SEO-статистика и анализ seo продвижения сайта

Попробуйте Collaborator.pro
Выберите из 36209 высококачественных веб-сайтов и 3433 Telegram каналов
Вперёд
ОглавлениеSEO-статистика и анализ SEO-продвижения сайта — обязательное направление в работе оптимизатора. Многие делают его поверхностно, оперируя лишь основными популярными статистическими данными. Другие — наоборот: погружаются seo анализ очень глубоко, и за отдельными деталями не видят целостную картину.
Артем Пилипец, руководитель отдела продвижения SEO7 и основатель проекта Школа SEO на Первой SEO-конференции Коллаборатора рассказал, как с помощью доступных инструментов, не обладая сверхъестественными знаниями в математике или статистическом анализе, можно разобраться в seo данных сайта, которые мы получаем при продвижении. И как на основании этих данных статистики выдвигать гипотезы и делать выводы для дальнейшего развития ресурса.
Зачем нужен статистический SEO-анализ сайта
Зачем углубляться в SEO-статистику?
Рано или поздно любой опытный сеошник сталкивается с единой проблемой: проекты не растут достаточно хорошо после базовой оптимизации.
Есть огромное количество чек-листов, видеоуроков по базовой внутренней оптимизации сайтов. Есть отличный SEO чек-лист Коллаборатора. Есть автоматизация отслеживания разнообразных ошибок, начиная с Netpeak заканчивая Seranking.
Сейчас в 2021 году нет проблемы в том, чтобы найти базовые ошибки сайта и исправить их (битые ссылки, дубли и прочее). Но после исправления этих ошибок у нас все равно могут оставаться страницы, которые не получают показы и клики или получают аномальные позиции, которые могли бы быть и лучше. И вот здесь нам как раз приходиться анализировать данные.
Согласно исследованию Google, основной проблемой в техническом SEO по-прежнему остается имплементация правок. Статистический анализ, о котором говорил Артем, — это следующий шаг. Всегда нужно начинать с с исправления базовых ошибок, и только потом переходить к более сложным вещам. При этом внедрение базовых правок при оптимизации по-прежнему остается одной из самых серьезных проблем не только на рынке кириллического поиска, но и на рынке SEO по всему миру.
Проблемы внутренней оптимизации
Предположим, что нам удалось убедить наших программистов в том, что наши SEO-правки это не ерунда и их нужно внедрять. Мы хотим улучшить страницы, которые не получают клики, показы и позиции.
Основной принцип в SEO — это построение гипотез и их тестирование.
То есть мы находим страницы, которые хотели бы улучшить. Затем строим гипотезу, внедряем ее и тестируем. Этот подход достаточно простой, но у него есть несколько проблем:
- Новые гипотезы тестировать долго и дорого. На тестирование каждой гипотезы уходит время. И хорошо, если у нашего сайта высокая посещаемость, т.е. мы можем на нужные страницы получить тысячи переходов за несколько дней или недель. Но что если сайт маленький и на тестирование гипотез нужны месяцы? Это очень долго, поэтому хочется как-то улучшить эффект.
- Тестирование новых гипотез тяжело согласовать. Если вы работаете в клиентском SEO либо ваш проект не принадлежит вам, то гипотезы тяжело согласовывать. Например, оптимизатор выдвигает предложение для сайта, которое, по его мнению, может сработать. Но человек, принимающий решения, не соглашается или хочет видеть точно спрогнозированный результат от этой гипотезы. Проблема в том, что гипотеза как раз не предполагает четко обозначенного результата, ее надо тестировать.
- Для формирования гипотез с нуля нужны специалисты, способные это сделать. Причем опыт желательно не на одном проекте, а на нескольких. Если человек сам ведет свой сайт (интернет-магазин) или в работе 2-3 небольших сайта, то глубокие знания тяжело получить. Отсутствие опыта затрудняет построение эффективных гипотез.
Все это приводит к тому, что оптимизация через гипотезы не так хорошо работает, как нам бы хотелось. И вот здесь нам помогает анализ данных.
В ходе доклада Артем дал ссылку на 20 уроков по анализу данных. Уроки по анализу данных на Python, но 70% информации, которой там дается, не требует знания Python. Это больше информация о том, как анализировать данные, что такое статистика и как с ней работать.
Посмотрим, как анализировать данные не зная программирования. Потому что ни каждый SEO-оптимизатор знает языки программирования.
Задачи SEO-анализа
Сначала нужно собрать статистические данные. Собирать их просто и удобно через Screaming Frog и API сервисы, которые в него встроены. Это не требует никаких дополнительных знаний.
Как работать со Screaming Frog, мы подробно описывали в гайде.
