Олександр Веселов присвятив свою доповідь просуванню новинних сайтів. Звідки приходить трафік на його ресурси та що вони командою роблять, аби максимально скористатися всіма можливостями. Акцент зробив на Discover як непередбачуваному та не до кінця дослідженому інструменті.
На SEO-конференції Коллаборатора Сашко розповів, як оптимізувати контент під органіку та під Discover: чи є різниця та які є нюанси. А ще: виокремив із власного досвіду умови, яким повинен відповідати текст, щоб потрапити в Рекомендовані Google. Тема досить вузька і буде цікава в першу чергу SEO-вцям сайтів медіа, а також редакторам та авторам новинних засобів масової комунікації.
Далі — зі слів Олександра👇
Диференціація трафіку ЗМІ
Саме для сайтів ЗМІ трафік з Google диференційований:
- органіка,
- Google Discover,
- Google News.
В доповіді акцент на органіці, а докладніше — на Discover. Тому що він для новинних сайтів максимально цікавий з точки зору великого трафіку.
Чому так важливо для ЗМІ мати на увазі таку диференціацію трафіку, тобто не орієнтуватися лише на SEO? На графіку нижче представлені дані з Similar Web по топовим ЗМІ. Ми бачимо, яка йде диференціація трафіку у всіх інтернет медіа.
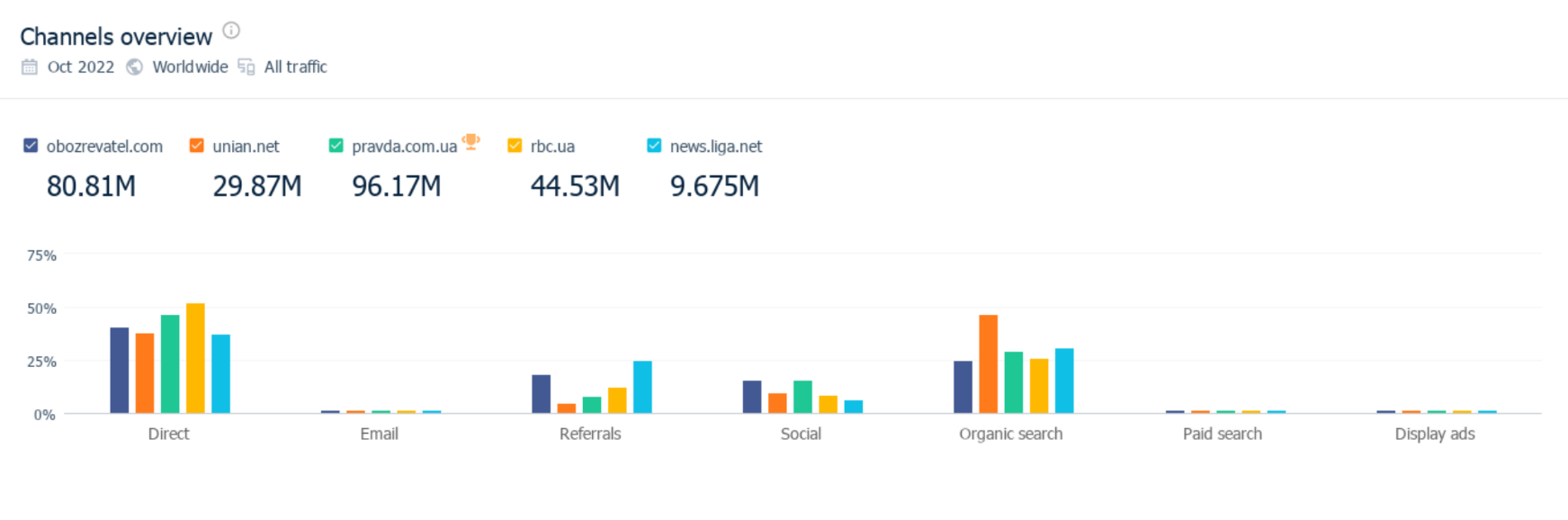
Бачимо, що органічного трафіку близько 25-30%, і це характерно для більшості сайтів ЗМІ. Якщо ви будете працювати тільки над цією часткою, то суттєвих результатів складно досягти.
