ЗмістSEO-статистика та аналіз SEO-просування сайту — обов'язковий напрямок у роботі оптимізатора. Багато хто робить його поверхнево, оперуючи лише основними популярними статистичними даними. Інші навпаки: занурюються в seo аналіз дуже глибоко, і за окремими деталями не бачать цілісну картину.
Артем Пилипец, керівник відділу просування SEO7 та засновник проекту Школа SEO на Першій SEO-конференції Collaborator розповів, як за допомогою доступних інструментів, не володіючи надприродними знаннями в математиці або статистичному аналізі, можна розібратися в SEO даних сайту, які ми отримуємо при просуванні. І як на підставі цих даних статистики висувати гіпотези та робити висновки для подальшого розвитку ресурсу.
Навіщо потрібний статистичний SEO-аналіз сайту
Навіщо заглиблюватися у SEO-статистику?
Рано чи пізно будь-який досвідчений SEO-вець зустрічається з єдиною проблемою: проекти не зростають досить добре після базової оптимізації.
Є безліч чек-листів, відеоуроків з базової внутрішньої оптимізації сайтів. Є SEO чек-лист Collaborator. Є автоматизація відстеження різноманітних помилок, починаючи з Netpeak закінчуючи Seranking.
Сьогодні немає проблеми в тому, щоб знайти базові помилки сайту та виправити їх (биті посилання, дублі та інше). Але після виправлення цих помилок у нас все одно можуть залишатися сторінки, які не отримують покази та кліки або отримують аномальні позиції, які могли б бути кращими. І ось тут нам якраз доводиться аналізувати дані.
Згідно дослідження Google, основною проблемою в технічному SEO, як і раніше, залишається імплементація правок. Статистичний аналіз, про який говорив Артем, це наступний крок. Завжди потрібно починати з виправлення базових помилок, і лише потім переходити до складніших речей. При цьому впровадження базових правок при оптимізації, як і раніше, залишається однією з найсерйозніших проблем не тільки на ринку кириличного пошуку, а й на ринку SEO по всьому світу.
Проблеми внутрішньої оптимізації
Припустимо, що нам вдалося переконати наших програмістів у тому, що наші SEO-правки це не нісенітниця і їх потрібно впроваджувати. Ми хочемо покращити сторінки, які не отримують кліки, покази та позиції.
Основний принцип в SEO — це побудова гіпотез та їх тестування.
Ми знаходимо сторінки, які хотіли б покращити. Потім будуємо гіпотезу, запроваджуємо її і тестуємо. Цей підхід досить простий, але у нього є кілька проблем:
- Нові гіпотези тестувати довго і дорого. На тестування кожної гіпотези потрібен час. І добре, якщо у нашого сайту висока відвідуваність, тобто ми можемо на потрібні сторінки отримати тисячі переходів за кілька днів або тижнів. Але що якщо сайт маленький і на тестування гіпотез потрібні місяці? Це дуже довго, тому хочеться пришвидшити процес.
- Тестування нових гіпотез важко узгоджувати. Якщо ви працюєте в клієнтському SEO або ваш проект не належить вам. Наприклад, оптимізатор дає пропозицію для сайту, яка, на його думку, може спрацювати. Але людина, яка приймає рішення, не погоджується або хоче бачити точно спрогнозований результат цієї гіпотези. Проблема в тому, що гіпотеза як раз не передбачає однозначноого результату, її потрібно тестувати.
- Для формування гіпотез із нуля потрібні фахівці, здатні це зробити. Причому досвід бажано не на одному проекті, а на кількох. Якщо людина сама веде свій сайт (інтернет-магазин) або в роботі 2-3 невеликі сайти, то глибокі знання важко отримати. Відсутність досвіду ускладнює побудову ефективних гіпотез.
Все це призводить до того, що оптимізація через гіпотези не так добре працює, як нам хотілося б. І тут допомагає аналіз даних.
В доповіді Артем дав посилання на 20 уроків про аналіз даних на Python, але 70% інформації, яка там дається, не вимагає знання Python. Це більше інформація про те, як аналізувати дані, що таке статистика та як з нею працювати.
Подивимося, як аналізувати дані, не знаючи програмування, тому що не кожен оптимізатор володіє цими навичками.
Задачі SEO-аналізу
Спочатку потрібно зібрати статистичні дані. Збирати їх просто та зручно через Screaming Frog та API сервіси, які у нього вбудовані. Це не потребує додаткових знань.
Як працювати зі Screaming Frog, ми детально описували в гайді.
Сам аналіз даних спікер рекомендує проводити у безкоштовному софті – Orange Data Mining, який можна встановити на Windows і працювати з ним скільки завгодно. Як додаткові джерела даних використовуються Google Search Console та Ahrefs. Останній сервіс платний, але дозволяє отримати інформацію про зворотні посилання. Про всі можливості Ahrefs читайте у матеріалі.