Сам анализ данных спикер рекомендует проводить в бесплатном софте – Orange Data Mining, который можно установить на Windows и работать с ним, сколько угодно. В качестве дополнительных источников данных используются Google Search Console и Ahrefs. Последний сервис платный, но он позволяет получить информацию об обратных ссылках. О всех его возможностях читайте в материале.
Сопоставив все эти данные в одном большом файле, мы можем получить большее количество информации для анализа.
Стандартные задачи для анализа SEO-данных:
- поиск причин не индексации страницы. Очень распространенная ситуация, когда сайт, имеющий больше сотни страниц, не индексируется до конца. Часть страниц попадает в разнообразные интересные статусы, типа «просканировано, но не проиндексировано» в Google Search Console. Нам бы очень хотелось добавлять эти страницы в индекс быстрее. С помощью анализа данных можно осуществить поиск причин, почему какие-то страницы индексируются, а другие нет.
- сравнение успешных и неуспешных страниц по видимости. Это один из самых примитивных подходов, т.е. мы можем посмотреть на страницы, которые показывают хорошие позиции, и страницы, которые имеют плохие. Затем сравнить их между собой, попытаться найти какие-то закономерности, статистически значимые различия, и на основе этого сделать какие-то выводы и построить уже более надежную гипотезу;
- анализ закономерностей при попадании страниц в рекомендательные ленты Google Discover и Google News. Если у вас информационный сайт, то попадание туда, особенно в Google Discover, очень ценная штука. Если хотя бы одна ваша статья залетает в Google Discover, то вы получаете кучу трафика.Если вы наладите производство контента, который заходит в информационные ленты на постоянной основе, то за короткий промежуток времени можете очень сильно увеличить свой трафик. Поэтому необходимо понимать, почему одни статьи и новости на одном и том же сайте залетают в Google Discover и Google News, а другие нет.
Как собрать данные для статистического анализа в SEO
Устанавливаем Screaming Frog, подключаем API. Заходим в онлайн сервисы.
Не забудьте:
- проверить подписки Ahrefs и Screaming Frog. Google Search Console — бесплатный сервис, Ahrefs и Screaming Frog — платные, но зато они позволяют собирать данные буквально за пару минут и быстро связать все между собой.
- настроить проверку дубликатов (об этом часто забывают начинающие сеошники) и запустить Crawl анализ после того, как вы отсканировали сайт с помощью Screaming Frog. Постанализ отсканированных данных позволит вам получить дополнительные показатели по перелинковке по весу страниц внутри сайта, а также информацию о частичных дубликатах, что может быть очень полезной метрикой для дальнейшего анализа.
Подготовка данных для анализа статистики SEO
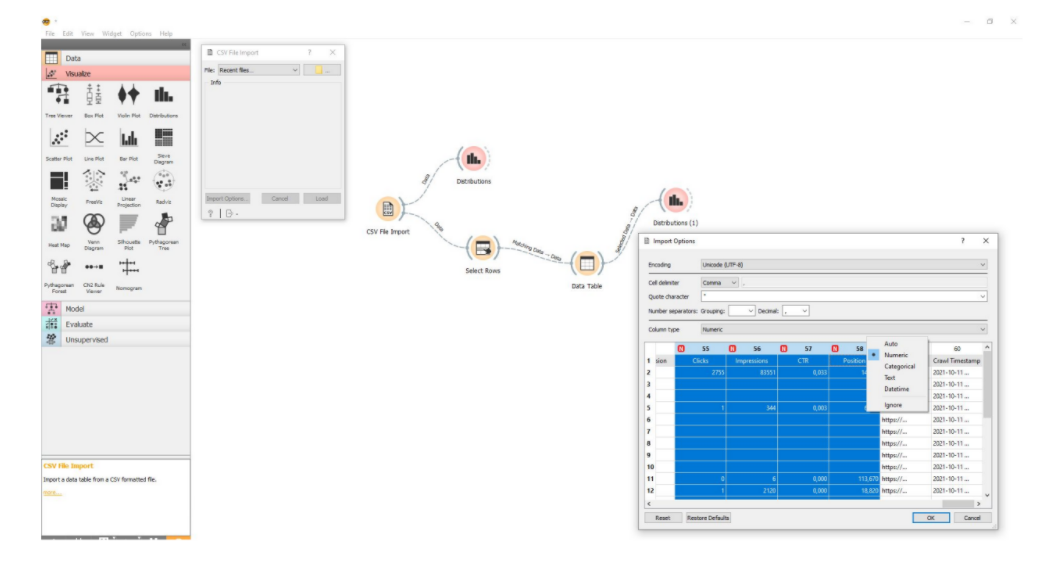
Собранные данные нужно выгрузить в CSV. Выгружаем стандартным экспортом. Это скриншот заготовки в Orange Data Mining.
