Как настроить файл robots.txt: полное руководство

Попробуйте Collaborator.pro
Выберите из 36192 высококачественных веб-сайтов и 3406 Telegram каналов
Вперёд
- Что такое robots.txt
- Формат и расположение файла
- Синтаксис robots.txt
- Как закрыть сайт от индексации через Disallow
- Сервисы и инструменты для генерации robots.txt онлайн
- Как сделать правильный robots.txt для разных CMS
- Как проверить файл robots.txt
- Можно ли не создавать robots.txt
- Примеры стандартных правил для robots.txt
- Самые частые вопросы о файле robots.txt
Техническая оптимизация — фундамент, на котором держится успешное продвижение сайта в поисковых системах. Многие вебмастера не уделяют внимание склейке зеркал, настройке HTTPS протокола и другим стандартным задачам по техничке, а потом удивляются, что проект не может набрать видимость.
Прежде чем запускать активное продвижение сайта в Яндексе и Гугле, необходимо довести его до идеального состояния по всем параметрам. Это касается скорости загрузки, корректного отображения на мобильных устройствах, отсутствия критических ошибок в HTML-вёрстке, настройки .htaccess и технических файлов.
В этой статье поговорим о том:
- Как составить robots.txt?
- Как правильно настроить robots.txt?
- Как найти на сайте robots.txt?
- Как работать с robot.txt?
- Для чего нужен файл robots.txt?
- Как правильно настроить robots.txt?
- Что должно быть написано в robots.txt?
- Как редактировать файл robots.txt?
- Как прописать карту сайта в robots.txt?
Заварите кофе или налейте кружку ароматного чая 🍵 и погнали!
Что такое robots.txt
Файл robots.txt — текстовый документ, в котором собраны правила для роботов поисковых систем и других сервисов. Краулеры сканируют файл и понимают, какой контент владелец сайта хочет добавить или исключить из поисковой выдачи.
Если опустить технические подробности, то robots.txt — список рекомендаций для поисковых спайдеров. При обходе страниц они учитывают загруженные ранее правила и периодически проверяют документ на обновления.
В идеальном мире правильный robots помогает улучшить индексацию за счёт того, что в поисковую выдачу не попадают мусорные страницы. В SERP остаются качественные посадочные, вес не размывается и сайт хорошо набирает видимость по тематическим запросам.

Проблема в том, что роботы поисковиков воспринимают файл robots как рекомендацию. Они сканируют содержимое файла, но самостоятельно принимают решение о добавлении страниц в выдачу. Поэтому если хотите получить 100% гарантию запрета индексации, используйте дополнительные инструменты, которые позволяют управлять поведением краулеров. Например, метатег robots.
Многие вебмастера допускают одну ошибку — они используют robots.txt для перечисления страниц, которые необходимо скрыть от пользователей. При этом в справке Google чётко написано, что файл предназначен для управления трафиком поисковых роботов.
Главное предназначение документа — управление сканированием веб-страниц. Можно указать роботам, что определённую директорию нет смысла сканировать, потому что она бесполезна для аудитории. Если всё настроено правильно, краулеры не будут тратить ресурсы и нагрузка на сайт может снизиться.
Крупные сайты на тысячи и десятки тысяч страниц с помощью robots.txt экономят краулинговый бюджет. Они сигнализируют роботам, что можно не обходить определённые адреса и улучшают индексацию. Краулеры переходят только по нужным страницам, добавляют их в базу и со временем они появляются в выдаче.
Формат и расположение файла
Robots.txt — обычный текстовый файл, который должен лежать в корне сайта. Если залить его не в корневую директорию, поисковые роботы не будут загружать содержимое и все правила станут бесполезными.
Требования к robots у поисковых систем примерно одинаковые:
- кодировка UTF-8 без BOM сигнатур;
- файл доступен для роботов;
- сервер отдаёт статус «200 OK»;
- размер до 500 КБ;
- один файл для домена;
- название «robots.txt» без заглавных букв и кириллицы;
- если домен кириллический адреса в файле необходимо указывать в формате Punycode;
- каждая директива начинается с новой строки;
- в группе правил указывается релевантный User-agent;
- отсутствие конфликтов между директивами.