Зібравши усі дані в одному великому файлі, ми можемо отримати значну кількість інформації для аналізу.
Стандартні завдання для аналізу SEO-даних:
- пошук причин не індексації сторінки. Дуже поширена ситуація, коли сайт, що має понад сотню сторінок, не індексується до кінця. Частина сторінок потрапляє у різноманітні цікаві статуси, на кшталт «проскановано, але не проіндексовано» у Google Search Console. Нам дуже хотілося б додавати ці сторінки в індекс швидше. За допомогою аналізу даних можна здійснити пошук причин, чому якісь сторінки індексуються, а інші ні;
- порівняння успішних та неуспішних сторінок за видимістю. Це простий підхід, тобто ми можемо подивитися на сторінки, які показують хороші позиції, та сторінки, які мають погані. Потім порівняти їх між собою, спробувати знайти якісь закономірності, статистично значущі відмінності, і на основі цього зробити якісь висновки та побудувати вже більш надійну гіпотезу;
- аналіз закономірностей потрапляння сторінок у рекомендаційні стрічки Google Discover та Google News. Якщо у вас інформаційний сайт, то потрапити туди, особливо в Google Discover — дуже цінна штука. Якщо хоча б одна ваша стаття залітає в Google Discover, то ви отримуєте купу трафіку. Якщо ви налагодите виробництво контенту, який заходить в інформаційні стрічки на постійній основі, то за короткий проміжок часу ви можете дуже збільшити свій трафік. Необхідно розуміти, чому одні статті та новини на тому самому сайті потрапляють у Google Discover і Google News, а інші ні.
Як зібрати дані для статистичного аналізу у SEO
Встановлюємо Screaming Frog, підключаємо API. Заходимо в онлайн сервіси.
Не забудьте:
- перевірити підписки Ahrefs та Screaming Frog. Google Search Console — безкоштовний сервіс, Ahrefs і Screaming Frog — платні, зате вони дозволяють збирати дані буквально за пару хвилин і швидко зв'язати все між собою;
- налаштувати перевірку дублікатів (про це часто забувають початківці) і запустити Crawl аналіз після того, як ви відсканували сайт за допомогою Screaming Frog. Постаналіз відсканованих даних дозволить отримати додаткові показники перелінковки за вагою сторінок всередині сайту, а також інформацію про часткові дублікати, що може бути дуже корисною метрикою для подальшого аналізу.
Підготовка даних для аналізу статистики SEO
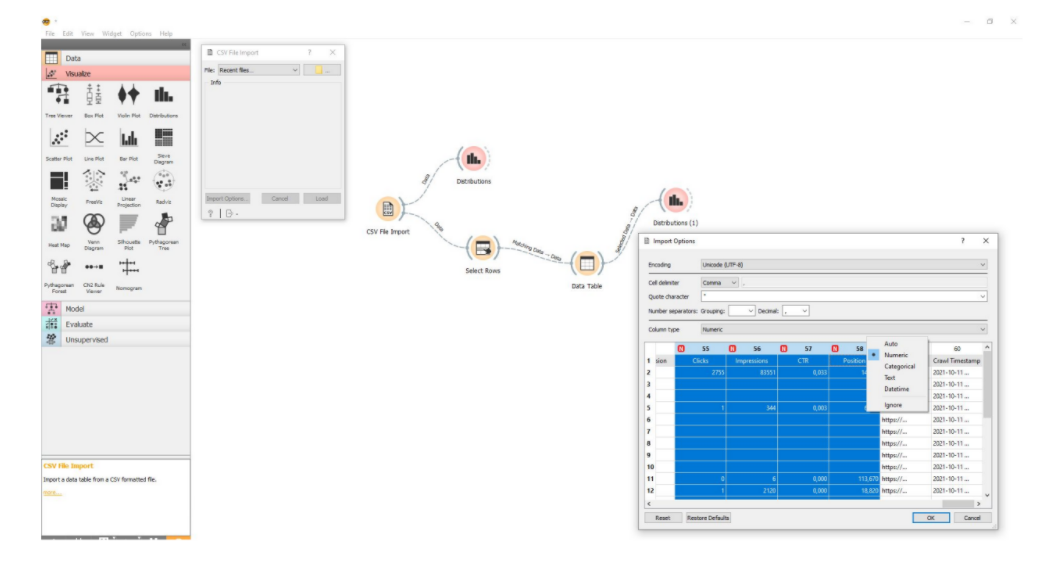
Зібрані дані потрібно вивантажити в CSV стандартним експортом. Це скріншот заготовки в Orange Data Mining.
По суті, це візуальний редактор, який з готових блоків дозволяє збирати певні послідовності для аналізу даних. Перший блок – це імпорт CSV файлу.
Переконайтеся, що:
- дані імпортуються правильно. Наприклад, цифрові значення при імпорті сприймаються як цифрові. Якщо деякі дані не сприймаються як цифрові , то оберіть саме такий формат відображення. Це важливо для подальшої обробки наступними блоками та елементами.
