Как проверить robots.txt на ошибки
Файл robots.txt — это инструкция для поисковых роботов. В нем указывается, какие разделы и страницы сайта могут посещать роботы, а какие должны пропускать. В данном материале разберем, зачем нужен этот файл, как делать анализ robots.txt с помощью стандартных инструментов Google, а также с помощью программ и онлайн-сервисов.
Поисковые роботы, краулеры, начинают знакомство с сайтом с чтения файла robots.txt. В нем содержится вся важная для них информация. Владельцам сайтов следует создать и периодически проводить анализ robots.txt. От корректности его работы зависит скорость индексации страниц и место в поисковой выдачи.
Зачем нужен robots.txt?
Поисковые роботы — это программы, которые сканируют содержимое сайтов и заносят их в базы поисковиков Google и других систем. Этот процесс называется индексацией.
Файл robots.txt содержит информацию о том, какие разделы нельзя посещать поисковым роботам. Это нужно для того, чтобы в выдачу не попадало лишнее: служебные и временные файлы, формы авторизации и т. п. В поисковой выдаче должен быть только уникальный контент и элементы, необходимые для корректного отображения страниц (изображения, CSS- и JS-код).
Если на сайте нет robots.txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
Если же файл есть в корневой папке сайта на хостинге, роботы сначала обращаются к прописанным в нём правилам. Они узнают, куда нельзя заходить, а какие страницы/разделы обязательно нужно посетить. И только после этого начинают обход сайта по инструкции.
Как сделать robots.txt для Wordpress, читайте в нашем материале.
Веб-разработчикам следует создать файл, если его нет, и наполнить его правильными директивами (командами) для поисковых роботов.
Как проверить robots.txt с помощью инструментов для вебмастеров?
Чтобы убедиться в том, что файл составлен грамотно, можно использовать веб-инструменты Google, онлайн-сервисы, программы для seo-анализа текстов. В Google есть собственные правила для проверки robots.txt.
Проводите анализ robots.txt с помощью инструментов для разработчиков, например, через Google Robots Testing Tool.
Важно! Google проверяет только соответствие файла собственным требованиям. Если для одной поисковой системы файл корректный, это не значит, что он будет корректным для роботов Google, поэтому проверяйте в разных системах.
Если вы найдете ошибки и исправите robots.txt, краулеры не считают изменения мгновенно. Обычно переобход страниц осуществляется один раз в день, но часто занимает гораздо большее время. Проверьте через неделю файл, чтобы убедиться, что поисковики используют новую версию.
Google Robots Testing Tool
Чтобы сделать проверку robots.txt с помощью инструмента Google Search Console:
Шаг 1. Перейдите на страницу инструмента проверки Google Robots Testing Tool.
Шаг 2. Если на открывшейся странице отображается неактуальная версия robots.txt, нажмите кнопку Отправить и следуйте инструкциям Google:
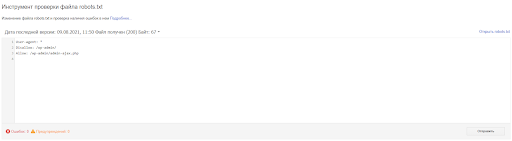
Шаг 3. В следующем окне есть три варианта на выбор:
- можно скачать файл (скачайте обновленный файл robots.txt из редактора);
- проверить добавленную версию (добавьте обновленный файл robots.txt в корневой каталог домена и проверьте, выбран ли он для использования роботами Google);
- отправить в Google запрос на обновление (сообщите Google о том, что вы обновили файл robots.txt).
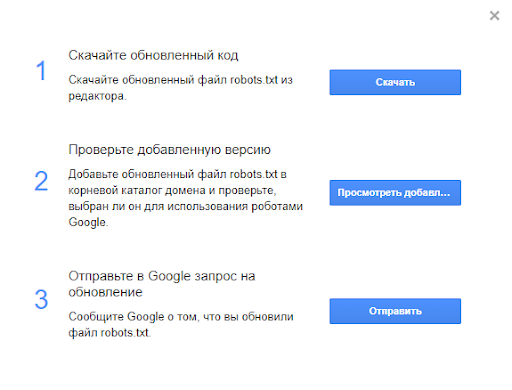
Шаг 4. Ну а если отображается актуальная версия, то в поле будут отображаться актуальные директивы. Предупреждения/ошибки (если система найдет их) будут перечислены под кодом.
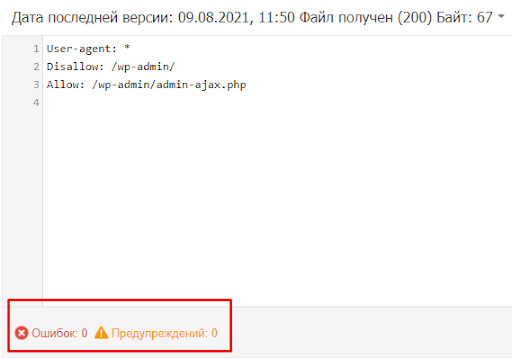
Важно! Правки, которые вы вносите в сервисе проверки, не будут автоматически применяться в robots.txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
Как проверить robots.txt с помощью сервисов
Рассмотрим несколько сервисов для проверки роботса.
Website Planet
Шаг 1. Перейдите на сайт сервиса Website planet →
Шаг 2. Вставьте URL-адрес по которому открывается robots.txt и нажмите Проверить.
Шаг 3. Через некоторое время получите результаты анализа.
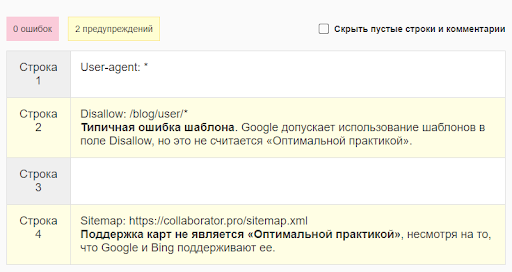
Majento
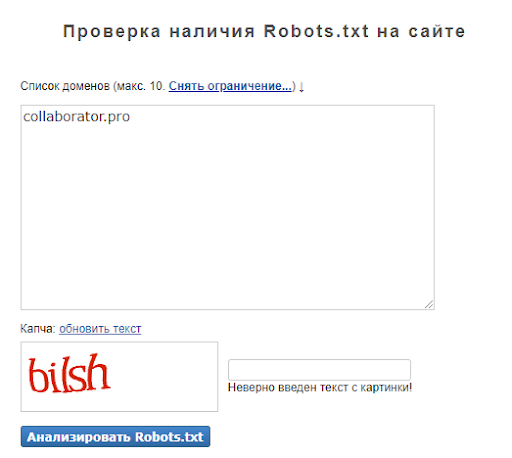
Шаг 1. Перейдите на сайт сервиса Majento →
Шаг 2. Вставьте URL-адрес по которому открывается robots.txt и нажмите Анализировать robots.txt.
Шаг 3. Через некоторое время получите результаты анализа.