Даже новичок сможет правильно настроить robots.txt, если вникнет в базовые особенности и будет использовать онлайн-инструменты для проверки корректности содержимого файла. Валидаторы пригодятся и опытным специалистам, особенно, если в документе прописаны сотни строк.
Синтаксис robots.txt
Robots.txt используется в интернет-пространстве с 1994 года, некоторые правила уже неактуальны, но есть атрибуты, которые нельзя игнорировать. Это касается директив и часто используемых символов. Критические ошибки в синтаксисе файла могут привести к тому, что в индексе окажется большое количество мусорных страниц или нагрузка на сервер сильно увеличится и сайт упадёт.
Работу с robots.txt можно условно разбить на 3 направления: символы, директивы и правильное форматирование. Разберёмся с каждым пунктом последовательно, чтобы закрыть все вопросы новичков и освежить знания опытных вебмастеров.
В файле используются 4 символа:
- * указывает на любую возможную вариацию значения;
- # комментарии, которые игнорируют поисковые роботы.
- $ отменяет * на конце правила;
- / указывает краулеру, что правило применяется для директории.
Ниже доступна полная таблица директив для Яндекса и Гугла. Уделите ей максимум внимания, если путаетесь в них или до этого момента не знали, за что каждая из них отвечает.
|
Директива |
Описание |
Поддержка |
|
User-agent |
Указывает на робота, для которого создано правило |
Yandex |
|
Disallow |
Запрещает сканирование страниц или директорий |
Yandex |
|
Allow |
Разрешает сканирование страниц или директорий |
Yandex |
|
Sitemap |
Указывает путь к файлу с картой сайта, которая содержит список всех страниц |
Yandex |
|
Clean-param |
Указывает роботу, что URL страницы содержит параметры, которые не нужно учитывать при индексировании |
Yandex |
|
Crawl-delay |
Задает роботу минимальный период времени в секундах между окончанием загрузки одной страницы и началом загрузки следующей |
Устарела, Yandex рекомендует использовать инструмент «Скорость обхода» в Вебмастере |
|
Host |
Указывает главное зеркало для поисковых роботов |
Устарела, используйте 301 редирект |
Что касается правильного форматирования, то рекомендаций немного:
- каждая директива начинается с новой строки и содержит один параметр;
- нижний регистр для правил;
- нельзя использовать пробел в начале строки, кавычки и точки с запятой для директив;
- нельзя оставлять robot.txt пустым;
- в каждом правиле должна быть минимум одна директива Allow или Disallow;
- директиву Sitemap можно повторять несколько раз, например, указывать разные карты сайтов для Яндекса и Гугла.
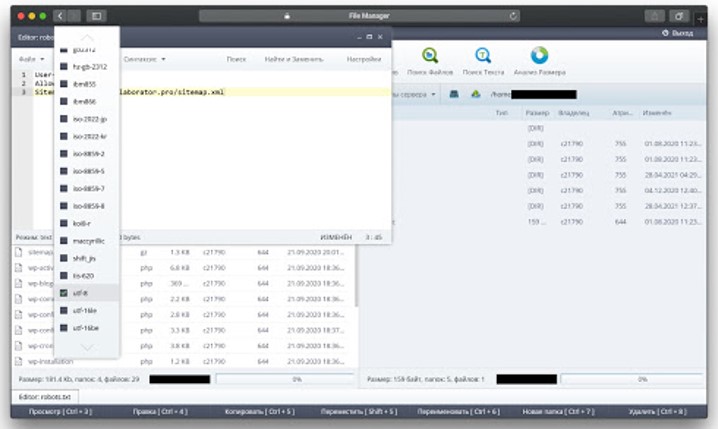
На скриншоте ниже доступен пример стандартного файла robots.txt с указанием распространённых директив. Если на сайте нет мусорных страниц, вполне можно использовать его для рабочего проекта.
Как закрыть сайт от индексации через Disallow
У вебмастеров и оптимизаторов периодически возникает необходимость полностью закрыть сайт от сканирования или ограничить доступ к определённым страницам. Для этого в robots.txt добавляется правило Disallow all и когда технические работы завершены, запрет можно снять.
В каких случая нужно закрывать сайт от индексации:
- ограничивать сканирование проекта для роботов стоит когда сайт ещё не готов для продвижения (новый сайт);
- выполняется переезд на новое зеркало;
- есть необходимость создать зеркало сайта (например, для партнеров).