По сути это визуальный редактор, который из готовых блоков позволяет собирать какие-то последовательности для анализа данных. Первый блок – это импорт CSV файла. Тут Удостоверьтесь, что:
- данные импортируются правильно. Например, цифровые значения при импорте воспринимаются как цифровые. Если некоторые данные не воспринимаются как цифровые значения, то выберете, что это именно число и у него есть разделитель в виде точки или запятой. Тогда эти данные будут правильно обрабатываться всеми дальнейшими блоками и элементами.
- заранее удалены или отсеяны не полностью заполненные строки данных. Если по какой-то странице у вас ней нет всех данных в CSV файле, то лучше от таких строк избавиться. Иначе это будет вызывать большое количество погрешностей. В Orange Data Mining это делается автоматически: нужно только убедиться, что включена галочка, которая передает полностью заполненные данные.
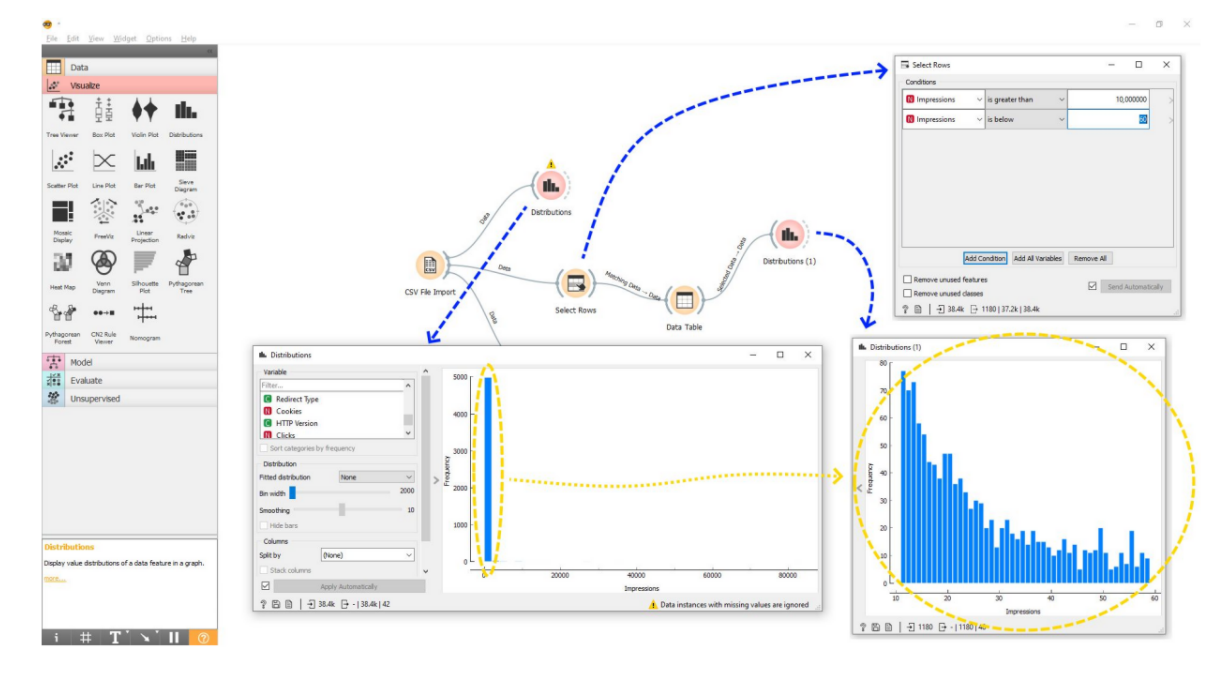
Начинать анализ выгруженных данных стоит с построения гистограммы — столбчатого графика.
Первая гистограмма, которую построим по нашему CSV файлу, будет по показам. Есть сайт, мы его выгрузили и смотрим на все страницы, какую долю показов они получают. Мы здесь видим один высокий столбец и длиннющую нижнюю ось. Естественно, ничего не можем проанализировать. Как это интерпретировать? Нужно перейти к следующему этапу – отсечение выбросов и разбивки данных на диапазоны.
Здесь нужно отбросить самые большие и самые малые значения. Например, хотим проанализировать, какие страницы получают больше показов, а какие меньше. И найти какие-то закономерности в том, почему одни страницы лучше отображаются в поиске, а другие – хуже.
Всегда есть очень популярная страница. Главная страница сайта тоже всегда будет иметь большое количество показа, особенно, если у нас популярное название бренда. Например, мы большой узнаваемый интернет-магазин, и главная страница получает миллионы показов в результатах поиска, просто потому, что ее ищут по названию сайта. Это выброс, т.е. атипичная ситуация для нашего сайта. Это страница, которая получает показы ни потому что она хорошая, а потому что у нас узнаваемый бренд. Получается, что это не совсем SEO заслуга. Такие страницы нужно выбросить из анализа.
