Чи можна довіряти цифрам? Здавалось би, точнішого показника годі й придумати. Однак це питання так чи інакше постає щоразу, коли аналітики демонструють клієнтам звіти, в яких SEO-дані з різних джерел не збігаються.
Тож чому важливі метрики популярних SEO-інструментів показують розбіжності? І головне — якис сервісам можна довіряти при прийнятті стратегічних рішень у сфері пошукової оптимізації? Нумо розбиратись!
Деталі — у відео доповіді Владислава Трішкіна з конференції Collaborator 11.10.2024👈
Мета й методологія дослідження точності SEO-сервісів

Дослідження маркетингової агенції Promodo почалось саме завдяки незручним, але логічним питанням клієнтів. Отож, щоб озброїтись на майбутнє аргументованими відповідями щодо точності SEO-сервісів, Владислав Трішкін та його команда поставили перед собою завдання:
- Дослідити рівень похибки популярних SEO-тулів: SEMrush vs SimilarWeb vs Ahrefs.
- Зібрати доказову базу та аналітичні дані на основі вибірки сайтів для виявлення закономірностей в розбіжностях.
- Зробити висновки, які допоможуть SEO-спеціалістам ефективніше пояснювати результати клієнтам і будувати стратегії на основі реальних даних.
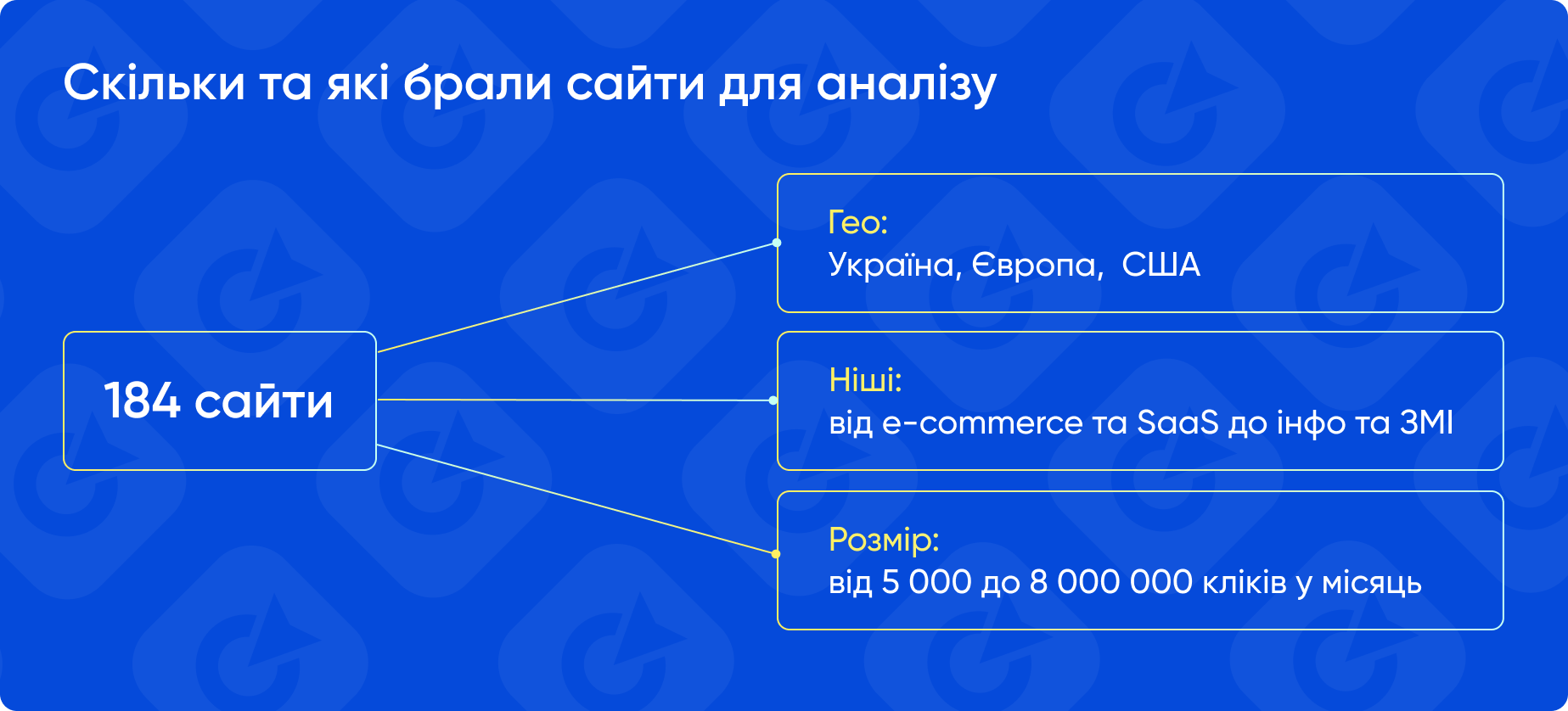
Щоб отримати максимально об'єктивну та повну картину, для аналізу взяли вибірку зі 184 сайтів із різних гео, ніш та різним об'ємом трафіку:
Аналізували дані за перше півріччя 2024 року із таких джерел:
- Google Search Console — як референс для фактичних показників;
- Ahrefs, SimilarWeb, SEMrush — для порівняння «синтетичних» даних, які вони розраховують.