Також присутній Соціальний трафік, Реферальний трафік, і трафік під назвою Дірект, тобто прямий. Останній — це брендовий трафік, але саме тут в більшій своїй частині знаходиться ще й Google Discover. Окремого розділу з такою назвою в Аналітиці немає. І хоча Google позиціонує так, що Discover — це продовження органіки, але через Аналітику ми бачимо, що такий трафік потрапляє в organic search частково, а більша його частка знаходиться в Direct. Тому дуже важливо працювати не тільки над органікою, але й цю велику частку захоплювати через Google Discover.
Поглянемо на ще один графік.
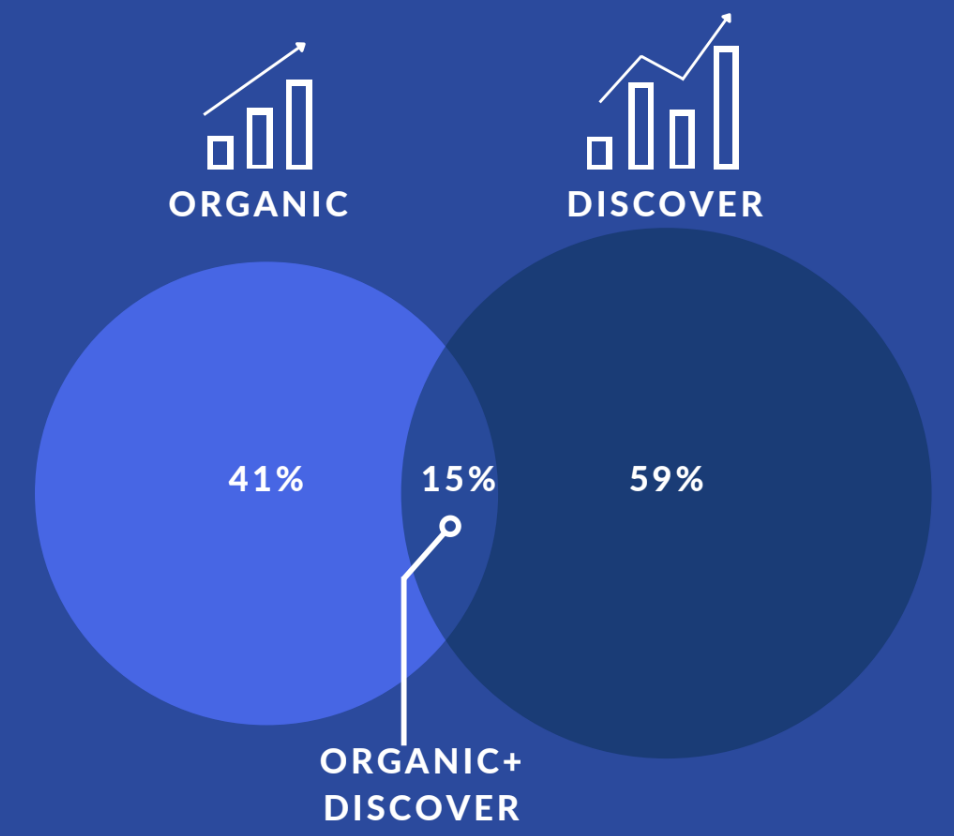
- на даному прикладі 41% трафіку прийшло з органіки на певні сторінки за обмежений період, \
- 59% трафіку отримали на інші сторінки за той самий обраний період,
- лише 15% сторінок мають потенціал і в Google Discover, і в органіці. Ця частка є досить НЕ значною.
Висновок: одночасно орієнтуватись і на Google Discover, і на органіку своїми сторінками ви не взмозі. Це буде неефективно, і вам необхідно публікувати окремий контент під органіку, і окремий контент під Google Discover.