И, напротив, у нас есть такие страницы как «Контакты», «О нас», «Доставка и оплата», которые не получают показы и не должны их получать. Эти страницы не оптимизированы под какие-то ключевые слова, поэтому чаще всего у них и не должно быть поисковой видимости. Если брать их в нашу статистику, то получим результат в искаженном виде.
При подготовке данных для SEO-анализа выбирается диапазон, с которым будем работать, обрезаются выбросы (слишком высокие и низкие значения).
Если страниц много, их лучше нарезать на диапазоны: от 10 до 60 показов, от 60 до 100 показов, от 100 до 1 000, от 1 000 до 10 000 и т.д. Нарезав контент на определенные диапазоны, вы внутри этих диапазонов сможете изучать разнообразные факторы и искать между ними закономерности, анализировать данные. Если анализировать все данные в одной куче, никаких нормальных выводов не получится сделать.
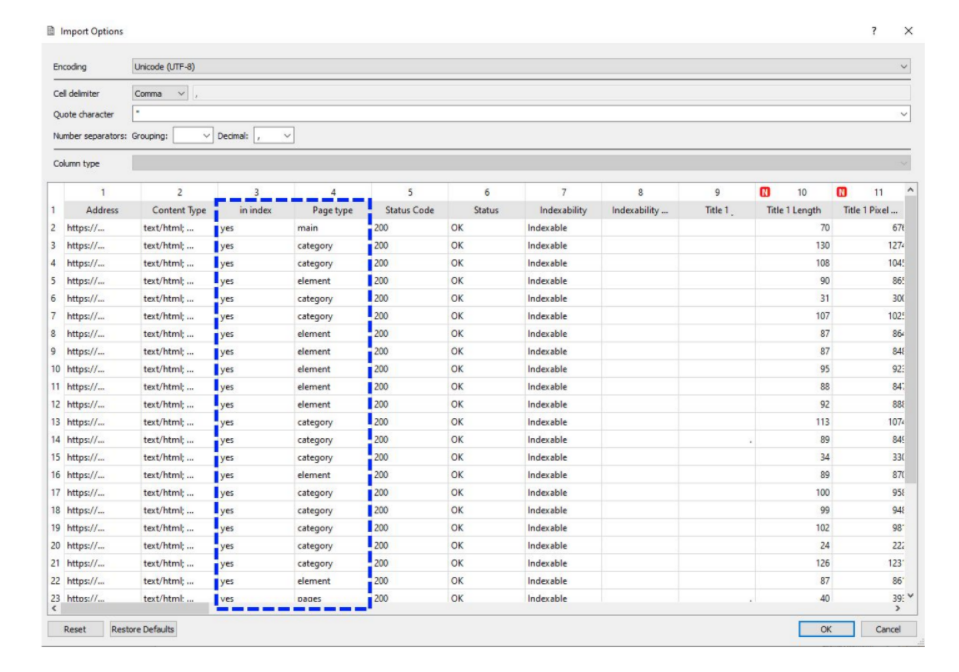
Совет от Артема Пилипца: разметить тип страницы и индексацию.
ПРоверить индексацию можно разными способами. Если ваш сайт небольшой, один из самых простых – выгрузить статистику из Google Search Console и посмотреть, какая страница в индексе, а какая нет, и в каком статусе она находится. Если страница есть в индексе – ok. Если нет, тоже ставим отметку. Если просканирована, но не проиндексирована, ставим ей статус «Просканирована, но пока не проиндексирована». Это нужно для того, чтобы сравнивать разные группы страниц и искать причины того, почему одна страница попадает в индекс, а другая нет.
Разместить страницы по типам тоже просто. Например, в случае интернет-магазина можно отдельно разметить страницы «Категории» и «Товары».Зачем? Потому что показы, клики, семантика, по которой оптимизируются разделы и товары каталога — это чаще всего абсолютно разные ключевые слова по объему поиска, конкуренции, сложности продвижения. Допустим, для товара получать 100-150 показов по результатам поиска это нормально, а вот для категории, которая должна получать тысячи показов, это очень плохой результат. Для того чтобы делать правильные выводы, мы должны сравнивать страницы одного типа: товары с товарами, категории с категориями. То есть искать закономерности внутри групп страниц одного типа.
Поиск признаков для гипотез при SEO-аналитике
Есть несколько стандартных приемов для получения интересной информации о сайте за пару минут.