Під час дослідження SEO-сервісів вдалось виявити рівень похибки — наскільки відрізняються показники цих сервісів від даних GSC. А крім того ще й знайшли цікаві закономірності та аномалії, наприклад, сервіси, які систематично завищують або занижують показники.
Попри те, що методологія звучить просто, за цим стоїть величезна кількість даних, які потребували глибокого аналізу. Вивчали навіть дрібні аномалії, щоб отримати максимально точні результати. Це дозволило не лише визначити середньостатистичну похибку, але й зрозуміти, які особливості є в кожного сервісу.
Отримані результати допомагають оцінити надійність метрик, які ви використовуєте, і краще зрозуміти обмеження аналітичних інструментів. Це знання стане в пригоді кожному SEO-фахівцю, який хоче уникати помилок і покращувати якість своїх стратегій.
Особливості розрахунку трафіку SEMrush, SimilarWeb та Ahrefs
Кожен SEO-сервіс має свою унікальну систему розрахунку трафіку, що відображається на точності даних. Далі розберемось, як SEMrush, SimilarWeb і Ahrefs оцінюють трафік сайтів, дослідимо їхні підходи, переваги та слабкі сторони.
SEMrush: як аналізує дані про трафік

SEMrush для аналітики та оцінки трафіку використовує петабайти даних про кліки, отримані з багатьох сторонніх джерел, хоча конкретні ресурси не розкриваються.
Органічний трафік оцінюється через аналіз позицій ключових слів із застосуванням моделі прогнозування, де CTR множиться на обсяг пошуку за певним запитом. Такий підхід забезпечує хорошу оцінку органічного трафіку для середніх і великих сайтів, але для ресурсів із невеликим трафіком (<5000 кліків/місяць) точність суттєво знижується. Також цей сервіс надає лише оцінкові дані, а не фактичні, що передбачає певну похибку.
SimilarWeb: як працює система розрахунку трафіку

SimilarWeb використовує чотири основні джерела даних: прямі вимірювання (інформація від сайтів, які надали доступ до власних систем внутрішнього трекінгу), інформацію про поведінку користувачів через Contributory Network, цифрові сигнали від партнерських організацій, а також дані, зібрані з величезної кількості вебсайтів за допомогою алгоритмічного продукту Public Data Extraction.
Суттєва перевага SimilarWeb — детальна інформація про усі канали трафіку, включаючи органічний, PPC та реферальний. Надаються детальні звіти у зручному форматі з можливістю порівняння конкурентів.
Після глобального оновлення системи трекінгу в кінці липня 2024 року точність аналізу покращилася. Були підключені додаткові параметри для врахування не тільки фактичних змін, а й сезонних змін трафіку, а також додали інформацію, яка покращила їх розуміння трафіку саме з мобільних девайсів.
Проте оцінка даних для сайтів із малим трафіком залишається неточною, оскільки сервіс залежить від великого обсягу даних, отриманих із вищезазначених джерел.