В этих случаях в корень проекта ложат файл с двумя строчками. Первая указывает, что правило актуально для всех роботов, а вторая ограничивает сканирование страниц и директорий.
User-agent: * Disallow: /
Учитывайте, что такой robots актуален только для одного домена или поддомена, если он лежит в корне. Если работаете с 5-10 поддоменами, создавайте файл для каждого адреса, так как поддомены воспринимаются как отдельные сайты.
Что рекомендуется закрывать от роботов:
- Дубли страниц, которые генерирует CMS или плагины.
- Страницы с конфиденциальной информацией. Например, личный кабинет,
- Служебные файлы CMS.
- Служебные страницы. Например, корзину, форму заказа, избранное.
- Адрес административной панели.
- Страницы с динамическими параметрами.
- Посадочные без полезного для пользователей контента.
- Пагинацию (опционально).
- Теги (опционально).
Несколько лет назад вебмастера использовали директиву Host в Яндексе, чтобы указать поисковым роботам главное зеркало. Сейчас надо настраивать 301 редирект для склейки зеркал, потому что директива устарела, а Google её не распознает.
Полностью закрывать сайт от индексации необходимо только в исключительных случаях. Многие оптимизаторы забывают открыть доступ краулерам после завершения технических работ.
Сервисы и инструменты для генерации robots.txt онлайн
Проще всего создать robots.txt с помощью генераторов, которые позволяют сократить время на выполнении рутинных задач. Если уверены в своих знаниях, прописывайте правила самостоятельно, потому что возможности редакторов не безграничны.
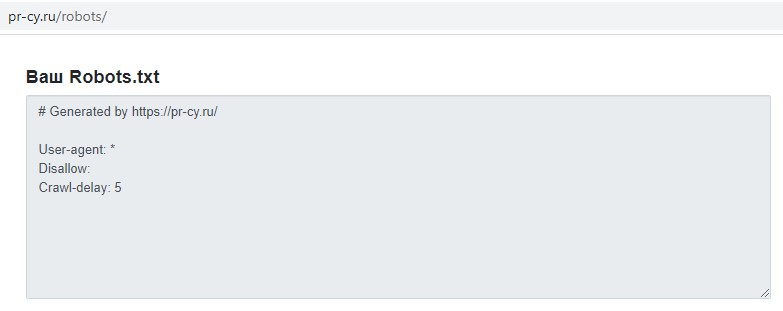
Например, в популярном сервисе SEO-анализа PR-CY можно прописать только правила для запрета сканирования. Если понадобится открыть для обхода картинки или PDF файлы, придётся редактировать содержимое самостоятельно.
В настройках можно указать поисковых роботов, но снятие галочек не влияет на созданные правила, потому что сервис генерирует шаблон для всех роботов, а не указывает конкретных краулеров.
Среди популярных инструментов для генерации robots.txt ещё можно выделить SEOlib и IKSWEB. Для зарубежных проектов можно использовать западные сервисы, но в них не будет Яндекса.
Если хотите создать разные правила для 2-3 поисковых систем, то сервисы будут полезны только для генерации «ядра». Содержимое всё равно придётся подгонять под свои задачи, потому что сервисы далеко не идеальны.
Как сделать правильный robots.txt для разных CMS
У каждой системы управления контентом свои особенности и под неё нужны соответствующие правила, которые помогут ограничить сканирование служебных страниц и файлов роботами поисковиков. Универсальный вариант, открывающий доступ ко всем страницам можно использовать, только если закрыли доступ к мусорным страницам другими способами.
Мы подготовили шаблоны robots.txt для запрета индексации страниц и разделов, которые не влияют на пользовательский опыт. Используйте готовые правила и добавляйте свои, чтобы создать идеальный файл под свой проект.