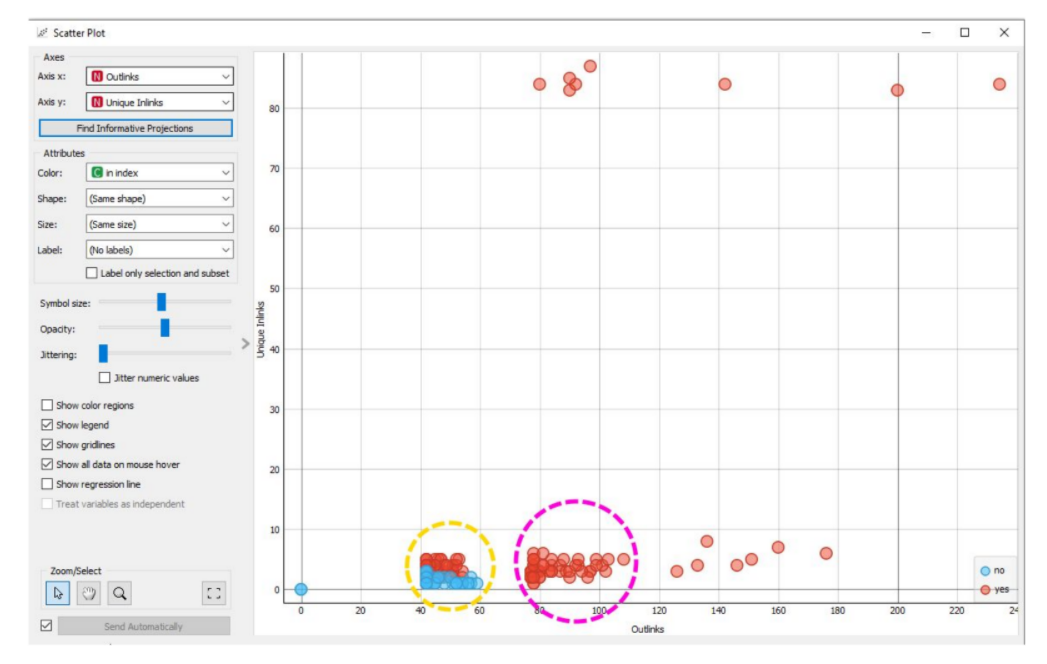
Первый и самый простой подход для формирования гипотезы — построить диаграмму рассеивания.
Ниже пример, какие узлы нужно выстроить в Orange Data Mining для того, чтобы сделать диаграмму рассеивания.
Что делать:
- нажать кнопку «Найти информативные наборы данных»
- в качестве цвета точек выбрать проиндексированные и не проиндексированные страницы
- посмотреть, формируются ли у вас на графике кластеры страниц, окрашенных в тот или иной цвет
Например, на скрине выше проиндексированные страницы отмечены красным цветом, не проиндексированные – синим. Видно, что проиндексированные и не проиндексированные страницы группируются в кластеры по двум параметрам – количество исходящих внутренних ссылок и количество уникальных входящих ссылок. Есть набор выбросов, которые разлетаются на графике, и 2 довольно интересных группы.
Внимательно изучив показатели этих групп по объему контента, количеству внутренних, внешних, исходящих и входящих ссылок, можно сделать определенные выводы.
Например, в группе, которая обведена желтым кружочком, часть страниц, которая находится снизу, полностью не индексируется, а часть страниц, расположенных сверху, индексируется. Эти страницы очень похожи между собой, но изменение одного значения, а именно количество уникальных ссылающихся внутренних ссылок, делает эту страницу либо индексируемой, либо не индексируемой. Это очень интересная закономерность.
В то же время мы видим вторую группу, которая обведена фиолетовым кружком, в которой некоторые страницы, даже имея небольшое количество уникальных внутренних ссылок, все равно индексируются на этом сайте при условии, что у них много исходящих внутренних ссылок. Причем не уникальных, а просто исходящих внутренних ссылок.
На основании этого уже можно строить какие-то гипотезы, которые могут улучшить индексацию этих страниц, например:
- первая гипотеза – если мы возьмем не проиндексированные страницы и поставим на них больше уникальных внутренних ссылок, то они должны подняться по вертикальной оси и проиндексироваться.
- вторая гипотеза — если мы создадим на этих страницах больше исходящих внутренних ссылок, то они тоже должны попасть в группу, которая обведена фиолетовым кружком, т.е. у них должны повыситься шансы на индексацию.
Второй элементарный подход в построении гипотез — это построение графика, который называется «ящик с усами».
Здесь мы можем взять 2 группы страниц и по разным показателям посмотреть, насколько их фактические и типичные средние значения различаются между собой.
Например,
- проиндексированные и не проиндексированные страницы
- страницы, которые попадают / не попадают в Google News или в Google Discover,
В этом случае мы смотрим, насколько велика разница по каким-то показателям между двумя типами этих страниц.