Ahrefs: як обчислюються показники трафіку

Система Ahrefs базується на пошукових запитах, їхній кількості (тобто попиті) та власних «унікальних розрахунках» CTR. Дані сервісу доволі точні, однак лише для сайтів зі стабільними позиціями. Якщо зміни у SERP відбуваються швидко, а дані бот Ahrefs ще не оновив, система показує не актуальні дані по трафіку. Крім того, цей сервіс не надає підсумкової оцінки місячного трафіку, що може ускладнювати аналіз у тривалому часовому періоді.
Простими словами: в Ahrefs використовують систему вимірювання, коли кожного дня показується приблизний місячний трафік, виходячи із поточних бачень позицій, CTR і пошукових запитів. А це означає — багато нюансів і моментів, де саме може виникнути похибка даних.
Результати дослідження точності SEO-сервісів: середній відсоток похибки
Проаналізувавши кожен сервіс, тобто величезні масиви даних, вдалось отримати розрахований середній відсоток похибки. Далі — детально по кожному сервісу.
SEMrush продемонстрував середню похибку на рівні 61,58%, причому частіше сервіс завищував трафік (у 112 зі 184 сайтів). Зустрічались і певні аномалії: у деяких випадках SEMrush міг оцінити трафік у 130 тис., коли реальний обсяг становив 50 тис. Водночас траплялися мінімальні відхилення, близькі до фактичних значень.

У SimilarWeb відсоток похибки менший — 56,95%. Кращі результати, імовірно, пов’язані з оновленням системи в липні 2024 року. До цього моменту рівень похибки був значно вищим, після — показники стали ближчими до реальних, хоча сервіс і далі має схильність до завищення даних.

SimilarWeb частіше, ніж SEMrush та Ahrefs, демонстрував результати із мінімальною похибкою, наближеними до фактичного трафіку. Аномалії понад 100% також зустрічалися, але завдяки загальній тенденції до покращення можна очікувати, що точність надалі зростатиме.
Ahrefs зайняв перше місце по точності та найкращий відсоток похибки — 48,63%. У більшості випадків цей сервіс демонстрував показники, ближчі до реальних, але з тенденцією до заниження трафіку. Аномальні похибки були практично відсутні, але випадків із мінімальними відхиленнями теж майже не спостерігалося.

Середній рівень похибки для досліджуваних інструментів складає близько 50%. Однак у процесі дослідження точності SEO-сервісів були виявлені аномальні випадки, коли результати суттєво відрізнялися від реальних. Такі розбіжності не залежали від ніші чи розміру сайтів, що свідчить про обмеження методологій кожного сервісу.
Ці результати підтверджують необхідність перевірки даних у кількох сервісах одночасно, щоб мінімізувати ймовірність суттєвих похибок. Крім того, важливо розуміти, що точність оцінок залежить від таких факторів, як CTR, що є дуже динамічними даними, зміни в пошукових позиціях, а також від здатності сервісів оперативно оновлювати свої дані.
Як самостійно розрахувати трафік: покроковий гайд
Такі розрахунки можна зробити власноруч. Звісно, вони також матимуть певну похибку, однак важлива перевага цього методу — вам не будуть потрібні спеціалізовані сервіси.
Для того, щоб провести розрахунок трафіку, знадобиться наступна інформація:
- максимально повне семантичне ядро;
- CTR для топ 10;
- зріз по позиціях та частотності.
Для початку зберіть усі релевантні запити — високо-, середньо- та низькочастотні — по сторінці, категорії, сайту, які хочете аналізувати. Зріз позицій та частотності дозволить оцінити видимість сайту за обраними ключами.
Щоб визначити CTR, найпростіше — використати середні показники з сервісів на кшталт Advanced Web Ranking. Він показує поточні актуальні тенденції по CTR, але похибка даних буде велика через різницю у видачах залежно від ніш, гео та наявності різних блоків у SERP (People Also Ask, Local Pac, Images, блоку розширеної видачі).
Другий варіант — зібрати дані з Google Search Console. Відфільтруйте запити за категоріями, виключивши брендові. Розрахуйте середній CTR для кожної позиції (ідеально — від 1 до 10). Ви отримаєте дані, які базуються на історії вашого сайту.

