смысл использовать для скрытия из индекса, относятся изображения.
Как внедрять метатег robots
1. Через html-редактор
Редактирование страниц аналогично работе с текстовым файлом. Нужно найти документ, открыть его в текстовом редакторе, добавить метатеги robots в раздел <head> и сохранить.
Страницы находятся в корневом каталоге сайта, куда можно перейти из персонального аккаунта хостинг-провайдера или по FTP. Перед внесением правок стоит сохранить исходный вариант документа.
2. Через CMS
Более простой способ закрыть страницу от индексации — через админпанель CMS. Например, SEO-плагины «All in one SEO» и «Yoast SEO» для WordPress дают возможность запретить индексацию или переходы по ссылкам в режиме редактирования страницы.
Как проверить метатег robots
Поисковой машине нужно время, чтобы проиндексировать/деиндексировать страницу. Чтобы убедиться в отсутствии страницы в поиске, нужно воспользоваться сервисом для вебмастеров или плагином для браузера, проверяющим метатеги, например, SEO META in 1 CLICK для Chrome.
Google и Яндекс дают возможность проверить наличие страницы в индексе — для этого есть инструмент «Проверка URL» Google Search Console и аналогичная опция «Проверить статус URL» в Яндекс.Вебмастере.
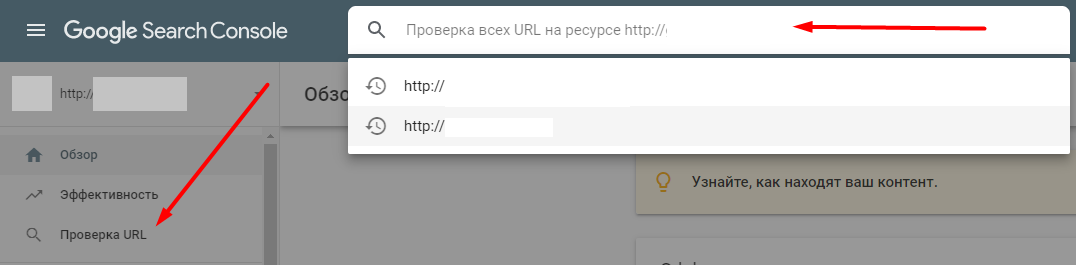
Если анализ страницы показал, что метатег robots не сработал, нужно проверить, не заблокирован ли этот URL в файле robots.txt, обратившись к этому файлу через строку браузера или используя инструмент для проверки от Google или Яндекса.
Примеры использования метатега robots
noindex
Запрет индексации текста страницы и перехода по ссылкам для всех роботов:
<meta name="robots" content=" noindex, nofollow" />
nofollow
Запрет перехода по ссылкам на странице роботу Яндекса:
<meta name="yandex" content="nofollow" />
noarchive
Запрет показа в поиске кэшированной версии страницы в разделе Яндекс.Новости:
<meta name="yandexnews" content="noarchive"/>
none
Запрет индексации и перехода по ссылкам для googlebot в html-документе:
<meta name="googlebot" content="none" />
nosnippet
Запрет отображение фрагментов страницы в результатах поиска Google:
<meta name="robots" content="nosnippet">
max-snippet
Ограничение длины сниппета до 35 символов:
<meta name="robots" content="max-snippet:35">
max-image-preview
Показ крупных изображений страницы в результатах поиска:
<meta name="robots" content="max-image-preview:large">
max-video-preview
Отображение видео в поиске без ограничений по длительности:
<meta name="robots" content="max-video-preview:-1">
notranslate
Запрет перевода страницы на другие языки:
<meta name="robots" content="notranslate" />
noimageindex
Запрет индексации картинок страницы:
<meta name="robots" content="noimageindex" />
unavailable_after
Отсроченный запрет индексации (после 1 января 2021 года):
<meta name="robots" content="unavailable_after: 2021-01-01">
noyaca
Запрет использования автоматически сгенерированного описания:
<meta name="yandex" content="noyaca" />
Ошибки использования robots
1. Несогласованность с файлом robots.txt.
У поискового робота должен быть доступ к сканированию контента, который нужно скрыть из индекса. В этом случае указание директивы disallow для определенной страницы в файле robots.txt делает невидимыми директивы страницы, в том числе запрещающие индексацию.
Еще одной ошибкой является попытка запретить индексацию страниц с помощью robots.txt. Основная функция robots.txt — в ограничении сканирования, а не запрете индексации. Следовательно, для управления отображением страниц в поиске нужно использовать метатег robots.