- заздалегідь видалені або відсіяні не повністю заповнені рядки даних. Якщо по якійсь сторінці нмає всіх даних у CSV файлі, то краще таких рядків позбутися. Інакше це викликатиме велику кількість похибок. В Orange Data Mining це робиться автоматично: потрібно лише переконатися, що включено галочку, яка передає повністю заповнені дані.
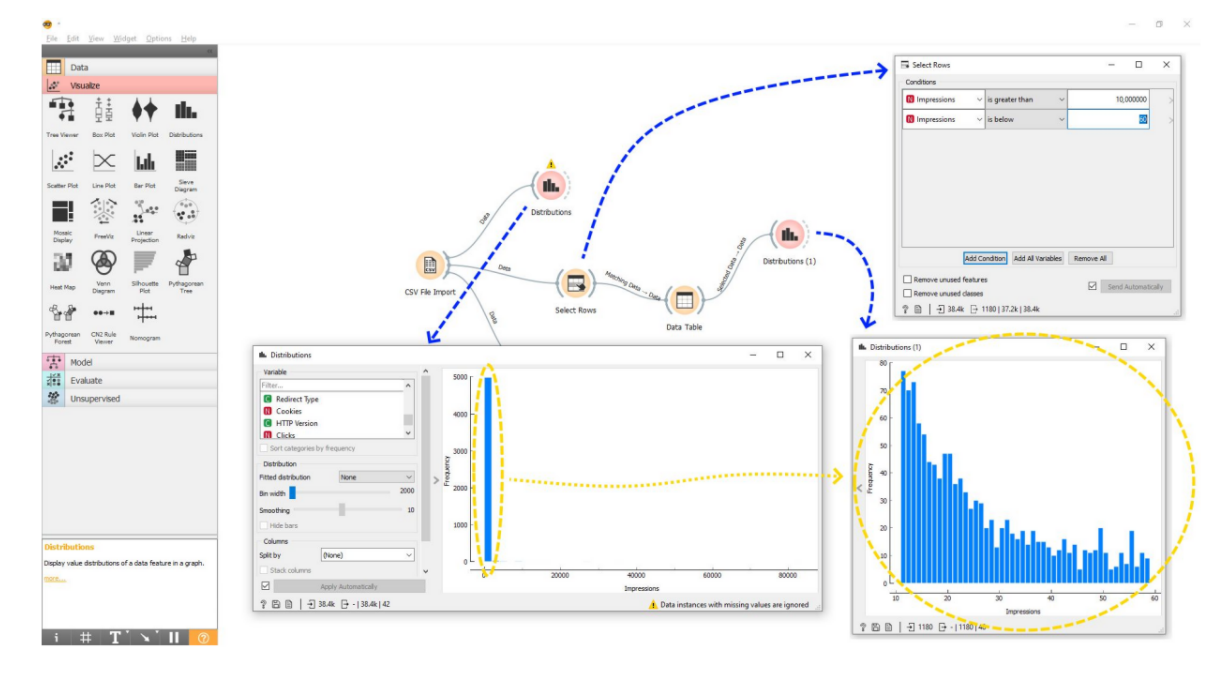
Починати аналіз вивантажених даних варто з побудови гістограми — стовпчастого графіку.
Перша гістограма, яку побудуємо у нашому CSV файлі, буде за показами. Є сайт, ми його вивантажили та дивимося на всі сторінки, яку частку показів вони одержують. Ми тут бачимо один високий стовпець та довгу нижню вісь. Звичайно, нічого не можемо проаналізувати. Як це інтерпретувати? Потрібно перейти до наступного етапу – систематизації.
Тут потрібно відкинути найбільші та найменші значення. Наприклад, хочемо проаналізувати, які сторінки одержують більше показів, а які менше. І знайти якісь закономірності того, чому одні сторінки краще відображаються у пошуку, а інші – гірше.
Завжди є дуже відома сторінка. Головна сторінка сайту теж завжди матиме велику кількість показів, особливо якщо у нас популярна назва бренду. Наприклад, ми великий відомий інтернет-магазин, і головна сторінка отримує мільйони показів у результатах пошуку просто тому, що її шукають за назвою сайту. Це атипова ситуація для нашого сайту. Це сторінка, яка отримує покази не тому, що вона хороша, а тому що у нас відомий бренд. Виходить, що це не зовсім SEO заслуги. Такі сторінки слід викинути з аналізу.
І, навпаки, ми маємо такі сторінки як «Контакти», «Про нас», «Доставка та оплата», які не отримують покази і не повинні їх отримувати. Ці сторінки не оптимізовані під якісь ключові слова, тому найчастіше у них не повинно бути пошукової видимості. Якщо брати їх у нашу статистику, то отримаємо результат у спотвореному вигляді.