Робота з контентом під органіку: як готувати інформаційні сторінки, щоб вони отримували трафік з органіки
Узагальнено схему роботи з контентом під органіку можна представити так:

Тут важливі 2 моменти:
- Ви можете працювати з новинним контентом: ситуативним, те, що ми ловимо через тренди і т. д. І в органіці ви будете через top stories отримувати суттєвий трафік..
- А можете працювати з інформаційним контентом, і саме з ним здобувати органічний трафік.
В доповіді акцентуємося на 2 варіанті.
Як готувати інформаційні сторінки, щоб вони отримували трафік з органіки?
Аналітика
По-перше, треба грамотна аналітика. Дивимось через search console, через Google Analytics, яка тематика, які розділи в нас присутні в органіці, і на них іде трафік. Чому це важливо? Набагато легше розпочати свою роботу з тим контентом, який вже ранжується по вашому сайту. Адже легше покращити старий контент, ніж писати новий.
Додатково дивимося по консолі, які теми давали гарний трафік з органіки в минулому році. Якщо ці сторінки просіли, можна виправити причини і повернути цей трафік.
І аналізуємо, які теми добре ранжуються у конкурентів.
Семантика
Далі знову збираємо семантику. Тут є два варіанти:
вручну за допомогою сервісів (це звичайна робота SEO-спеціаліста).
напівавтоматично: за допомогою спеціальних сервісів. З ними можуть працювати беспосередньо і самі редактори. Це такі програми, як Surfer SEO або її аналоги. Тут при вводі теми SEO-вець чи редактор можеть одразу побачити ключові слова, метатеги, дескрипшн, структуру, яку треба пропрацювати тощо.