Technicalseo
Шаг 1. Перейдите на сайт сервиса Technicalseo →
Шаг 2. Вставьте URL-адрес по которому открывается robots.txt, выберите тип бота Googlebot и нажмите TEST.

Шаг 3. Через некоторое время получите результаты анализа.
Ryte
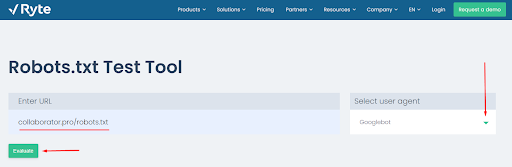
Шаг 1. Перейдите на сайт сервиса Ryte →
Шаг 2. Вставьте URL-адрес, по которому открывается robots.txt, выберите тип бота Googlebot и нажмите Evaluate.
Шаг 3. Через некоторое время, получите результаты анализа.
Robots.txt Validator
Расширение для браузера Chrome.
Шаг 1. Перейдите чтобы скачать расширение Robots.txt Validator →
Шаг 2. Вставьте URL-адрес, по которому открывается robots.txt, выберите тип бота Googlebot и нажмите Evaluate.
Шаг 3. Через некоторое время получите результаты анализа.
Как проверить robots.txt с помощью программ
Рассмотрим два варианта проверки через краулеры.
Screaming Frog SEO Spider
Шаг 1. Перейдите чтобы скачать SEO Spider Tool →
Шаг 2. Откройте программу, в верхнем меню выберите раздел Configuration→ robots.txt→ Custom
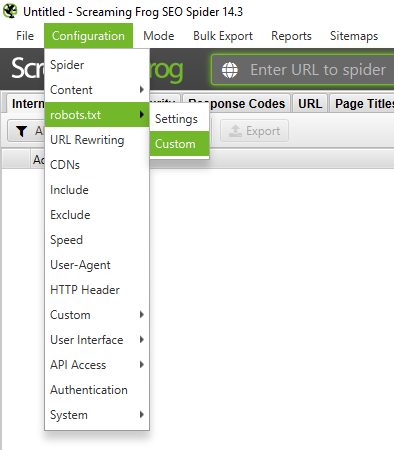
Шаг 3. Далее нужно добавить свой домен. Для этого нажмите на кнопку Add и введите адрес в строку. Нажмите ОК.
Шаг 4. После этого можем увидеть директивы роботса, отредактировать его здесь и скачать. Нажимаем кнопку Test.
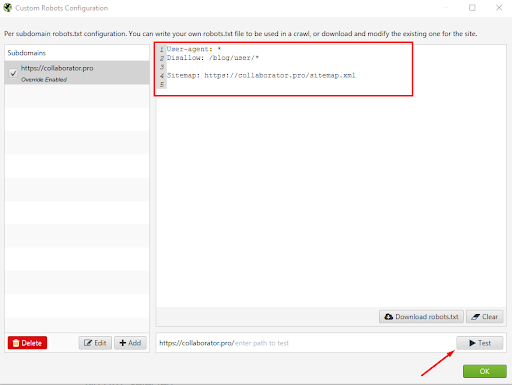
И получаем мгновенно результат анализа и проверки.
Netpeak Spider
Встроенная функция «Виртуальный robots.txt» позволяет протестировать новый или обновлённый robots.txt, не меняя действующий файл в корневой директории сканируемого сайта.
Шаг 1. Чтобы настроить виртуальный robots.txt, необходимо перейти в «Настройки» → вкладка «Виртуальный robots.txt», отметить галочкой «Использовать виртуальный robots.txt», задать свои инструкции и сохранить настройки, нажав ОК.
Чтобы приступить к тестированию составленного вами виртуального файла robots.txt, в поле «Начального URL» на панели управления введите адрес сайта и запустите сканирование кнопкой «Старт».
Вы можете воспользоваться функциями:
- Копировать → для сохранения в буфер обмена содержимого окна;
- Сохранить (Alt+S) → для записи виртуального файла robots.txt в формате текстового документа на ваше устройство;
- Вставить → помещает текст из буфера обмена;
- Очистить → для удаления содержимого всего окна.
Значения, актуальные для прописанного вами виртуального файла, отобразятся в колонках основной таблицы:
- «Код ответа сервера» → если доступ к странице запрещён директивой в robots.txt, к коду ответа сервера прибавляется частица «Disallowed».
- «Разрешён в robots.txt» → отображается значение «TRUE», если доступ к странице разрешён директивой Allow или в файле не содержится инструкций, запрещающих индексировать страницу — в противном случае отображается значение «FALSE».