Під час підготовки даних для SEO-аналізу обирається діапазон, з яким будемо працювати, вилучаються занадто високі та низькі значення.
Якщо сторінок багато, їх краще нарізати на діапазони: від 10 до 60 показів, від 60 до 100, від 100 до 1 000, від 1 000 до 10 000 і т.д. Нарізавши контент на певні діапазони, ви усередині цих діапазонів зможете вивчати різноманітні фактори та шукати між ними закономірності, аналізувати дані. Якщо аналізувати всі дані в одній купі, жодних нормальних висновків не вдасться зробити.
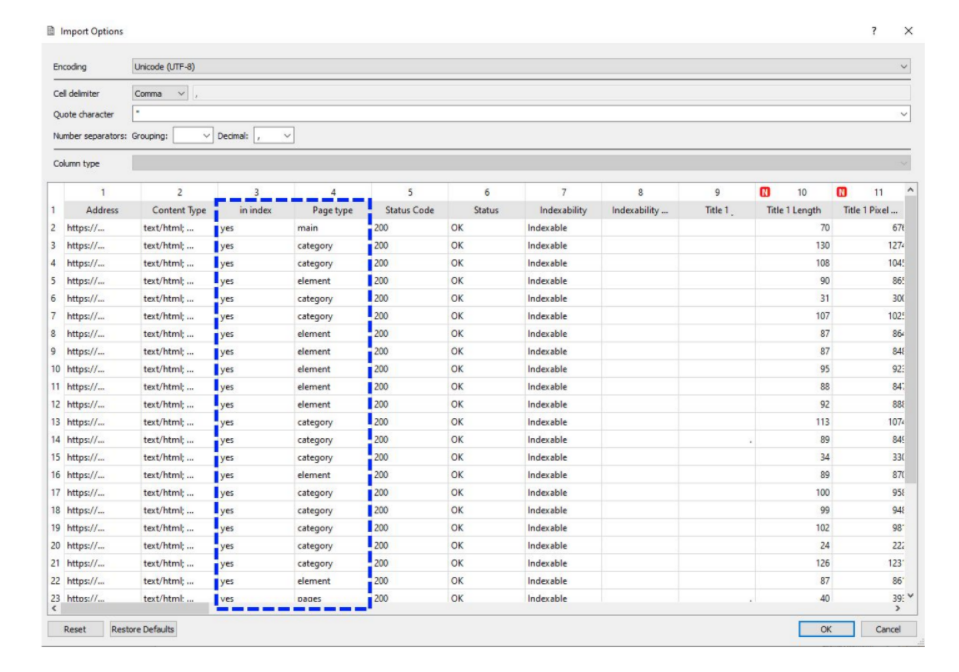
Порада від Артема Пилипця: розмітити тип сторінки та індексацію.
Перевірити індексацію можна у різний спосіб. Якщо ваш сайт невеликий, один із найпростіших – вивантажити статистику з Google Search Console та подивитися, яка сторінка в індексі, а яка ні, та в якому статусі вона знаходиться. Якщо сторінка є у індексі – ok. Якщо ні, також ставимо позначку. Якщо просканована, але не проіндексована, ставимо їй відповідний статус. Це потрібно для того, щоб порівнювати різні групи сторінок та шукати причини того, чому одна сторінка потрапляє до індексу, а інша ні.
Розмітити сторінки за типами також просто. Наприклад, у разі інтернет-магазину можна окремо розмітити сторінки «Категорії» та «Товари». Навіщо? Тому що покази, кліки, семантика, за якою оптимізуються розділи та товари каталогу, — це найчастіше абсолютно різні ключові слова щодо обсягу пошуку, конкуренції, складності просування. Припустимо, для товару отримувати 100-150 показів за результатами пошуку це нормально, а для категорії, яка повинна отримувати тисячі показів, це дуже поганий результат. Щоб робити правильні висновки, ми повинні порівнювати сторінки одного типу: товари з товарами, категорії з категоріями. Тобто шукати закономірності усередині груп сторінок одного типу.
Пошук ознак для гіпотез під час SEO-аналітики
Є кілька стандартних прийомів для отримання цікавої інформації про сайт за кілька хвилин.
Перший і найпростіший підхід для формування гіпотези – побудувати діаграму розсіювання.
Нижче приклад, які вузли потрібно побудувати в Orange Data Mining для того, щоб зробити діаграму розсіювання.
Що робити:
- натиснути кнопку «Знайти інформативні набори даних»;
- як колір точок вибрати проіндексовані та не проіндексовані сторінки;
- подивитися, чи формуються на графіку кластери сторінок, пофарбованих у той чи інший колір.