Робота з текстами
Після збору семантики віддамо її редактору, він напише по ній текст, який ми потім перевіряємо: не тільки сам текст, а те, як редактор вміє працювати з ключовими словами. Це важливо, тому що редакторів, як правило, багато, вони інколи змінюються. І ви не будете встигати вичитувати всі тексти. Якщо б це був якийсь звичайний інформаційний сайт, а не ЗМІ, то вам би було досить легко вичитати десяток текстів і зробити по ним висновки.
Тут важливо працювати саме з редакторами. Показати їм, як органічно і ефективно вписувати ключові слова в метатеги і в заголовки. Як ефективно працювати зі структурою та з обсягом тексту. І які ще класні плюшки можна застосувати для того, щоб наша сторінка краще ранжувалась.
Після написання пулу текстів перевіряємо результати по ним: що відпрацювало добре, що ні, і масштабуємо гарні результати.
Таким чином будується робота з контентом саме під органіку: коли ми працюємо з ключовими словами, то надаємо відповідь, намагаючись задовольнити інтент читача.
Кейси
Нижче на скріні дуже добре видно наші результати роботи з органікою (це НЕ OBOZREVATEL).
Тут представлена одна сторінка в двох мовних версіях, для якої вручну зібране семантичне ядро і написаний текст.
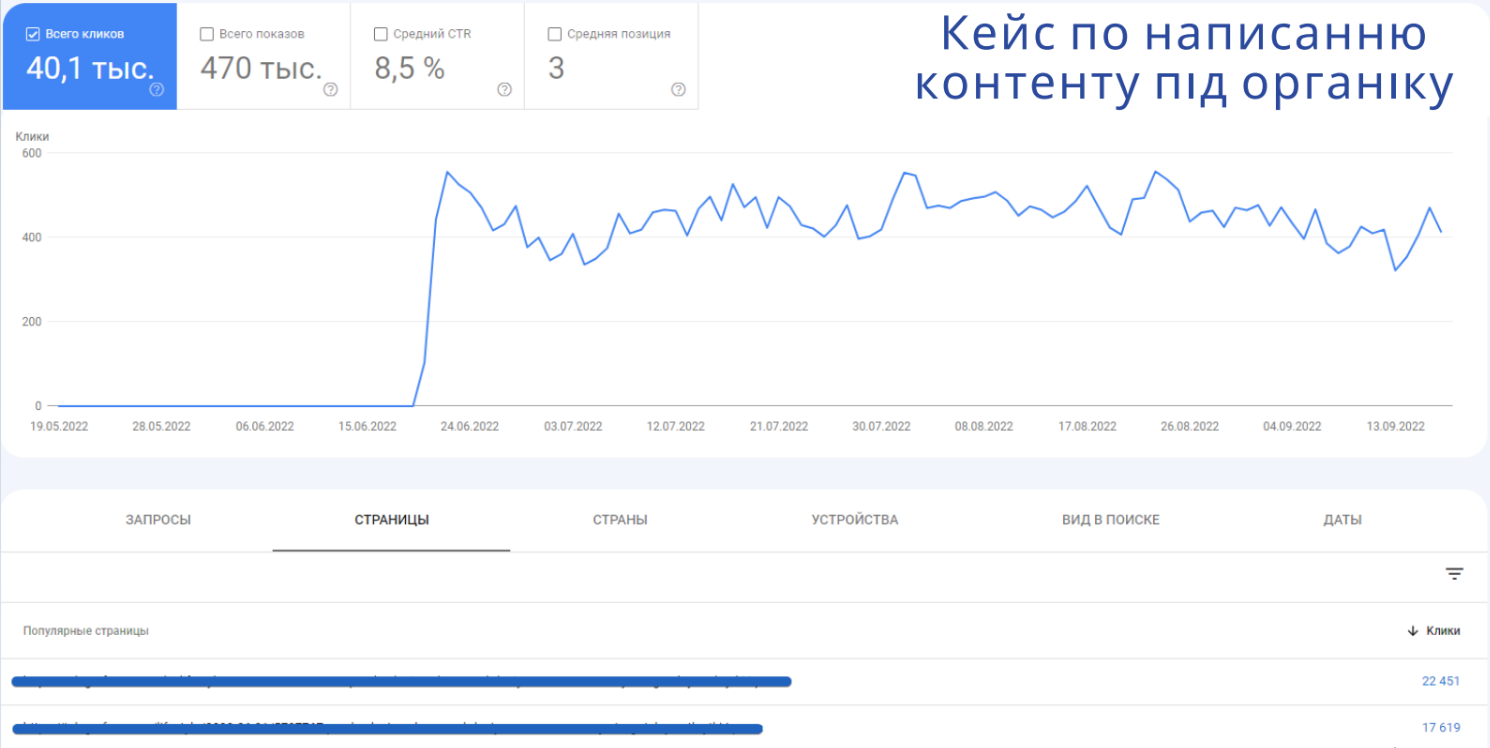
З однієї цієї сторінки, оптимізованої під органічний пошук, ми отримали протягом суттєвого періоду результат. Насправді цей графік ще тут можна продовжити, бо матеріал і досі добре ранжується. Ми однією сторінкою отримуємо в середньому 500 кліків з органіки в день. І вже за весь цей період сторінка набрала 40 тисяч кліків з пошуку.
