Как узнать историю сайта из веб-архива
История сайтов полезна вебмастерам при покупке доменов, чтобы вычислить возраст, узнать важные показатели и отделить хорошие от плохих. Ведь фильтры и баны в прошлом напрямую влияют на продвижение сайта в будущем. Поэтому стоит покупать новые домены либо домены с положительной историей.
Как узнать возраст сайта и домена, мы писали в другом материале.
Что такое Web Archive?
Web Archive — это бесплатный сервис, где собраны истории многих интернет ресурсов — их архивные копии. Причем речь идет не о скриншотах, а о полноценных страницах с изображениями, рабочими ссылками и стилевым оформлением.
Веб-архив основан в начале 1996 года и с этого времени в нем сохранено более 330 миллиардов веб-страниц, включая 20 миллионов книг, 4,5 миллионов аудиофайлов и 4 миллиона видео, занимающие свыше тысячи терабайт. Ежедневно сайт посещают миллионы пользователей, и он входит в ТОП-300 самых популярных проектов мира.
Получение информации о том или ином домене предполагает не только интересное времяпровождение с отслеживанием эволюции веб-проекта, но еще и возможность:
- узнать тематику сайта — архив интернета демонстрирует содержимое, благодаря чему легко определить нишу проекта;
- посмотреть, как выглядел сайт раньше, вплоть до конкретной даты — это находка для охотников за б/у доменами;
- определить, регистрировался ли до этого анализируемый домен — полезный инструмент для тех, кому принципиальна «стерильность» домена или для того чтобы избежать санкций поисковиков;
- восстановить свой сайт, если вы почему-то не сделали резервное копирование;
- отыскать уникальный контент — трудоемкая задача, которая может подарить вам десятки бесплатных статей;
- увидеть удаленный текст из закладок — шансы найти нужную страницу достаточно высоки.
Зачем нужна история сайта
Хронография домена зачастую выдаёт информацию о нём с момента создания. Виртуальные архивы сайтов также дают возможность узнать:
- сколько времени существует домен;
- наличие банов, фильтров, санкций в прошлом, действуют ли они сейчас;
- количество владельцев ресурса;
- другие домены в пределах сервера, на котором был сайт.
Бывает так, что анализ трафика показал, что при прошлом дизайне сайт приносил больше прибыли. Сравнение текущей и прошлой версий одного ресурса позволяет сделать соответствующие выводы и улучшить работу.
В отличие от старых доменов, новые всегда обладают чистой историей, ведь у них не было владельцев, и они не были зарегистрированы как сайты. Такие домены покупают, не боясь столкнуться с фильтрами и другими проблемами. Однако многие вебмастера предпочитают покупать готовые сайты с рук или на аукционах. Причина здесь одна: старый домен с хорошей историей легче продвинуть в поиске, чем начинать оптимизацию с чистого листа.
При покупке старого сайта нужно тщательно проверять его прошлое. Важно, чтобы на сайте не было ворованного контента, запрещённых тематик и банов по причине любых нарушений.
Принципы работы веб-архивов
Веб-архивы время от времени посещают открытые к доступу сайты. При одном таком посещении автоматически создаются точные копии страниц, которые сохраняются на сервере архива. Под каждой копией отмечается дата. Дальше любой пользователь может восстановить нужную версию сайта через календарь.
Как пользоваться веб-архивом и посмотреть историю сайта
Самый крупный ресурс, на котором хранится история большинства сайтов, — Webarchive. Иногда этот сервис называют машиной времени сайтов или Wayback Machine. Здесь можно посмотреть даже историю тех ресурсов, которые давно прекратили существование.
Чтобы посмотреть историю сайта нужно:
1. Перейти на сайт Web Archive →
2. Введите в поле название интересующего вас сайта и нажмите Enter (в нашем случае это https://collaborator.pro).
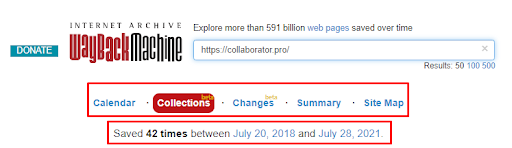
3. Под указанным доменным именем демонстрируется основная информация: когда начинается история проекта, сколько слепков имеет сайт. В примере видно, что ресурс был впервые архивирован 20 июля 2018 года по июль месяц 2021 года, библиотека хранит его 42 архивные копии.
Также здесь есть вкладки:
- сводка;
- календарь;
- коллекции;
- изменения;
- карта сайта.
4. Дальше мы обращаем внимание на гистограмму активности по годам — черным цветом выделено динамику.