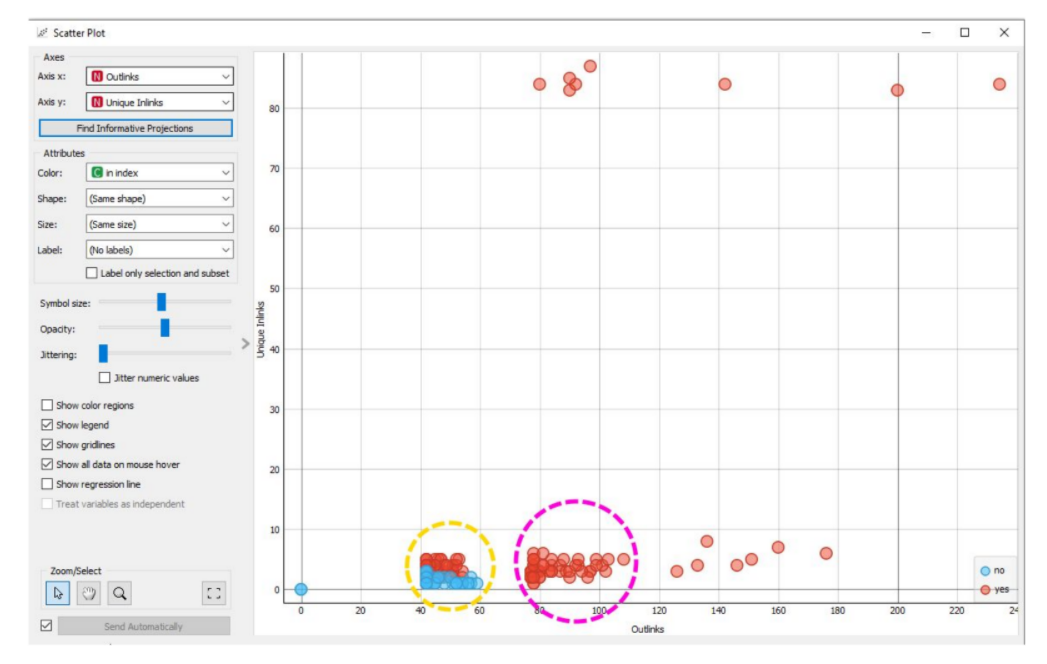
Наприклад, на скріншоті вище проіндексовані сторінки позначені червоним, не проіндексовані – синім. Видно, що проіндексовані та не проіндексовані сторінки групуються у кластери за двома параметрами – кількість вихідних внутрішніх посилань та кількість унікальних вхідних посилань. Є набір виключень, які розлітаються на графіку, і 2 досить цікаві групи.
Уважно вивчивши показники цих груп за обсягом контенту, кількістю внутрішніх, зовнішніх, вихідних та вхідних посилань, можна зробити певні висновки.
Наприклад, у групі, яка обведена жовтим кружечком, частина сторінок, що знаходиться знизу, повністю не індексується, а частина сторінок, розташованих зверху, індексується. Ці сторінки дуже схожі між собою, змінний лиш 1 показник — кількість унікальних внутрішніх посилань. Це дуже цікава закономірність.
У той же час ми бачимо другу групу, яка обведена фіолетовим кругом. Тут деякі сторінки, навіть маючи невелику кількість унікальних внутрішніх посилань, все одно індексуються на цьому сайті за умови, що вони мають багато вихідних внутрішніх посилань. Причому не унікальних, а просто вихідних внутрішніх посилань.
На підставі цього вже можна будувати якісь гіпотези, які можуть покращити індексацію цих сторінок, наприклад:
- перша гіпотеза – якщо ми візьмемо не проіндексовані сторінки та поставимо на них більше унікальних внутрішніх посилань, то вони повинні піднятися вертикальною віссю та проіндексуватися.
- друга гіпотеза — якщо ми створимо на цих сторінках більше вихідних внутрішніх посилань, всі вони теж мають потрапити до групи, яка обведена фіолетовим кругом, тобто, у них мають підвищитися шанси на індексацію.
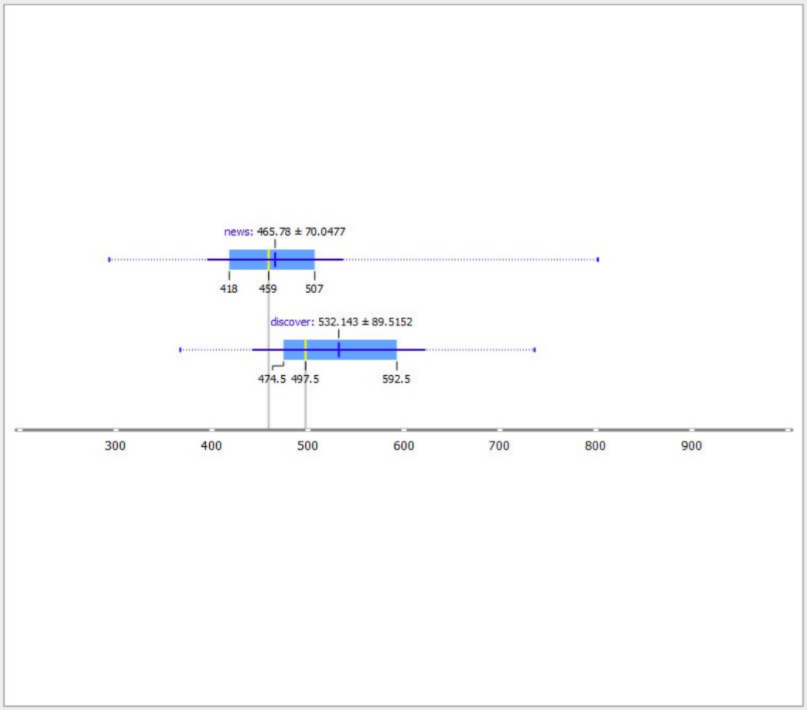
Другий елементарний підхід у побудові гіпотез — це побудова графіку, який називається «ящик з вусами».