Інший кейс: коли оптимізували сторінку, яка вже існує.
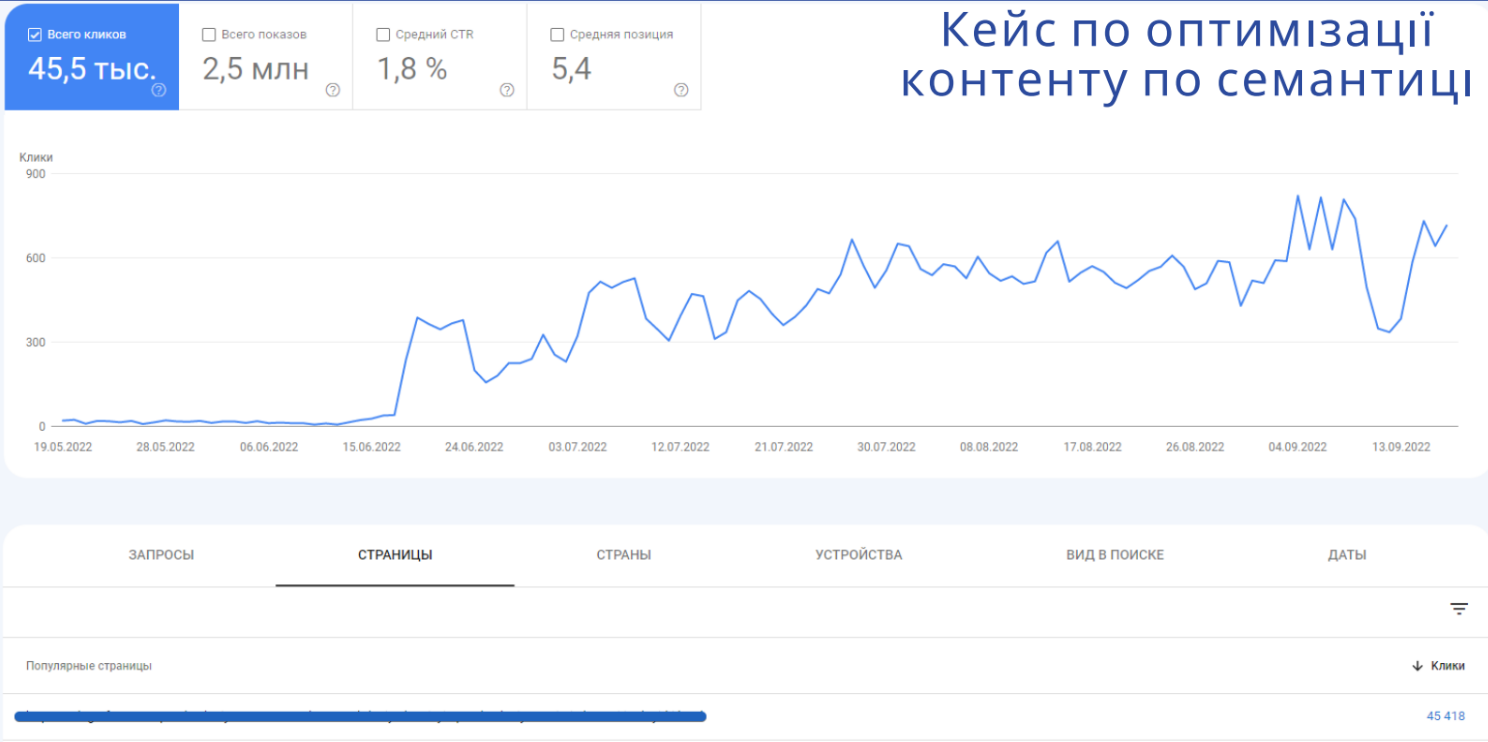
Тут бачимо, що до моменту оптимізації сторінка набирала близько 20-30 кліків на день. Ми зібрали під неї семантику, оптимізували тексти, метатеги, заголовки, альти і так далі. І коли ми викотили оновлення, ця сторінка почала набирати близько 600 кліків на день, і вже за цей час зібрало 45 тисяч кліків. Безумовно, сторінка не ідеальна і ще є над чим працювати. Але треба враховувати рентабельність: що нам буде вигідніше — створити нову сторінку і отримати цей трафік, або доопрацьовувати стару.
Робота з контентом під Discover
Узагальнена схема — на малюнку нижче.

Тут можна розбити на 2 напрямки роботи:
- Варіант А: якщо у вас Google Discover немає.
- Варіант Б: якщо Discover є.
Варіант А: Google Discover = 0
Що ми тоді робимо:
- Відкриваєм стрічку Google Discover. Не в консолі, а просто в себе на телефоні, у застосунку Google чи в Chrome. Дивимось, які теми зараз йдуть в Google Discover. Відмічаємо конкурентів, які там представлені. Нажаль статистики по конкурентам в Google Discover ми не можемо отримати, але проаналізувати стрічку можемо ось таким напівручним методом. Безумовно, Google Discover дуже персоналізований, тому треба подивитись не тільки свою стрічку, а і видачу колеги, і колеги ще одного колеги, для того щоб зробити якусь статистику, і обрати тему, по якій ви будете тестувати написання публікацій.