Wordpress
User-agent: * Allow: / #Robots WordPress Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Disallow: /tag #WordPress end
OpenCart
User-agent: * Allow: / #Robots Opencart Disallow: /*route=account/ Disallow: /*route=affiliate/ Disallow: /*route=checkout/ Disallow: /*route=product/search Disallow: /index.php?route=product/product*&manufacturer_id= Disallow: /admin Disallow: /catalog Disallow: /download Disallow: /export Disallow: /system Disallow: /*?sort= Disallow: /*&sort= Disallow: /*?order= Disallow: /*&order= Disallow: /*?limit= Disallow: /*&limit= Disallow: /*?filter_name= Disallow: /*&filter_name= Disallow: /*?filter_sub_category= Disallow: /*&filter_sub_category= Disallow: /*?filter_description= Disallow: /*&filter_description= Disallow: /*?tracking= Disallow: /*&tracking= Disallow: /*?page= Disallow: /*&page= Disallow: /wishlist Disallow: /login Disallow: /index.php?route=product/manufacturer Disallow: /index.php?route=product/compare Disallow: /index.php?route=product/category #Robots Opencart end
1С-Битрикс
User-agent: * Allow: / #Robots Bitrix Disallow: /*nav-* Disallow: /bitrix/ Disallow: /upload/ Disallow: /local/ Disallow: /search/ Disallow: /compare/ Disallow: /personal/ Disallow: /rss/ Disallow: /auth/ Disallow: /login/ Disallow: /webstat/ Disallow: /desktop_app/ Disallow: /ajax/ Disallow: /test/ Disallow: /404.php Disallow: /*index*.php$ Disallow: */index.php Disallow: /*?* Allow: /bitrix/components/ Allow: /bitrix/templates/ Allow: /local/components/ Allow: /local/templates/ Allow: /bitrix/cache/ Allow: /bitrix/css/ Allow: /bitrix/js/ Allow: /bitrix/images/ Allow: /bitrix/panel/ Allow: /upload/iblock/ Allow: /upload/medialibrary/ Allow: /upload/resize_cache/main/ Allow: /upload/resize_cache/iblock/ Allow: /upload/resize_cache/medialibrary/ Allow: /*?question=* Allow: /*?review_id=* Allow: /*.css Allow: /*.js #Bitrix end
Joomla
User-agent: * Allow: / #Robots Joomla Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ #Robots Joomla end
Drupal
User-agent: * Allow: / #Robots Drupal Disallow: /includes/ Disallow: /misc/ Disallow: /modules/ Disallow: /profiles/ Disallow: /scripts/ Disallow: /themes/ Disallow: /CHANGELOG.txt Disallow: /cron.php Disallow: /INSTALL.mysql.txt Disallow: /INSTALL.pgsql.txt Disallow: /install.php Disallow: /INSTALL.txt Disallow: /LICENSE.txt Disallow: /MAINTAINERS.txt Disallow: /update.php Disallow: /UPGRADE.txt Disallow: /xmlrpc.php Disallow: /admin/ Disallow: /comment/ Disallow: /filter/tips/ Disallow: /node/add/ Disallow: /search/ Disallow: /user/register/ Disallow: /user/password/ Disallow: /user/login/ Disallow: /user/logout/ Disallow: /?q=admin/ Disallow: /?q=comment/ Disallow: /?q=filter/tips/ Disallow: /?q=node/add/ Disallow: /?q=search/ Disallow: /?q=user/password/ Disallow: /?q=user/register/ Disallow: /?q=user/login/ Disallow: /?q=user/logout/ #Robots Drupal end
MODX Evo
User-agent: * Allow: / #Robots MODx Evo Disallow: /assets/cache/ Disallow: /assets/docs/ Disallow: /assets/export/ Disallow: /assets/import/ Disallow: /assets/modules/ Disallow: /assets/plugins/ Disallow: /assets/snippets/ Disallow: /install/ Disallow: /manager/ Disallow: /? Disallow: /*? Disallow: /index.php #MODx Evo end
MODX Revo
User-agent: * Allow: / #Robots MODx Revo Disallow: /manager/ Disallow: /assets/components/ Disallow: /core/ Disallow: /connectors/ Disallow: /index.php Disallow: *? #MODx Revo end
В шаблонах для удобства добавлены комментарии, которые позволят отделить правила для CMS от правил, созданных вебмастером. Не забывайте использовать символ #, чтобы создать понятную структуру и через время вспомнить, зачем написали ту или иную строку.
Как проверить файл robots.txt
Итак, вы прислушались к нашим рекомендациям, использовали один из шаблонов, дописали свои правила и теперь хотите убедиться, что у роботов поисковых систем не будет проблем со сканированием содержимого.