Тут ми можемо взяти дві групи сторінок і за різними показниками подивитися, наскільки їх фактичні та типові середні значення різняться між собою.
Наприклад:
- проіндексовані та не проіндексовані сторінки,
- сторінки, які потрапляють / не потрапляють до Google News або Google Discover.
І тут ми дивимося, наскільки велика різниця за якимись показниками між двома типами цих сторінок.
У прикладі нижче видно, що просто сторінки новин на сайті мають у середньому 465 слів, а сторінки, які потрапляють до Google Discover, мають у середньому 532 слова.
Різниця невелика, але якщо ми порівняємо з іншими показниками, то зрозуміємо, що це єдина істотна ознака, за якою ці сторінки різняться. Гіпотеза може бути такою: збільшення обсягу сторінки на 80 слів збільшить шанси потрапити до Google Discover.
Що ще можна використовувати в Orange Data Mining для пошуку ознак гіпотез? Там можна будувати кореляцію, кластеризацію, а також цілі моделі з якимись складними послідовностями та аналізувати різні аспекти даних SEO-статистики. Але навіть побудова таких примітивних речей, як гістограма, графік із ящиками, графік розсіювання дозволяє за 10-15 хвилин подивитися на сайт по-іншому. Не просто короткі Title, довгі Title, дублікати і биті посилання. А саме ідеї, які індивідуальні для конкретного ресурсу. За умови, що він має покази та кліки, які можна зібрати.
Використання отриманих даних статистичного SEO-аналізу
Головна небезпека при аналізі SEO-просування сайту – у неправильній інтерпретації отриманих даних.
Кейс 1. Збільшити кількість слів
Наприклад, ми отримали дані про різницю у кількості слів між сторінками, які потрапляють до Google Discover, та сторінками, які туди не потрапляють. Перше, що спадає на думку – збільшити обсяг слів на цих сторінках. Це можна зробити по-різному:
- збільшити кількість блоків,
- додати додаткові слова в бічну колонку,
- збільшити футер.
Логічно припустити, що різниця між звичайною сторінкою новин і сторінкою, яка потрапляє в Google Discover, саме в кількості слів в контентній області. Тому потрібно порахувати, яку частину цих сторінок займає додатковий контент (різна навігація, бічні колонки, футери) і яку основний. На підставі цього ми можемо розрахувати, що звичайна новина у середньому містить 300 слів. І збільшення обсягу до 370-400 слів може збільшити ефективність цих новин. Елемент такої оптимізації в даному випадку — щоб копірайтери писали новини не за 300 слів, а за 400, а ми подивимося на результат.
На перший погляд порада дуже проста. Адже кожен SEO-вець знає, що чим більше контенту, то краще. Але тут суть у тому, що ми зробили припущення не просто за досвідом чи на основі загальних рекомендацій, а на основі статистики.
Коли висновки робляться з урахуванням статистичних даних, краще відсіваються неефективні гіпотези.
Порада в цьому випадку могла стосуватися зображень. Але з графіків вище видно, що зображення не корелює із влученням в Google Discover.
Кейс 2. Додати відгуки
Робота зі сторінками, які були у статусі «Проскановано, але не проіндексовано».
Яскравий приклад – це каталоги організації. Проблема в тому, що картки компанії — це майже неунікальний контент, тобто, телефони, адреси, логотипи. Вони погано індексуються, а це ще гірше, ніж неунікальний інтернет-магазин. По суті кожна сторінка картки компанії — це низькоякісна сторінка, яку погано індексують пошукові системи. Виникає бажання якомога більше таких карток загнати в індекс.
На графіці вище представлена статистика сторінок, які перебувають у статусі «Проскановано, але не проіндексовано». Ми порівнюємо їх зі сторінками такого ж типу, що потрапляють до індексу. І робимо три висновки:
- Кількість вихідних посилань підвищує можливість індексації сторінки.
- Кількість унікальних вхідних посилань також підвищує індексацію сторінки.