- Після вибору теми побачили, хто з конкурентів її писав. Ми йдемо до конкурента, бо нам треба зібрати дуже важливий показник — частоту написання публікацій в день, тиждень або місяць. Чому це важливо? Тому що одним з суттєвих факторів попадання в Google Discover буде саме те, скільки і як часто ви відписуєте контента по тематиці, яку обрали. Середній або медіанний показник ми можемо побачити по конкурентам.
- Далі починаємо тестувати. Тестування має відбуватись не менше ніж 1 місяць, а то і більше. Чому? По-перше, вам необхідно доповнити свої публікації, подивитись більш детально конкурентів, не тільки скільки вони публікують, але й яким чином. Які вони використовують заголовки — довгі, короткі, насичені емоційними словами, не клікбейт і так далі. Які вони використовують графічні матеріали, це для Google Discover теж дуже суттєво. Які обсяги публікацій? Тобто якщо ви подивитесь по більшості тем, то в Google Discover теми суттєво будуть відрізнятись від тих, що ми побачимо в органіці. Люди, які пролистують Google Discover, які там клікають, вони не люблять багато читати і, відповідно, шукають більш короткі списки матеріалів.
- Перевіряємо результати. Під час тестів моніторимо показники в Search Console або в Analytics: які теми починають збирати покази або кліки. На них робимо акцент і продовжуємо. Далі переходимо до пункту №1, і знову шукаємо нову тему, яка нам потенційно може дати трафік Google Discover, і повторєм пункти №1, 2, 3, 4.

Варіант Б: Google Discover вже є на сайті
Коли хочеться покращити вже існуючий на сайті Google Discover, краще не починати нових тем, а взяти такі, які вже присутні, та зробити такий самий аналіз. Тобто треба перевірити, чи відповідає кількість опублікованих матеріалів в день або в тиждень медіанному по конкурентах, чи відповідають заголовки, зображення, обсяги, структура тому, що збирають конкуренти. Ще краще подивитися публікації, які у нас зібрали дуже гарний трафік і зробити аналіз по них: який використовували заголовок, яка була структура, зображення тощо.
Тобто ми проводимо аналітику того, що в нас є, і з такими даними набагато легше працювати і потрапити в Google Discover, аніж з новими темами. Коли ми відпрацювали свої теми, то ми переходимо до варіанту А, і знову пішли по конкурентам, для того, щоб написати ще більше контенту за новими темами.
Важливо! Як працювати с заголовками:
- зібрати сторінки по Search Console, закинути в Screaming frog, спарсити заголовки. І проаналізувати: які заголовки були ефективні, які ні, які дали добрий CTR, і які поганий;
- АБО: проаналізувати ці дані за допомогою якихось програм на Python. Я знаю, що деякі спеціалісти застосовують їх для аналізу трафіка з Google Discover. Це також має право на життя. Але не забувайте, що і ручний аналіз також має бути присутній.
Умови потрапляння контенту до Google Discover
Аби ваші новини потрапити до Google Discover, варто дотримуватися наступних умов:
- Умова 1. Відповідність вимогам до контенту від Google Discover. Є базові критерії: який контент може / не може бути присутнім, які мають бути заголовкитощо. Наприклад, якщо ви хочете писати медичний контент, то подивіться умови до контенту уGoogle Discover: такий різновид взагалі не представлений у Рекомендаціях.
- Умова 2. Написання контенту відповідно до аудиторії сайту. Стрічка Google Discover персоналізована під кожного користувача. Наприклад, ви бачите, що ваша аудиторія складається з жінок від 30 до 40 років. Якщо ви починаєте публікувати контент про технології (не зовсім пересікається з вашою аудиторією), то його покази будуть на порядок менші, бо він не в колі інтересів вашої аудиторії. І не потрапить до їх персоналізованої стрічки. Тому так важливо дослідити аудиторію сайту і обрати відповідні теми. Під названу аудиторію жінок 30-40 років дуже гарно буде відпрацьовувати теми, наприклад, рецептів, гороскопів, кухонних лайфхаків тощо. Це дещо стереотипно, але суть така: шукайте теми, цікаві вашій аудиторії.