Далі переходимо до підрахунку трафіку:
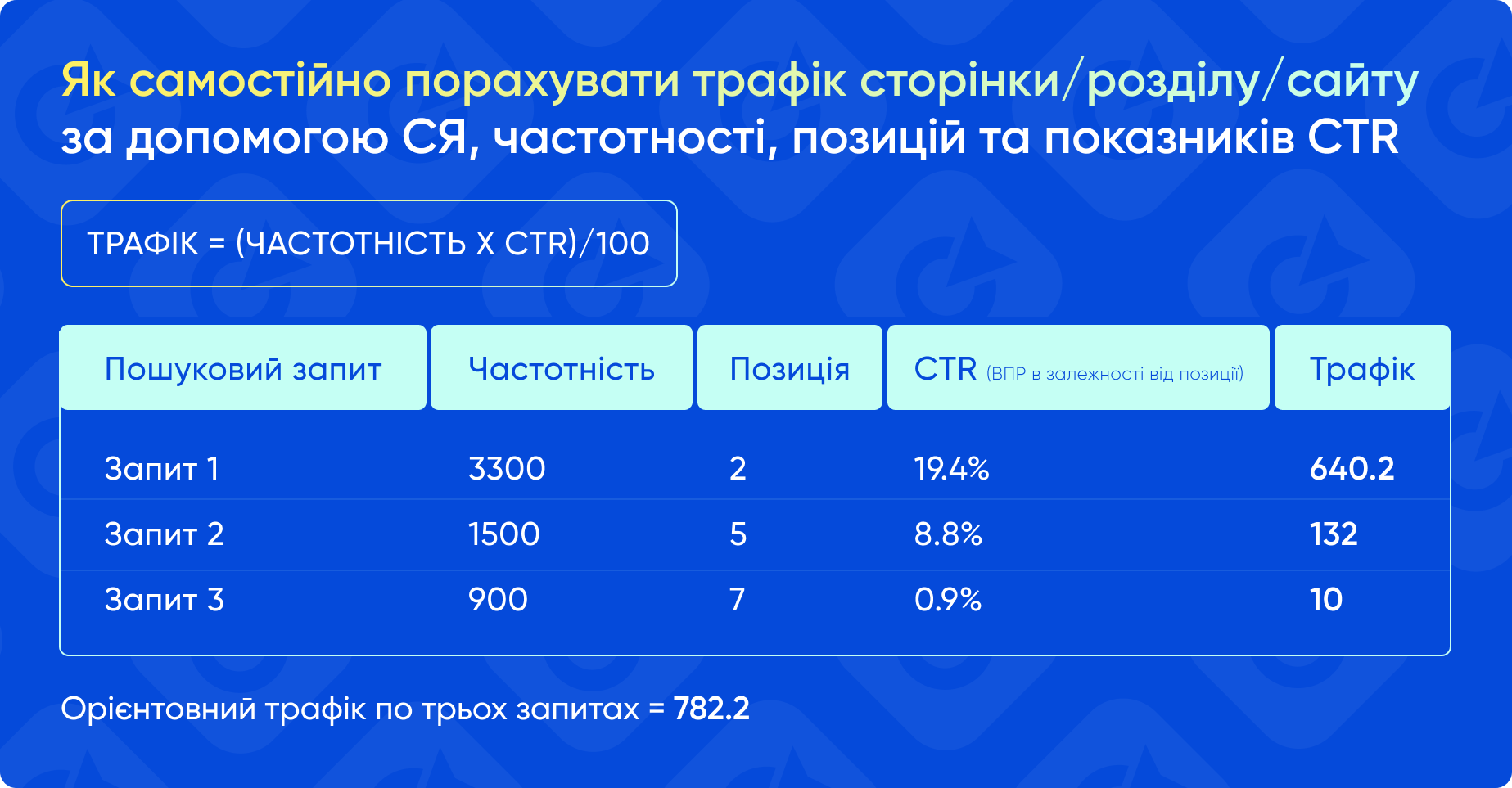
- Створіть таблицю з такими даними: запит, частотність, поточна позиція, CTR для цієї позиції.