- Є слабка кореляція між обсягом слів на сторінці та потраплянням до індексу.
Які правки можна запропонувати:
- збільшити кількість відображених елементів на сторінці пагінації. Якщо в лістингу відображається умовно 15 карток, то починаємо відображати 20. Таким чином, піднімається більше глибоких карток вище, і вони отримують трохи більше ваги посилань;
- зробити перелінковку між картками компанії за схожими позиціями. Таким чином, ми створили додаткові унікальні посилання всередині сайту на ці картки.
Ще один цікавий момент: з аналізу видно, що на індексацію впливає кількість внутрішніх вихідних посилань на сторінці. Не унікальних, а звичайних. Коли ми говоримо про перелінкування, зазвичай робиться акцент на кількості унікальних посилань, як вхідних, так і вихідних. А тут йде цікава кореляція між вихідними внутрішніми посиланнями та індексацією. Під час дослідження подивилися на саму сторінку, звідки береться така велика кількість вихідних посилань. То були відгуки.
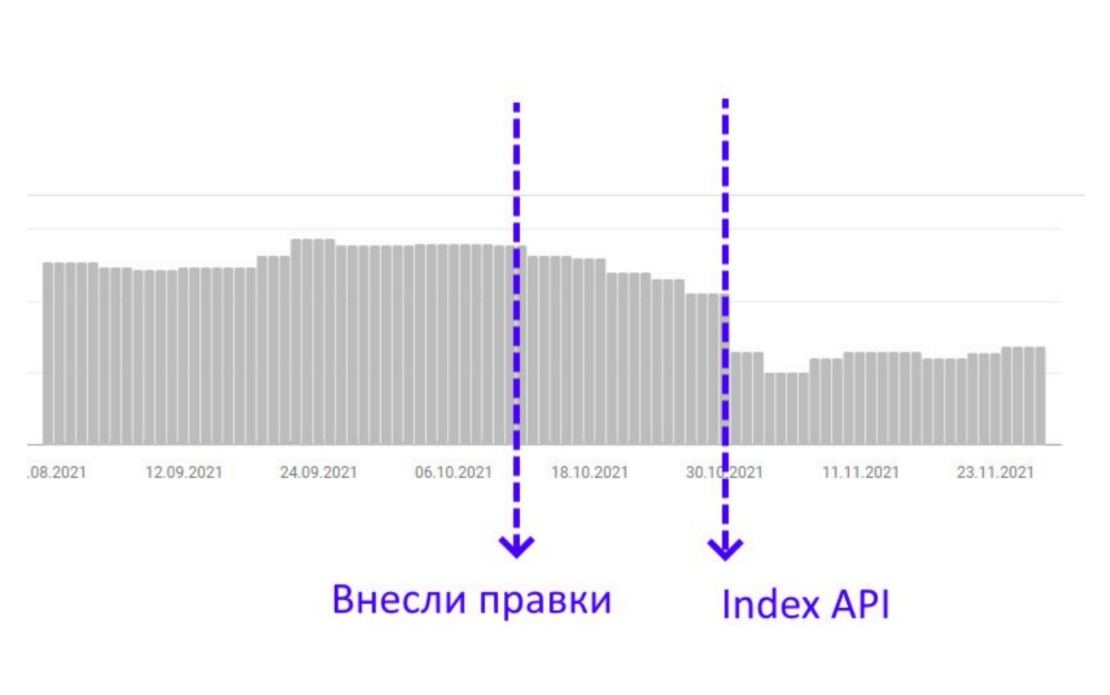
Коли людина залишає відгук, йде посилання на її профіль, посилання на передплату та ще кілька додаткових внутрішніх посилань. У результаті виходить, що один відгук, який залишається на картці, створює близько 4 внутрішніх посилань. Не унікальних, але внутрішніх. Якщо у картці є 3-4 відгуки, то різко зростає кількість вихідних внутрішніх посилань. Висновок: потрібно збільшити кількість відгуків на картках.
Досвід Артема: «Ми постаралися, зробили кілька відгуків на кожну картку та побачили, як сторінки, на які були внесені правки, плавно почали заходити до індексу. Це було не дуже швидко, тому ми взяли ці сторінки і кілька разів відправили в Google Indexing API на переіндексацію. У дати, коли ми почали надсилати автоматичні масові запити на переіндексацію, ці сторінки масово зайшли до індексу і потім уже не виходили звідти».
Таким чином, аналіз даних дозволить побудувати гіпотезу, яка підвищує ефективність. Її тестування та результати видно відразу ж після переіндексації. Не треба чекати кілька тижнів чи місяців, щоб побачити, що спрацювало, а що ні. Тому на основі аналізу даних виділяються показники, які є певною закономірністю.