Есть несколько инструментов, которые покажут наличие ошибок в синтаксисе robots.txt и помогут защититься от негативных последствий. Используйте их в комплексе, чтобы получить 100% гарантию результата.
Мы создаём robots для поисковиков, поэтому в первую очередь необходимо использовать инструменты для вебмастеров, которые доступны в консолях Яндекса и Гугла.
Пошаговая инструкция:
- Откройте инструмент анализа robots.txt в Яндекс.Вебмастере.
- Введите домен сайта и нажмите кнопку загрузки содержимого.
- Нажмите кнопку «Проверить».
- Ознакомьтесь с результатами. Обратите внимание на предупреждения и уведомления о найденных ошибках.
- Откройте инструмент проверки файла robots.txt в старой версии Google Search Console.
- Выберите нужный сайт из списка.
- Убедитесь, что в редакторе отображается актуальное содержимое.
- Нажмите кнопку «Отправить», чтобы Google обновил файл.
- При необходимости укажите URL страницы, чтобы проверить открыта ли она для сканирования.
Проверка файла robots.txt через Яндекс.Вебмастер
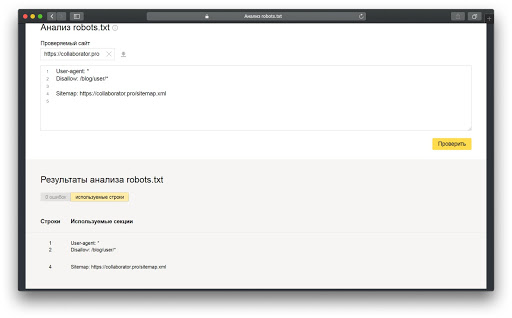
На скрине ниже показано также, как выглядит инструмент проверки файла robots.txt в Google Search Console
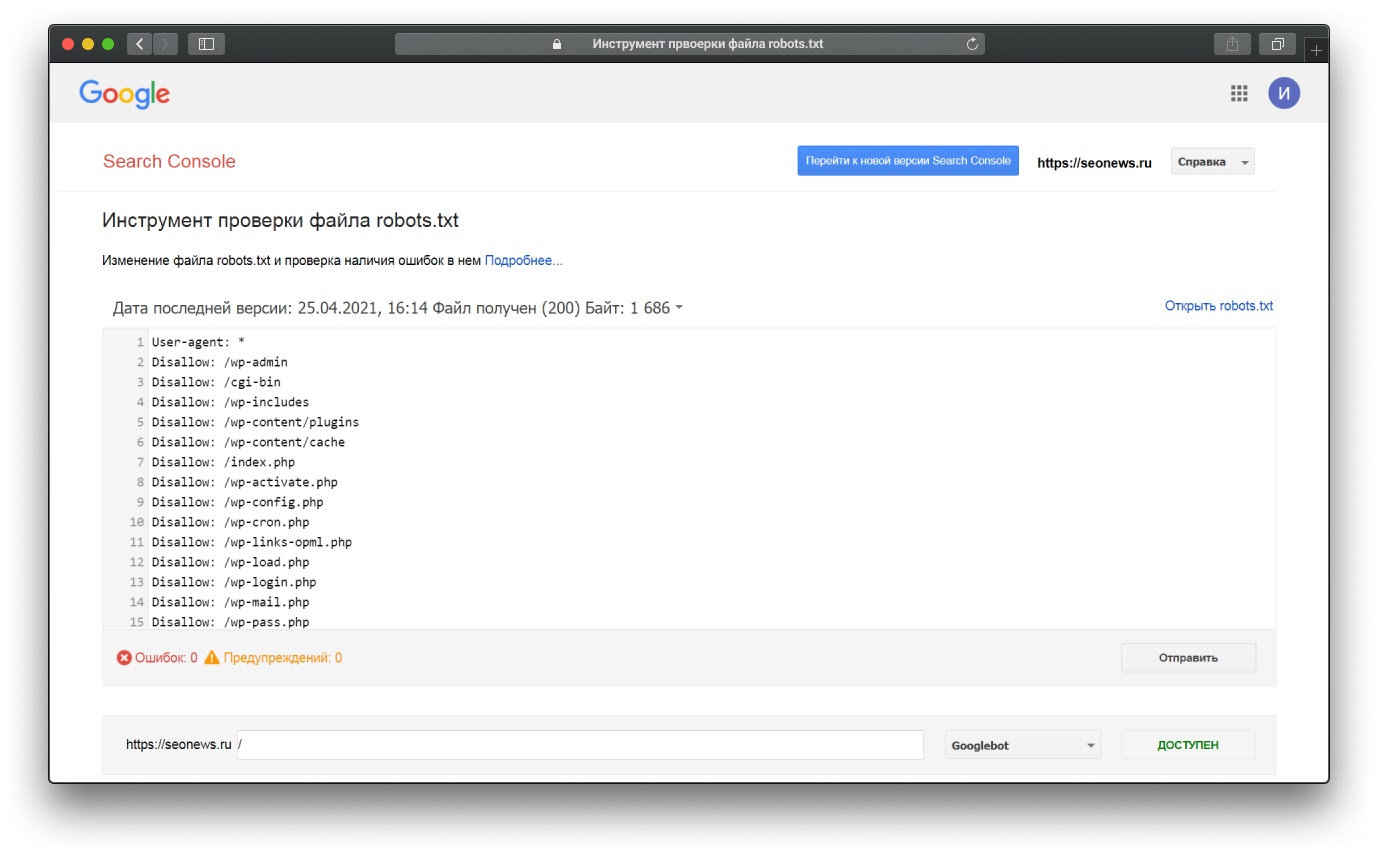
При желании можно использовать сторонние сервисы и десктопные программы для проверки доступности страниц или каталогов для роботов поисковых систем. Соответствующие возможности есть в Sitechecker, Tools.discript.ru, Netpeak Spider и других инструментах.