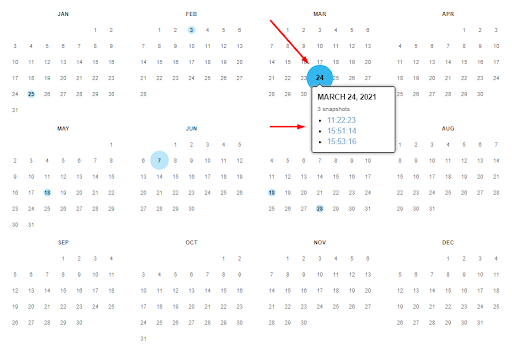
5. Ниже есть календарь по выбранному году — голубым цветом в нем отмечены даты создания слепков.
Каждый слепок доступен для просмотра: нужно лишь выбрать год, месяц и день сохранения. Мы хотим посмотреть, как выглядел сайт раньше: допустим, 24 марта текущего года. Наводим курсор на голубой кружок и жмем на время сохранения и в новом окне получаем информацию.
Вот так он выглядел:
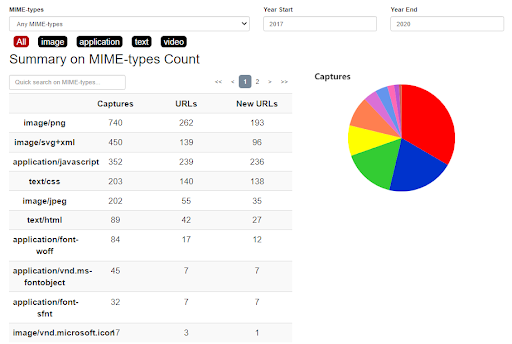
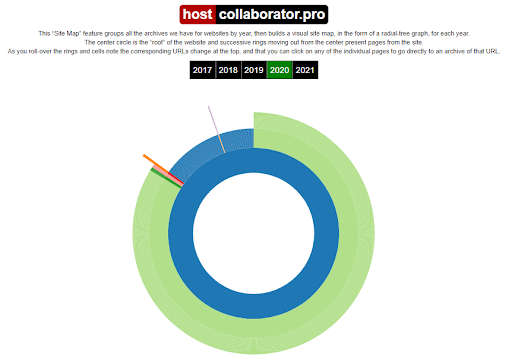
6. При желании можно получить общие данные о web-проекте — надо нажать на кнопку Summary над хронологической таблицей и календарем или же ознакомиться с картой сайта (кнопка Site Map).
Алгоритм действий можно сократить. Для работы с сервисом напрямую, введите в строке своего браузера:
http://web.archive.org/web/*/http://url
В нашем случае вышло:
http://web.archive.org/web/*/https://collaborator.pro/
Как сделать так, чтобы сайт не попал в библиотеку веб-архива?
Если вы дорожите контентом и не хотите видеть свою онлайн-площадку в электронной библиотеке, пропишите запретную директиву в файле robots.txt:
User-agent: ia_archiver Disallow: /
User-agent: ia_archiver-web.archive.org Disallow: /
После изменения в настройках веб-сканер перестанет создавать архивные копии вашего сайта, к тому же удалит уже сделанные слепки. Однако учтите, что ваш запрет действует лишь до тех пор, пока доступен robots.txt — когда закончится срок регистрации доменного имени, машина времени сайтов станет демонстрировать статьи всем желающим.
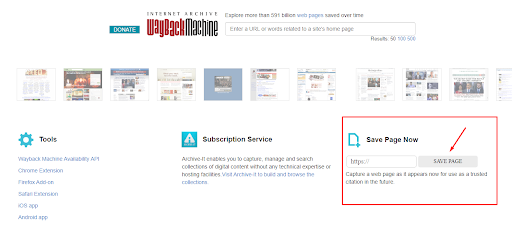
Важно! Если вы, наоборот, желаете активно пользоваться веб-архивом, введите соответствующий запрос на главной странице сервиса. Просто укажите адрес проекта в разделе Save Page Now, после чего нажмите кнопку Save Page. Повторяйте процедуру после внесения любых правок.
Что важно помнить:
- Веб-архив — масштабный бесплатный проект, созданный для сохранения всего контента, представленного в интернете, даже после его удаления на исходном сайте.
- Веб-архив полезен для анализа сайтов клиентов и конкурентов, отслеживания изменений на собственном проекте, проверки доменов перед покупкой.
- Используя данные веб-архива, полученные с помощью онлайн-сервисов, доступно восстановление сайта без бэкапа.
- В веб-архиве много контента, в том числе уникальные статьи почти на любую тематику.
Похожие вопросы


Похожие вопросы
-

Google Search Console
Как работать в Google Search Console. Советы и рекомендации12 вопросов -

SEO пузомерки
Ключевые метрики SEO: где и как смотреть6 вопросов -

Линкбилдинг
Все про построение ссылочного профиля, крауд-маркетинг и аутрич10 вопросов -

Для опытных
Вопросы для продвинутых SEO-специалистов и новые подходы в SEO12 вопросов -
Аналитика
Вопросы по Google Tag Manager, Google Analytics6 вопросов -

Контент
Вопросы по SEO-копирайтингу. Какими должны быть SEO-тексты4 вопроса -

Другое
Общие вопросы по SEO. Все, что связано с поисковой оптимизацией1 вопрос