- Умова 3. Ваш контент має отримувати трафік, для того щоб надати Google Discover сигнали якості та зацікавленості. Тобто ваш трафік реферальний, соціальний, органічний (хоча й слабше), новинний (з Google News) — усе це може пушити ваш трафік в Google Discover. Тобто при публікації контент має набрати необхідну кількість сигналів від читачів та передати ці сигнали до алгоритмів Google Discover. Тому думайте, яким чином ви можете стимулювати ваші сторінки, яким трафіком, для того щоб потенційно попадати в Рекомендації.
Кейси
Нижче на скріні бачимо приклад, який відображає все зазначене раніше.
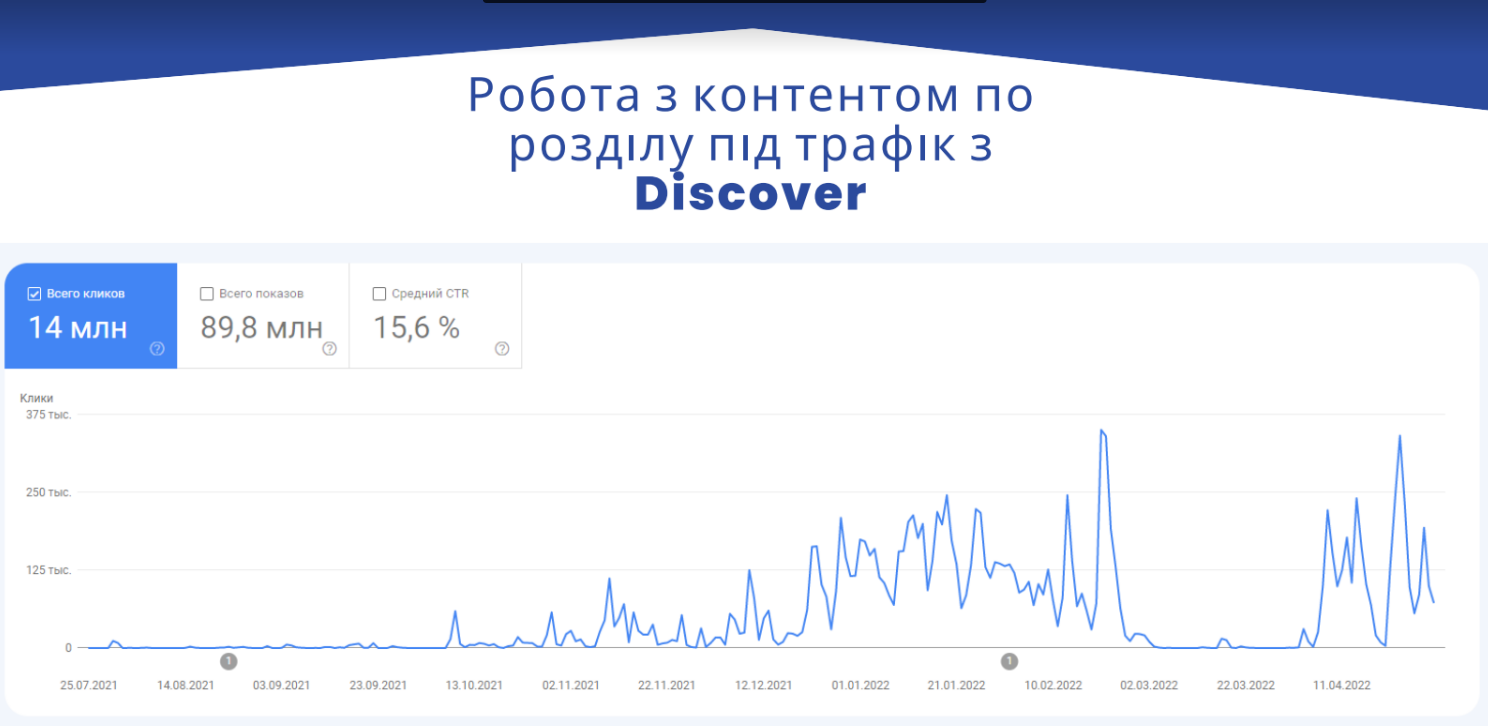
Це кейс по одному розділу сайту «Обозреватель». Представлено великий період для того, щоб показати як ми починали працювати з цим розділом. Як ви бачите, трафік стрибкоподібний — це нормально для Google Discover. Але для розділу вцілому є результати: близько 300-350 тисяч кліків в день. Цей період — початок війни. Було 2 проблеми: а) нас постійно ДДОСили і б) саме цей розділ став неактуальний в стрічці Google Discover, але потім вже повернувся. Життя потрохи повертається в своє русло.