Можно ли не создавать robots.txt
Есть миф, что если файла не будет в корне сайта, то рассчитывать на высокие позиции не стоит. На самом деле, многие оптимизаторы сильно преувеличивают значимость robots.txt.
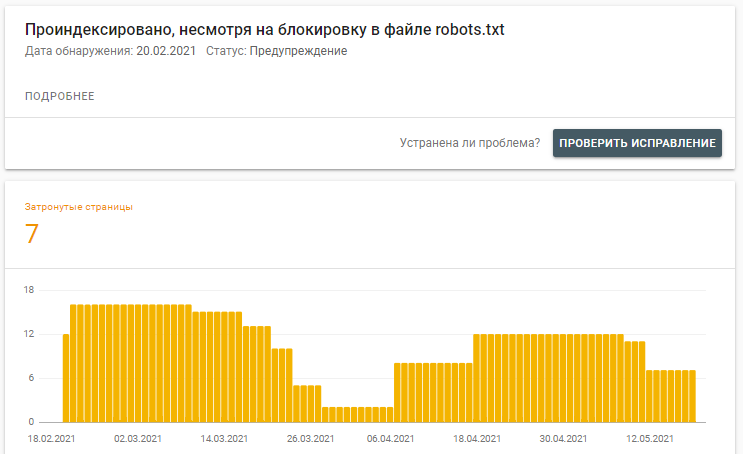
Мы уже говорили, что это не более чем рекомендации для поисковых систем. Если Яндекс ещё хоть немного следует указанным правилам, то Google может их откровенно игнорировать и добавлять страницы в индекс на своё усмотрение. Как доказательство, скрин из Google Search Console, где явно видно, что Гугл может индексировать сайт, несмотря на запрет в robots.txt.
Но всё же лучше создать файл, чтобы в консолях для вебмастеров не было ошибок. Если уверены, что весь мусор закрыли через серверные инструменты или тег <meta name="robots" content="noindex" />, то создайте вот такой файл:
User-agent: *
Allow: /
Это универсальный вариант для сайтов на любой CMS. Он подходит и для фреймворков и для статичных проектов без админки. Хотя используется крайне редко, потому что вебмастера по-прежнему создают кучу правил в robots.
Примеры стандартных правил для robots.txt
Чтобы новичкам было легче получить важный для технической оптимизации навык, собрали примеры стандартных правил, которые постоянно используются на сайтах. Проанализируйте шаблоны и постарайтесь разобраться, почему в одном случае закрывается весь каталог, а в другом только посадочная страница.