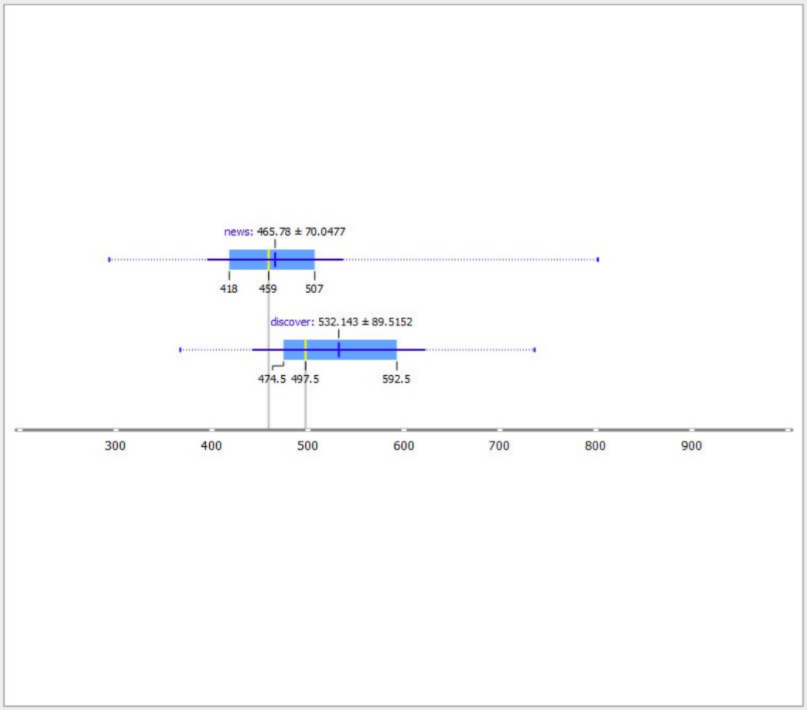
В примере ниже видно, что просто страницы новостей на сайте имеют в среднем 465 слов, а страницы, которые попадают в Google Discover, имеют в среднем 532 слова.
Разница невелика, но если мы сравним с другими показателями, то поймем, что это единственный значимый признак, по которому эти страницы различаются. Гипотеза может быть такой: увеличение объема страницы на 80 слов увеличит шансы на ее попадание в Google Discover.
Что еще можно использовать в Orange Data Mining для поиска признаков для гипотез? Там можно строить корреляцию, кластеризацию, а также целые модели с какими-то сложными последовательностями, и анализировать разные аспекты данных SEO-статистики. Но даже построение таких примитивных вещей, как гистограмма, график с ящиками, график рассеивания, позволяет за 10-15 минут посмотреть на сайт по-другому. Не просто короткие Title, длинные Title, дубликаты и битые ссылки, а конкретно идеи, которые индивидуальны для конкретного ресурса. При условии, что у него есть показы и клики, которые можно собрать.
Использование полученных данных статистического SEO-анализа
Главная опасность при анализе SEO-продвижения сайта — в неправильной интерпретации полученных данных.
Кейс 1. Увеличить количество слов
Например, мы получили данные о разнице в количестве слов между страницами, которые попадают в Google Discover, и страницами, которые туда не попадают. Первое, что приходит в голову – увеличить объем слов на этих страницах. Это можно сделать по-разному:
- увеличить количество блоков,
- добавить дополнительные слова в боковую колонку,
- увеличить футер.
Логично предположить, что различие между обычной новостной страницей и страницей, которая попадает в Google Discover, именно в разнице количества слов в контентной области. Поэтому нужно посчитать, какую часть этих страниц занимает дополнительный контент (всевозможная навигация, боковые колонки, футеры) и какую — основной. На основании этого мы можем рассчитать, что обычная новость в среднем содержит 300 слов. И увеличение объема до 370-400 слов может увеличить эффективность этих новостей. Элемент такой оптимизации в данном случае — чтобы копирайтеры писали новости не по 300 слов, а по 400, а мы посмотрим на результат.
Читайте, как делать текстовую оптимизации под YATI, с помощью каких сервисов можно проверить орфографию и пунктуацию, а также где заказать хороший текст.
На первый взгляд совет совсем простой. Ведь каждый SEOшник знает, что чем больше контента, чем лучше. Но здесь суть в том, что мы сделали предположение не просто по опыту или на основе общих рекомендаций, а на основе статистики.
Когда выводы делаются на основе статистических данных, лучше отсеиваются неэффективные гипотезы.
Совет в данном случае мог касаться изображений. Но из графиков выше видно, что изображение не коррелирует с попаданием в Google Discover.
Кейс 2. Добавить отзывы
Работа со страницами, которые были в статусе «Просканировано, но не проиндексировано».
Яркий пример — это каталоги организации. Проблема ихв том, что карточки компании — это практически неуникальный контент, т.е. телефоны, адреса, логотипы. Они плохо индексируется, а это еще хуже, чем неуникальный интернет-магазин. По сути, каждая страница карточки компании — это низкокачественная страница, которую плохо индексируют поисковики. Возникает желание побольше таких карточек загнать в индекс.