- Формула розрахунку: Трафік = (Частотність × CTR) ÷ 100
- Підсумуйте результати для всіх запитів, щоб отримати орієнтовний загальний обсяг можливого трафіку в місяць.
Метод ефективний для аналізу окремих сторінок чи категорій, однак для масштабних проєктів (весь сайт чи аналіз конкурента) він займе чимало часу та ресурсних витрат.
Ключові висновки
Від зовнішніх сервісів не треба вимагати максимальної точності. Вони будуть мати певну похибку при перерахуванні обсягів органіки, тому що є моменти, де реально неможливо у real-time відстежувати, і саме вони дуже часто викликають цю похибку. Тому при будуванні SEO-стратегії, при аналізі конкурентів враховуйте, що ці дані зовнішніх сервісів орієнтовні, а не фактичні.
Якщо у вас є можливість, пробуйте самі робити прорахунок трафіку для сторінки або пулу сторінок, які вам цікаві.
Питання-Відповідь
Чому показники Ahrefs (Linked websites) не збігаються з даними їхнього безплатного інструмента — чекера лінків?
Це питання варто адресувати до служби підтримки Ahrefs. З мого досвіду, такі сервіси зазвичай не розкривають деталей про те, як саме вони збирають і обробляють дані. Через це подібні запити часто залишаються без конкретної відповіді.
Якими сервісами ви користуєтесь для аналізу взаємодії з брендом конкурентів у соціальних мережах за певний період?
Я спеціалізуюсь на SEO і не працюю безпосередньо із соціальними мережами. Однак для аналізу кросканальної взаємодії, наприклад, SEO і PPC, можу порадити деякі підходи.
Одним із поширених прикладів є так звана «канібалізація PPC», коли налаштування платної реклами починають відбирати частину органічного трафіку — як у категоріях, так і на рівні брендових запитів.
Для аналізу таких взаємодій використовую Similarweb.
Якому показнику в цьому аналізі можна довіряти найбільше? Чи оптимально — вивести середнє значення у сервісах?
Наприклад, Ahrefs показує 86,3 тис., Semrush — 133,7 тис., а Similarweb — 3,6 млн. При цьому показник Similarweb, швидше за все, є результатом аномалії. Цей інструмент іноді дає надто високі значення через особливості збору даних.
У такому випадку я б більше довіряв Ahrefs: хоч він часто занижує оцінки трафіку, його підрахунки базуються на фактичних даних: ключові слова, їхня частотність, CTR — усе це враховується для розрахунку.
Реальні цифри, на мою думку, десь посередині між показниками Ahrefs vs Semrush — близько 110 тис.
Чи залежав показник похибки від ніші або географії? Чи Ahrefs однаково точний у всіх випадках?
Ahrefs показує стабільно точні результати незалежно від ніші чи географії. Ми аналізували різні ніші, порівнювали показники для різних сайтів — у всіх випадках Ahrefs був кращий. Його методика оцінювання працює консервативно: похибка даних зазвичай становить 30–50% у менший бік, без різких відхилень.
Similarweb іноді дає чудові результати з мінімальною похибкою, залежність від ніші чи інших факторів виявити також не вдалося.
Потенціал більший у Similarweb та SEMrush, де працює кастомна модель прорахування, але поки що модель Ahrefs краще працює.
На яку кількість ключових слів у топ 10 і топ 3 розраховуєте при оцінці потенційного трафіку?
Звичайно, ми беремо максимально повне ядро. Якщо розраховуємо потенційний трафік на певний проміжок часу, то для детальної аналітики потрібна максимальна кількість пошукових запитів.
Які результати у Serpstat та SE Ranking?
Про SE Ranking не можу дати обґрунтовану оцінку. А от Serpstat, вважаю, є на одному рівні з Ahrefs. У деяких випадках база запитів навіть виграє. Очікую від Serpstat таку ж похибку, як і в Ahrefs.
Дякуємо Владиславу за цікаве дослідження та практичну доповідь. В Академії Collaborator можете переглянути усі доповіді запрошених спікерів з осінньої конференції.
А ще запрошуємо брати участь у безкоштовних вебінарах. Ознайомитись з розкладом івентів та зареєструватись можна за посиланням👈