- «Директива из robots.txt» → показывает, какой именно директивой разрешён или запрещён доступ к странице, а также её порядковый номер в файле. Если такой инструкции нет, то отображается значение «(NULL)».
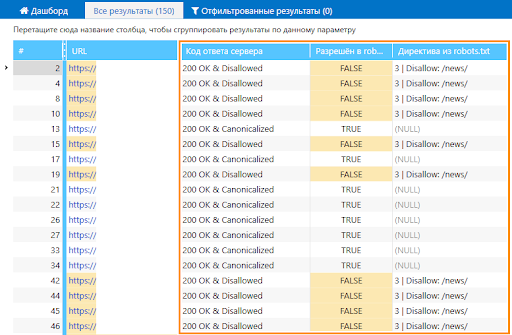
Чтобы краулер следовал указанным инструкциям, необходимо активировать учёт инструкций в robots.txt на вкладке «Продвинутые» в настройках программы.
Важно! Если опция «Виртуальный robots.txt» отключена, то программа будет следовать инструкциям и отображать их из настоящего файла robots.txt. На результат сканирования будет также влиять выбранный вами User Agent.
Что нужно запомнить:
- Файл robots.txt помогает поисковым роботам индексировать сайт. Закрывайте сайт во время разработки, в остальное время — весь сайт или его часть должны быть открыты. Корректно работающий файл должен отдавать ответ 200.
- Файл создается в обычном текстовом редакторе. Во многих CMS в административной панели предусмотрено создание файла. Следите, чтобы размер не превышал 32 КБ. Размещайте его в корневой директории сайта.
- Заполняйте файл по правилам. Начинайте с кода «User-agent:». Правила прописывайте блоками, отделяйте их пустой строкой. Соблюдайте принятый синтаксис.
- Разрешайте или запрещайте индексацию всем краулерам или избранным. Для этого укажите название поискового робота или поставьте значок *, который означает «для всех».
- Работайте с разными уровнями доступа: сайтом, страницей, папкой или типом файлов.
- Включите в файл указание на главное зеркало с помощью постраничного 301 редиректа и на карту сайта с помощью директивы sitemap.
- Для анализа robots.txt используйте инструменты для разработчиков. Это Google Robots Testing Tools. Сначала подтвердите права на сайт, затем сделайте проверку. В Google сразу отредактируйте файл в веб-редакторе и уберите ошибки. Отредактированные файлы не сохраняются автоматически. Загружайте их на сервер вместо первоначального robots.txt. Через неделю проверьте, используют ли поисковики новую версию.
- Также проверяйте с помощью ПО.
Читайте также наш материал, как проверить карту сайта sitemap.xml на ошибки.


Похожие вопросы
-

Google Search Console
Как работать в Google Search Console. Советы и рекомендации12 вопросов -

SEO пузомерки
Ключевые метрики SEO: где и как смотреть6 вопросов -

Линкбилдинг
Все про построение ссылочного профиля, крауд-маркетинг и аутрич10 вопросов -

Для опытных
Вопросы для продвинутых SEO-специалистов и новые подходы в SEO12 вопросов -
Аналитика
Вопросы по Google Tag Manager, Google Analytics6 вопросов -

Контент
Вопросы по SEO-копирайтингу. Какими должны быть SEO-тексты4 вопроса -

Другое
Общие вопросы по SEO. Все, что связано с поисковой оптимизацией1 вопрос