На графике выше представлена статистика страниц, которые находятся в статусе «Просканировано, но не проиндексировано». Мы сравниваем их со страницами такого же типа, которые попадают в индекс. И делаем три вывода:
- Количество исходящих ссылок повышает вероятность индексации страницы
- Количество уникальных входящих ссылок тоже повышает индексацию страницы.
- есть слабая корреляция между объемом слов на странице и попаданием в индекс.
Какие правки можно предложить:
- увеличить количество отображаемых элементов на странице пагинации. Если в листинге отображается условно 15 карточек, то начинаем отображать 20. Таким образом, поднимается больше глубоких карточек выше, и они получают чуть больше ссылочного веса;
- сделать перелинковку между карточками компании по похожим позициям. Таким образом, мы создали дополнительные уникальные ссылки внутри сайта на эти карточки;
Еще один интересный момент: из анализа видно, что на индексацию влияет количество внутренних исходящих ссылок на странице. Не уникальных, а обычных. Когда мы говорим о перелинковке, традиционно делается акцент на количестве уникальных ссылок, как входящих, так и исходящих. А здесь идет интересная корреляция между исходящими внутренними ссылками и индексацией. При исследовании посмотрели на саму страницу, откуда берется такое большое количество исходящих ссылок. Это были отзывы.
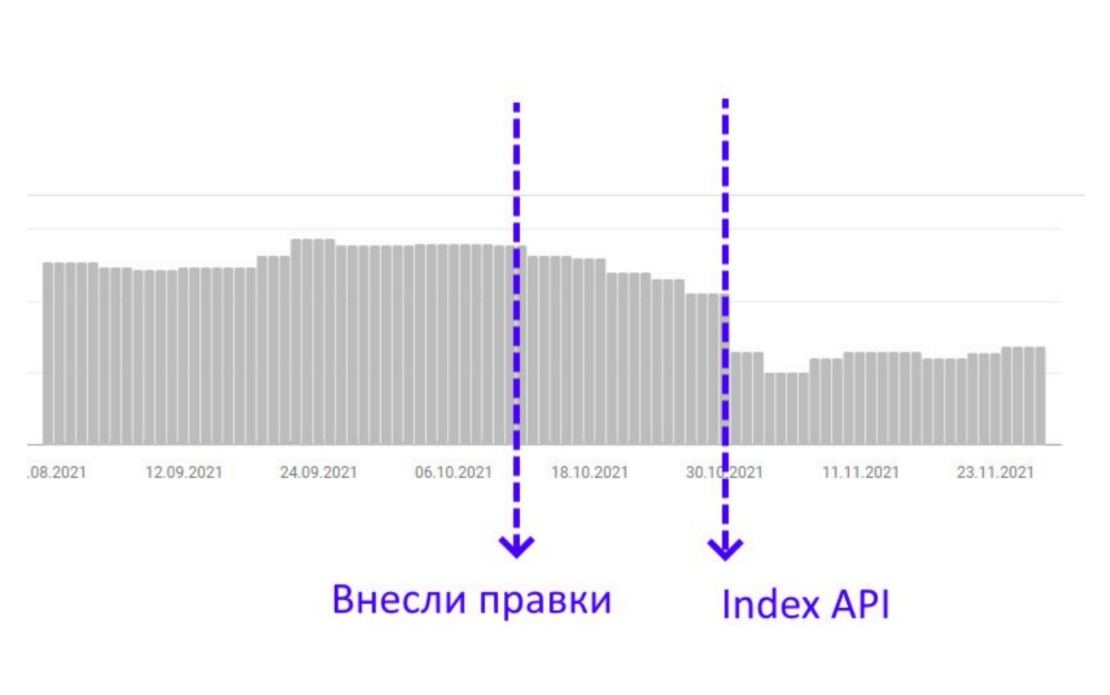
Когда человек оставляет отзыв, идет ссылка на его профиль, ссылка на подписку и еще несколько дополнительных внутренних ссылок. В итоге получается, что один отзыв, который оставляется на карточке, создает порядка 4-ех внутренних ссылок. Не уникальных, но внутренних. Если на карточке есть 3-4 отзыва, то резко возрастает количество исходящих внутренних ссылок. Вывод: нужно увеличить количество отзывов на карточках.
Опыт Артема: «Мы постарались, сделали несколько отзывов на каждую карточку и увидели, как страницы, на которые были внесены правки, плавно начали заходить в индекс. Это было не очень быстро, поэтому мы взяли эти страницы и пару раз отправили в Google Indexing API на переиндексацию. В даты, когда мы начали отправлять автоматические массовые запросы на переиндексацию, эти страницы массово зашли в индекс и потом уже не выходили оттуда».
Таким образов анализ данных позволет построить гипотезу, которая повышает эффективность. Ее тестирование и результаты видны сразу же после переиндексации. Не нужно ждать несколько недель или месяцев, чтобы увидеть, что сработало, а что нет. Потому на основе анализа данных выделяются показатели, которые являются определенной закономерностью.