Питання — Відповідь
Ви кажете, що потрібно відрізати надто високі та надто низькі значення, але як дізнатися, що надто низькі — це сторінки типу «Про нас» тощо? Може, у низьких значеннях є сторінки, які нам дуже потрібні, але мають просто низькі показники?— Зазвичай відрізається якийсь відсоток, наприклад, по 20% зверху та знизу, або відверті викиди, коли є буквально кілька аномальних значень. Припустимо, у нас є 10 тисяч сторінок, з них: 10 сторінок, у яких менше 10 показів, та 10 сторінок, у яких більше 10 тисяч показів. Тобто це точно викиди. Вони мають невелику статистичну частку від загальної вибірки, але при цьому мають супераномальне значення, яке спотворює середнє.
Якщо ви відрізали якийсь викид, це не означає, що ви відмовляєтеся від його аналізу. Навпаки, потім ви можете взяти цей викид і проаналізувати його додатково. Просто якщо це 1-2 сторінки, то жодного аналізу ви не зробите. Якщо у вас усі сторінки круті, а лише 2 погані, то аналізувати тут складно, потрібно дивитися на ситуацію. А якщо у викиді 50 сторінок, ви можете взяти цей діапазон і почати розглядати, що з ними не так. При цьому необов'язково відрізати викиди. Припустимо, ви можете взяти категорійні сторінки, подивитися їх обсяг у HTML-коді та порівняти за цим показником. Тоді це не буде вашим викидом, а потрапляє у вибірку і далі буде аналізуватися. Видимість – це один із прикладів.
Чи показує Screaming Frog, що сторінка проіндексована?— Точно не пам'ятаю. Я не фахівець з Screaming Frog, але, на мою думку, там такої функції немає. Я просто вивантажую Google Search Console. Плюс для перевірки індексації можна використовувати хмарні послуги, де можна робити це більш масово.
Багато хто закриває такі сторінки, як «Карти», «Політика конфіденційності» тощо в noindex і nofollow, але хіба ці сторінки не належать до важливих комерційних сигналів для пошуку? Чи варто їх закривати?— Як на мене, в цьому немає ніякого сенсу, особливо в nofollow. Це роблять, тому що ці сторінки часто не є унікальними, дубльованими. Але ваш сайт складається не із трьох сторінок. Якщо у вас є один дублікат, це не катастрофа. Через один дублікат ви не просядете. Припустимо, у вас каталог на 200 товарів та сторінка «Політика конфіденційності» частково не унікальна, то закриєте ви її в noindex чи ні, нічого не змінить.
Є такий старий міф, що якщо у футері вказані ці наскрізні сторінки, які є важливими як комерційні фактори, то на них витікає вага з усього сайту. Тому, щоб не віддавати на них вагу, їх просто консервують noindex та nofollow.— Я розумію, навіщо це роблять, але це не відповідає тому, що говорить Google. Суть у тому, що гуглівці говорили, що якщо сторінку закрито в noindex, вона бере участь у розрахунку посилальної ваги. А nofollow meta це не nofollow rel. Він не перекриває посилальної ваги. Nofollow означає, що посилання з цієї сторінки братимуть участь у побудові черги сканування. Виходить, якщо ми ставимо meta nofollow, то це не працює так, як розповідається в цьому міфі. Якщо вірити тому, що кажуть гуглівці, то й meta noindex не працює так, як вигадано. Зрештою — навіщо закривати. Я особисто не закриваю, бо не бачу в цьому сенсу.
Чи є якась хороша інструкція щодо адаптації Google Discover? Може ти знаєш якийсь гайд чи плануєш у себе випустити таке відео?— Я планую. Якщо у нас буде 60-70% влучення в Google Discover, то обов'язково випущу, щоб похвалитися. Є стандартна інструкція Google, вона дуже непогана. Вони там розповідають і про розмітки, і про розміри зображення, які варто використати, та багато іншого. Існують непогані дослідження на основі даних. Є чудове дослідження зі статистики від одного фахівця під ім'ям «Просто блогер». Це колишній модератор Google форуму. Він проводив дослідження на основі аналізу даних щодо потрапляння до Google Discover. Його висновки: обсяг контенту, обсяг посилань та обсяг трафіку.
Сьогодні є багато інструкцій та інструментів, які допомагають зробити базове SEO. Але просунуті SEO-фахівці мають виходити за межі традиційних підходів. Вже недостатньо оптимізувати сайт за чек-листом, щоб робити SEO. Ця опція доступна кожному вебмайстру навіть на безкоштовній платформі.
Потрібно шукати точки зростання та прийоми, які будуть ефективні індивідуально для вашого проекту. Найкращий спосіб знайти їх — аналізувати дані. Тим більше, що зараз це доступно абсолютно всім і необов'язково знати Python. Сучасні інструменти дозволяють розібратися та зробити цікаві класні висновки буквально протягом 15 хвилин після початку роботи.
А як ви аналізуєте дані SEO-статистики? Діліться у коментарях кейсами👇
Інші відео доповідей з Першої SEO конференції дивіться в Академії Collaborator.