Исключение каталога
User-Agent: * Disallow: /catalog/
Исключение страницы
User-Agent: * Disallow: /page
Исключение файла
User-Agent: * Disallow: /catalog/file.php
Исключение URL с динамическими параметрами
User-Agent: * Disallow: /*?
Открытие доступа к папке
User-agent: * Allow: /dir/
Открытие доступа к файлу
User-Agent: * Allow: /catalog/file-2.php
Открытие доступа к CSS, JS
User-Agent: * Allow: /*.js$ Allow: /*.css$
Открытие доступа к медиаконтенту
User-Agent: * Allow: /*.jpg$ Allow: /*.png$ Allow: /*.gif$ Allow: /*.pdf$
Указание нескольких карт сайта
User-Agent: * Allow: / Sitemap: domain.ru/sitemap-1.xml Sitemap: domain.ru/sitemap-2.xml Sitemap: domain.ru/sitemap-3.xml
Самые частые вопросы о файле robots.txt
Дополнительно подготовили ответы на распространённые вопросы о robots.txt. Можете сохранить их у себя, чтобы в любой момент освежить знания. Или просто добавьте статью в закладки браузера и периодически просматривайте, когда будете работать с файлом.
Для чего нужен файл robots.txt?
Файл используется, чтобы ограничить и разрешить сканирование страниц, директорий или файлов на сайте. Также с его помощью можно указать путь к Sitemap.
Как правильно настроить robots.txt?
Соблюдайте правила и рекомендации поисковых систем, не используйте устаревшие директивы и своевременно обновляйте файл.
Как найти на сайте robots.txt?
Прописать в строке браузера путь domain.ru/robots.txt.
Как работать с robots.txt?
Для работы можно использовать любой текстовый редактор, файловый менеджер, FTP-клиент или редактор кода.
Как защитить содержимое файла от перезаписи?
Выставить для файла права 555 на хостинге или через FTP-клиент.
Как уменьшить скорость сканирования моего сайта поисковыми роботами?
Задать настройки в специальных инструментах Яндекс.Вебмастере и Google Search Console.
Можно ли использовать один файл для нескольких сайтов?
Нет, для каждого сайта должен быть свой robots.txt.
Можно ли использовать абсолютные пути в правилах?
Для правил необходимо использовать относительные адреса, для Sitemap указывается полный путь.
Надо ли мне прописывать Allow для всех страниц сайта?
Нет, если страницы не закрыты от сканирования, поисковые роботы будут обходить их и добавлять в индекс.
Что произойдёт, если в файле будет ошибка?
Опечатка или мелкая ошибка не влияет на работу поисковых роботов.
Disallow гарантирует 100% исключение из индекса?
Нет, не гарантирует. Для краулеров это всего лишь рекомендация.
Как часто поисковики обновляют содержимое robots.txt?
Если нет проблем с индексацией, то в среднем раз в несколько дней.
Учитывают ли поисковые работы регистр URL?
Да, регистр учитывается.
В чём разница между robots.txt и метатегом robots?
Файл robots.txt используется для ограничения сканирования, а метатег robots — для управления индексацией.
Правильный файл robots.txt — важный компонент технической оптимизации, который помогает управлять сканированием страниц. Создание оптимальных правил поможет эффективно управлять краулинговым бюджетом и снизить нагрузку на сервер.
Напишите в комментариях, как часто обновляете robots.txt? Или только знаете где он находится, для чего нужен и как запретить индексацию всех страниц 😂?
Бонус! Несколько полезных ссылок для тех, кто изучает SEO:
- получите доступ к бесплатному курсу SEO для новичков от Сергея Кокшарова, лучшего seo-эксперта в СНГ;
- читайте полезную seo-литературу: мы собрали топ лучших SEO книг;
- узнайте, как проверить обратные ссылки на сайт, какие есть бесплатные и платные инструменты для анализа бэклинков;
- изучите лучшие инструменты для анализа траста сайта;
- ознакомьтесь с простыми и действительно популярными сервисами для проверки позиций сайта в поисковых системах;
- научитесь анализировать все аспекты сайтов-конкурентов, начните с простого: как узнать CMS сайта, есть много простых способов.