Вопрос-ответ
Вы говорите, что нужно отрезать слишком высокие и слишком низкие значения, но как узнать, что слишком низкие — это всякие «О нас» и т.д.? Может в низких значениях есть страницы, которые нам очень нужны, но по ним просто низкие показатели?— Обычно отрезается какой-то процент, например, по 20% сверху и снизу, либо откровенные выбросы, когда есть буквально несколько аномальных значений. Допустим, у нас есть 10 тысяч страниц, из них: 10 страниц, у которых меньше 10 показов, и 10 страниц, у которых больше 10 тысяч показов. То есть это точно выбросы. Они имеют небольшую статистическую часть от общей выборки, но при этом у них супераномальное значение, которое искажает среднее.
Если вы отрезали какой-то выброс, то это не значит, что вы отказываетесь от его анализа. Наоборот, вы потом можете взять этот выброс и проанализировать его дополнительно. Просто если это 1-2 страницы, то никакого толкового анализа вы не сделаете. Если у вас все страницы крутые, а только 2 плохие, то анализировать здесь сложно, нужно смотреть на ситуацию. А если в выбросе 50 страниц, то вы можете взять этот диапазон и начать рассматривать, что с ними не так. При этом необязательно отрезать выбросы по видимости. Допустим, вы можете взять категорийные страницы, посмотреть их объем в HTML-коде и сравнить по этому показателю. Тогда это не будет вашим выбросом, а попадает в выборку и будет дальше анализироваться. Видимость – это один из примеров.
Показывает ли Screaming Frog, что страница проиндексирована?— Точно не помню. Я не специалист по Screaming Frog, но, по-моему, там такой функции нет. Я просто выгружаю Google Search Console. Плюс для проверки индексации можно использовать облачные сервисы, где можно делать это более массово.
Многие закрывают такие страница, как «Карты», «Политика конфиденциальности» и т.д. в noindex и nofollow, но разве эти страницы не относятся к важным коммерческим сигналам для поиска? Стоит ли их закрывать?— На мой взгляд, в этом нет никакого смысла, особенно в nofollow. Это делают, потому что эти страницы часто не уникальны, дублированы. Но ваш сайт состоит не из трех страниц. Если у вас есть один дубликат, то это не катастрофа. Из-за одного дубликата вы не просядете. Допустим, у вас каталог на 200 товаров и страница «Политика конфиденциальности» частично не уникальна, то закроете ли вы ее в noindex или нет, ничего не изменит.
Есть такой старый миф, что если в футере указаны эти сквозные страницы, которые важны как коммерческие факторы, то на них утекает вес со всего сайта. Поэтому чтобы не отдавать на них вес, их просто консервируют noindex и nofollow.— Я понимаю, зачем это делают, но это же не соответствует тому, что говорит Google. Суть в том, что гугловцы говорили, что если страница закрыта в noindex, она участвует в расчете ссылочного веса. А nofollow meta это не nofollow rel. Он не перекрывает ссылочного веса. Nofollow означает, что ссылки с этой страницы будут участвовать в построении очереди сканирования. Получается, что если мы ставим meta nofollow, то это не работает так, как рассказывается в этом мифе. Если верить тому, что говорят гугловцы, то и meta noindex не работает так, как придумано. В итоге — зачем закрывать. Я лично не закрываю, потому что не вижу в этом смысла.
Есть ли какая-то хорошая инструкция по тому, как адаптировать Google Discover? Может та знаешь какой-то гайд или планируешь у себя выпустить такое видео?— Я планирую. Если у нас будет 60-70% попадания в Google Discover, то обязательно выпущу, чтобы похвастаться. Есть стандартная инструкция Google, она весьма неплохая. Они там рассказывают и про разметки, и про размеры изображения, которые стоит использовать, и многое другое. Есть неплохие исследования на основе данных. Есть замечательное исследование по статистике от одного специалиста под именем «Просто блогер». Это бывший модератор Google форума. Он проводил исследование на основе анализа данных по попаданию в Google Discover. Выводы его — объем контента, объем ссылочного и объем трафика.
На сегодняшний день есть много инструкций и инструментов, которые помогают сделать базовое SEO. Но продвинутые SEO-специалисты должны выходить за рамки традиционных подходов. Уже недостаточно оптимизировать сайт по чек-листу, чтобы делать SEO. Эта опция доступна каждому вебмастеру даже на бесплатной платформе.
Нужно искать точки роста и приемы, которые будут эффективны индивидуально для вашего проекта. Лучший способ найти их — анализировать данные. Тем более что сейчас это доступно абсолютно всем и не обязательно знать Python. Современные инструменты позволяют разобраться и сделать интересные классные выводы буквально в течение 15 минут после начала работы.
А как вы анализируете данные SEO-статистики? Делитесь в комментариях кейсами👇