2. Несвоевременное удаление атрибута noindex с актуальной страницы.
Если вы используете директиву noindex, чтобы временно скрыть контент из индекса, важно вовремя удалить ее со страницы и открыть роботу доступ. Например, это может быть страница с запланированным акционным предложением, которое уже вступило в силу. Или же страница, которая была в процессе разработки и теперь полностью готова. Если директиву не убрать, страница не появится в выдаче, а значит не будет генерировать трафик.
3. Наличие обратных ссылок на страницу с атрибутом nofollow.
Команда nofollow может не сработать, если сама страница — не единственный способ для поисковика узнать об URL-адресах, и на них ведут внешние ссылки с «открытых» источников.
4. Удаление URL-адреса из карты сайта до его деиндексации.
Если страница содержит директиву noindex или отдает запрет индексации URL, стоит ли ее удалить из файла sitemap.xml? Такое решение будет неверным, поскольку карта сайта дает роботу возможность быстрее находить все страницы, в том числе те, которые нужно убрать из индекса.
Правильным решением будет создать отдельный файл sitemap.xml со списком страниц, содержащих директивы noindex, и удалять URL оттуда по мере их деиндексации. Чтобы ускорить процесс обхода дополнительной карты сайта роботом, можно загрузить ее в Google Search Console.
5. Отсутствие проверки индексации после внесения изменений.
При самостоятельной настройке индексации или в ходе работы программиста бывают ситуации, когда важный контент ошибочно оказался под запретом индексации. После внесения изменений страницы сайта нужно проверять.
Как быть, если актуальная страница перестала отображаться в поиске?
Необходимо удалить директивы, запрещающие индексацию страницы, а также проверить, нет ли запрета ее сканирования командой disallow в robots.txt и указан ли ее адрес в файле sitemap. Запросить индексацию URL, а также уведомить поисковики об обновленной карте сайта можно через Яндекс.Вебмастер и Google Search Console.
Метатег robots — это инструмент для управления индексацией и отображением страниц сайта в результатах поиска. Способ реализации: метатег robots указывают в коде страницы. Также у него есть и другие особенности:
- если robots.txt отвечает за сканирование страниц роботом, то meta robots влияет на попадание контента в индекс поисковиков. Его настройка является частью технической оптимизации;
- если в файле robots.txt стоит запрет сканирования страницы, директива метатега robots для нее не сработает;
- ошибки в настройках метатега robots могут привести к попаданию нежелательных страниц в индекс и проблемам в работе сайта. Вносить правки нужно внимательно или доверить это вебмастеру.
Читайте также наш материал, как сделать robots.txt для wordpress.
Похожие вопросы


Похожие вопросы
-

Google Search Console
Как работать в Google Search Console. Советы и рекомендации12 вопросов -

SEO пузомерки
Ключевые метрики SEO: где и как смотреть6 вопросов -

Линкбилдинг
Все про построение ссылочного профиля, крауд-маркетинг и аутрич10 вопросов -

Для опытных
Вопросы для продвинутых SEO-специалистов и новые подходы в SEO12 вопросов -
Аналитика
Вопросы по Google Tag Manager, Google Analytics6 вопросов -

Контент
Вопросы по SEO-копирайтингу. Какими должны быть SEO-тексты4 вопроса -

Другое
Общие вопросы по SEO. Все, что связано с поисковой оптимизацией1 вопрос