Чи потрібні AMP-сторінки та чи потрібно прокачувати E-A-T?
Одне з питань, яке часто постає перед спеціалістами, які працюють саме з Google Discover — чи потрібні AMP-сторінки? Якщо коротко, то так:
- Discover — ні!
- Discover AMP-stories — так.
- Google News — так.
- TOP-Stories — так.
Детальніше — дивіться у відео👆😉
Щодо E-A-T для Google Discover.
Для Google Discover так само, як і для Google News, дуже важливим параметром є свіжість публікації. Якщо в органіці публікація може бути розміщена місяць-два-три тому, то в стрічці Google Discover ви такого не побачите. Там буде представлений контент, якому максимум 6-7 діб, а мінімум там може бути контент вже через годину. І саме для того, щоб Google міг розуміти, чи є експертним сайт, і чи можна брати його контент в Google Discover, вам необхідно прокачувати експертність по обраній тематиці. Але є трошки тут “але”.
Питання — Відповідь
Яким чином через GA ви бачите трафік із Google Discover?
— В GA трафік з Discover розподіляється між direct, google (organic), googleapis.com. Щодо абсолютних чисел, то найбільша частка припадає саме в direct. Це можна перевірити, порівнявши трафік з GA з трафіком по GSC в розділі «Рекомендації» (Discover).
Чи помічали ви, що коли у вас падіння трафіку на FB, то в той же час і падає трафік в Discover?
— Так, про це я розповідав у доповіді, трафік з фейсбуку (і не тільки) дає пуш для Discover💪
Чи впливають соцмережі на потрапляння до стрічки Discover?
— Так, трафік який надходить на сторінку, надає пошуковій системі сигнали для потрапляння в Discover 📈
Чи впливає на «взліт» внутрішнє перелінкування на потрібну статтю?
— Так, внутрішній трафік також працює.
Хіба трафік з Discover — це не referral-googleapis.com (в GA)?
— Так вірно❗️ В GA трафік з Діскавер розподіляється між direct, google (organic), googleapis.com. Щодо абсолютних чисел, то найбільша частка попадає саме в direct, доля googleapis.com найменша.
Скількі беклінків можна робити під статею для перелінковки?
— Не впевнений, що питання було до мене 😁 Тут є важлива метрика: ви можете поставити скільки хочете внутрішніх беклінків, але не більше, ніж це доцільно. Просто тоді можна поставити 20 штук за раз, та все одно на вигляд — головне результат) Є сторінки, на яких 20 беків будуть коректні. Наприклад сторінки-хроніки, де ви узагальнюєте новини по темі, або за період. І поставити на таких сторінках 20 беклінків буде органічно і в них будуть внутрішні переходи
Чи можна згодом їх видалити, та зробити нові?
Авжеж можна, питання ефективності цієї дії буде залежити від факторів, про які розповідав Артем у першій доповіді, в тому числі чи будут потенційні переходи по цім беклінкам.
Чи впливає 301 редирект на потрапляння до Discover? Чи є шанс у такої сторінки?
— Ми проводили експерименти зі старим контентом, змінюючи його різним чином і публікуючи повторно. По результатам, або сторінки набирали ще 10-15% від первинного трафіку або взагалі не приносили, якщо вік сторінки був суттєвим (наприклад минулий рік). По 301-м редиректам експеримент не проводили, але дякую за ідею — думаю що протестуємо:)
Дякуємо Олександру за змістовну та структуровану доповідь! Залишилися питання — пишіть в коментарях👇